
기보 16만 개를 달달 외웠으니 이길 수밖에 없겠다고? 바둑은 기보를 외운다고 할 수 있는 게임이 아니라니깐! 그럼 기억력 좋은 사람이 무조건 바둑에서 이기게? 내 진짜 실력은 기보에 나온 고수들의 방법을 스스로 공부하고 이길 수 있는 수를 열심히 계산한 데서 나와. 그게 바로 ‘딥러닝’이라고!
고양이의 특징, 인공신경망으로 배워요
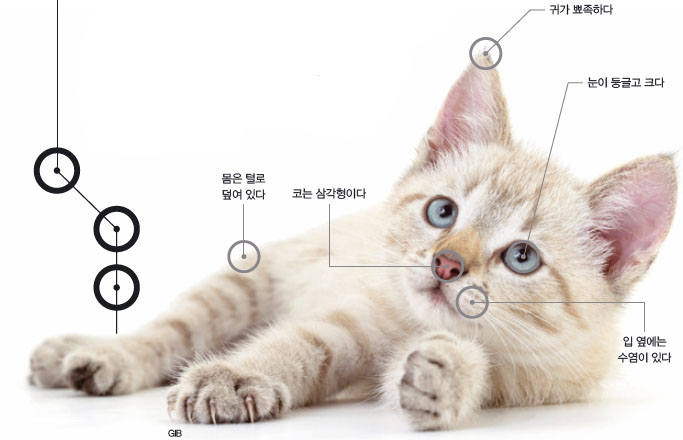
어린 아이에게 고양이를 보여 주면서 ‘고양이’라고 알려 주면, 그 다음부터 고양이를 구별할 수 있어요. 털이나 수염 등 고양이의 특징을 종합해서 기억하기 때문이에요.
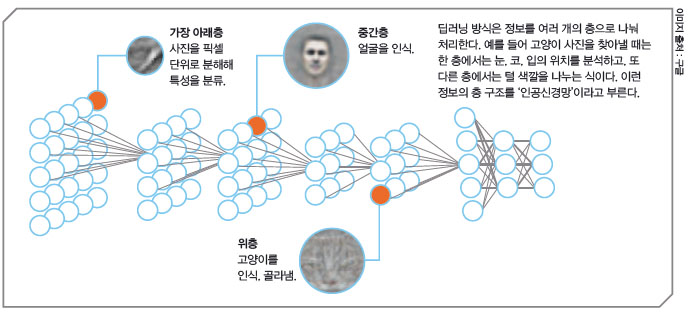
그럼 기계가 고양이를 구분하게 만들려면 어떻게 하면 될까요? 실제로 구글은 2012년 딥러닝 방식으로 인공지능을 학습시켜 고양이 사진을 구분해낼 수 있게 했어요. 먼저 고양이에 대한 정보가 없는 인공지능에 약 1000만 장의 영상을 입력했어요. 컴퓨터는 이 사진을 작은 픽셀 단위로 분석해요. 그 다음에는 사진에 나온 물체의 형태를 찾고, 영상 속에 나오는 고양이의 얼굴을 이루는 특징들을 컴퓨터가 알아서 하나하나 분류해 가요.
이렇게 분류한 정보들 중 고양이라는 답과 연관되는 정보들은 중요해져요. 답과 정보 사이의 연결이 강해지는 거지요. 예를 들어 ‘귀 끝이 뾰족하다’는 정보가 고양이라는 답으로 연결될 경우, 컴퓨터는 두 정보를 특히 강하게 연관지어 저장해 둬요. 그리고 다음번에 귀 끝이 뾰족한 동물의 사진을 받으면 고양이일 확률이 높다고 판단하는 거예요. 컴퓨터가 이런 식으로 계속 학습한 결과, 약 75%의 정확도로 고양이 사진을 가려낼 수 있었답니다.
딥러닝으로 배우면 이야기도 척척~!
딥러닝은 ‘창의력’이 필요한 일에서도 힘을 발휘해요. 서울대학교 컴퓨터공학부 장병탁 교수 연구팀은 인공지능이 이야기를 스스로 추론하는 ‘상상력 기계’를 연구하고 있어요.
연구팀은 딥러닝 알고리즘을 설계한 다음, 이 프로그램에게 애니메이션 ‘뽀로로’ 시리즈를 모두 보여 줬어요. 프로그램은 뽀로로에 나오는 단어들과 캐릭터, 장면, 배경 등을 각 층별로 따로 학습한 뒤 서로 관련 있는 것끼리 묶어가며 정보를 계속 얻어갔지요. 예를 들어 ‘뽀로로’란 단어와 ‘안경 쓴 펭귄’ 캐릭터가 서로 같이 나오는 확률이 매우 높을 경우, ‘안경 쓴 펭귄’이 등장하면 주변 인물이 뽀로로라는 이름을 말하게 하는 거죠.
