가짜뉴스가 어떤 식으로 퍼지는지 알았으니 이제는 가짜뉴스를 잡으러 가보자!
꽁꽁 숨은 가짜뉴스 녀석을 잡으려면 가짜뉴스와 진짜 뉴스의 특징이 어떻게 다른지 알아야 해.
뉴스는 ‘헤드라인’이라고 불리는 제목과 본문으로 이뤄져 있습니다. 가짜뉴스는 클릭 수를 늘리기 위해 낚시성 제목을 쓰는 경우가 많습니다. 제목과 관련된 내용을 기대했던 사람들은 혼란을 겪게 되죠. 특히 뉴스가 활발하게 유통되는 SNS에서 제목 위주로 기사가 유포되곤 해서 문제입니다.
지난 3월, 박건우 숭실대학교 AI융합학부 교수팀은 이러한 가짜뉴스의 특성에 기반해 본문과 다른 내용을 제목에 나타내는 가짜 뉴스를 판별하는 인공지능(AI)을 개발해 국제학술지 ‘국제전기전자공학회(IEEE) 엑세스(Access)’에 발표했습니다. 틀린 정보를 담고 있는 기사나 품질이 낮은 기사를 사람이 일일이 손으로 판단하려면 시간이 오래 걸립니다. 전문가를 고용하는 데는 비용도 많이 들죠. 성능 높은 딥러닝 모델을 만들면 많은 데이터 한 번에 처리할 수 있어서 효율적입니다.
박 교수는 기사의 계층적 구조에 집중했습니다. 기사 본문은 여러 개의 문단으로 이뤄져 있고 문단별로 단어들이 연속해서 나타납니다. 이 단어들을 벡터로 수치화해서 제목과 문단 사이, 문단과 문단 사이의 유사성을 판단했죠.
예를 들어 ‘질병’이라는 단어의 벡터값이 [0.55, 0.45, 0.3]이면 ‘질환’이라는 단어의 벡터값은 [0.5, 0.43, 0.2]로 서로 유사합니다. 그런데 초콜릿이라는 단어는 [0.2, 0.1, 0.7]처럼 전혀 다른 값을 가집니다. 각 벡터 사이의 유사도를 따지면 문단별로 비슷한 내용을 담고 있는지를 파악할 수 있죠. 이때 뉴스 기사를 현상을 그래프로 나타내 수학적으로 연구하는 그래프 이론을 사용해 표현했습니다.
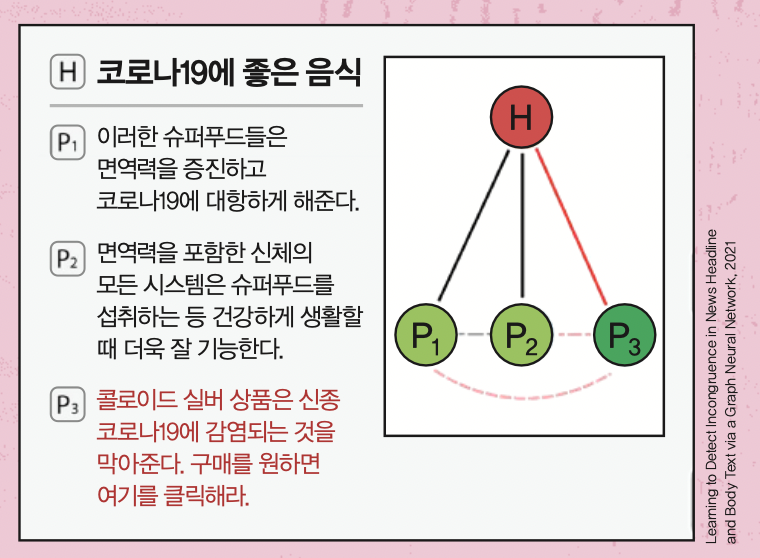
위 그림처럼 연구팀은 기사의 제목과 본문을 그래프로 나타냈습니다. 내용을 보면 P1과 P2는 ‘코로나19에 좋은 음식’이라는 제목과 어느 정도 관련이 있습니다. 그런데 P3에는 뜬금없이 광고 문구가 나옵니다. 뉴스 형태를 한 광고, 즉 가짜뉴스입니다.
이 과정을 AI로 처리하기 위해 우선 단어별 벡터값을 모아 제목과 각 문단의 대표 벡터값을 구했습니다. 그리고 이 값을 ‘노드’라는 점으로 표현했습니다. 그런 다음 뉴스 기사의 계층적 구조에 기반해 제목 노드와 본문 노드 간의 관계를 ‘링크’라고 부르는 선으로 연결해 그래프를 만들었죠.
AI는 한 노드와 링크로 연결된 이웃한 노드 사이의 가중치를 계산합니다. 이런 식으로 딥러닝이 연산을 거치면서 전체 기사의 ‘불일치 정도’를 계산합니다. 이 값이 1에 가까울수록 가짜뉴스일 확률이 높습니다.
박 교수는 이번 연구 외에도 “가짜뉴스의 진위 여부를 판별하거나 가짜뉴스의 패턴을 분석하는 등 전 세계적으로 가짜뉴스 문제를 해결하기 위한 AI 기술이 활발하게 연구되고 있다”고 말했습니다.