연구팀은 중요도가 떨어지거나, 이야기에 방해가 되는 정보는 상상력 기계 스스로가 없애는 방식으로 필요한 정보만 모을 수 있게 했어요. 이런 방법을 통해 상상력 기계는 장면만 보여 줘도 맞는 자막을 스스로 만들어내는 능력을 갖게 됐답니다. 장 교수는 “어린아이가 성장하는 것처럼, 아무것도 모르던 상태에서 스스로 배우고 성장하는 인공지능을 만드는 것이 목표”라고 밝혔어요.

그럼 알파고의 딥러닝은 어떻게 이루어졌을까요? 알파고는 기보를 보고 다음 수를 예측하는 과제부터 시작했어요. 인간이 둔 다음 수를 정확히 예측하면 ‘성공’, 틀리게 두면 ‘실패’지요. 그럼 성공한 수가 더 중요한 정보로 남아요. 알파고는 이런 식으로 기보 16만 건을 학습한 뒤에 마치 사람처럼 바둑을 둘 수가 있게 됐어요.
그런데 기보만 학습할 경우, 기보에 자주 나오는 ‘묘수’만 정답이라고 인식할 위험이 있어요. 그래서 구글 딥마인드는 알파고가 자기 자신과 대결하게 만들었어요. 먼저 알파고를 알파고1과 알파고2로 나눈 다음, 각각 정보의 중요도를 조절해 주었어요. 예를 들어 알파고1은 공격을 중요하게 생각하고, 알파고2는 방어를 중요하게 생각한다고 해요. 둘의 대결 끝에 알파고1이 이겼다면, 알파고는 공격 전략을 더 중요히 여기게 되지요.
이번에는 알파고1과 알파고3이 다시 대국해요. 알파고3은 방어하는 척하다가 공격하는 전략을 써서 알파고1을 이겨요. 그 결과 알파고는 ‘초반은 방어하는 게 좋다’는 정보를 새롭게 배우게 돼요. 이런 식으로 알파고는 점점 세밀한 전략을 세워갔답니다.
알파고는 자기 자신과 대국해서 얻은 3000만 건의 수를 이용해 대국 중 승률을 계산하는 방법을 배웠어요. 또 바둑판에서 벌어지는 모든 경우의 수를 계산하기는 어렵기 때문에, 이길 확률이 높은 수만 놓는 방법도 사용했지요. 이렇게 5주간 학습한 결과, 알파고는 여러 바둑 프로그램들과의 대결에서 495전 494승이라는 놀라운 결과를 거뒀답니다.


알파고는 모르는 수를 만나면 멘붕?
판후이 2단, 이세돌 9단과의 대국에서 알파고는 앞에서 배운 내용을 복합적으로 이용했어요. 먼저 알파고는 자신의 차례가 왔을 때 두면 승률이 높을 위치들을 찾아내요. 여기서 1차적으로 몇 가지 경우의 수가 나오지요. 그 다음은 각 위치에 돌을 놓을 경우 자신이 몇 %의 확률로 이길지 계산해요. 그리고 계산 결과가 높은 것들을 골라 자신과 상대가 25~30번 돌을 주고받은 후에 어떤 그림이 펼쳐질지 미리 예상해요. 이런 과정을 거쳐 최종적으로 가장 좋은 위치를 찾아내고 그 다음 상대의 수와 자신의 대응까지 예상하지요.
그런데 알파고에게도 약점이 있어요. 지금껏 학습하지 않았던 독특한 수를 만나면 ‘멘붕’에 빠지게 돼요. 실제로 이번에 치러진 네 번째 대국에서 이세돌 9단이 중앙에 놓은 78수 이후 알파고는 초보적인 실수를 반복했어요. 4~5번 연속으로 이상한 수를 두고 나서야 자신의 승률을 제대로 계산하고, 상대의 반응에 대처할 수 있었지요.
사람이라면 곧바로 자신의 실수를 깨닫고 반응했겠지만, 알파고는 계속 자신이 두는 수가 가장 이길 확률이 높은 수라고 인식하기 때문에 그러지 못했어요. 결국 알파고는 첫 패배 선언을 하고 말았답니다.












