
OpenAI가 2023년 GPT-4를 출시할거란 예측과 함께 GPT 시리즈가 이번에도 인공지능(AI)의 판도를 바꿀지에 대한 관심이 높아지고 있다. OpenAI는 일론 머스크와 샘 알트만이 공동 설립한 인공지능 연구소로 2020년 5월 ‘현존하는 최고의 자연어처리 AI’라고 평가받는 GPT-3를 개발했다. GPT 시리즈는 과거 하나의 일을 수행하고 그 성능만을 높이는 개별적 방식 벗어나 범용적인 성능을 높이는 방법으로 모든 일에 뛰어난 성과를 보여 AI 개발 역사를 새로 썼다.
관심에 불을 붙인 것은 GPT-3의 개량 버전인 GPT-4가 OpenAI 내부에서 진행한 ‘튜링 테스트’를 통과했다는 소문 때문이었다. 튜링 테스트는 1950년 AI의 아버지라 불리는 영국의 수학자이자 컴퓨터과학자, 앨런 튜링이 고안한 것으로 질문을 던져 상대의 답변을 끌어내 이 상대가 인간인지 기계인지 판단하는 방법으로 기계의 능력을 평가한다. 기계가 얼마나 인간다운 대답을 내놓는지가 이 테스트의 핵심이다.
GPT-3도 뛰어난 품질로 사람과 기계를 구분할 수 없는 대답을 내놓을 수 있음에도 GPT-4에 관심이 커지는 것은 질문의 층위를 높여 튜링 테스트를 진행할 수 있기 때문이다. 일상생활에서 나누는 대화 뿐만 아니라 사실관계를 따지는 전문적인 대화, 윤리적도덕적인 가치 판단을 담보하는 대화 등이 그것이다. OpenAI 측에서 튜링 테스트에 기반한 내부 모델 평가 방식을 공식적으로 제시하지는 않았지만, 만약 소문대로 GPT-4가 OpenAI의 내부 튜링 테스트를 통과했다면 GPT-3보다 더 다양한 층위의 질문에서 능숙한 대답을 내놓았다고 추측해볼 수 있다. 즉 AI가 한층 더 인간같아 졌음을 뜻한다.
어떻게 AI가 더 인간다워질 수 있을까. 초거대 언어모델의 발전 양상과 최근 AI 연구 동향을 바탕으로 GPT-4가 인간에 가까워지기 위해 선택했을지 모르는 가능성에 대해 살펴봤다.

가능성 ❶ 매개변수
매개변수가 늘어나 모델이 더 커질 것이다
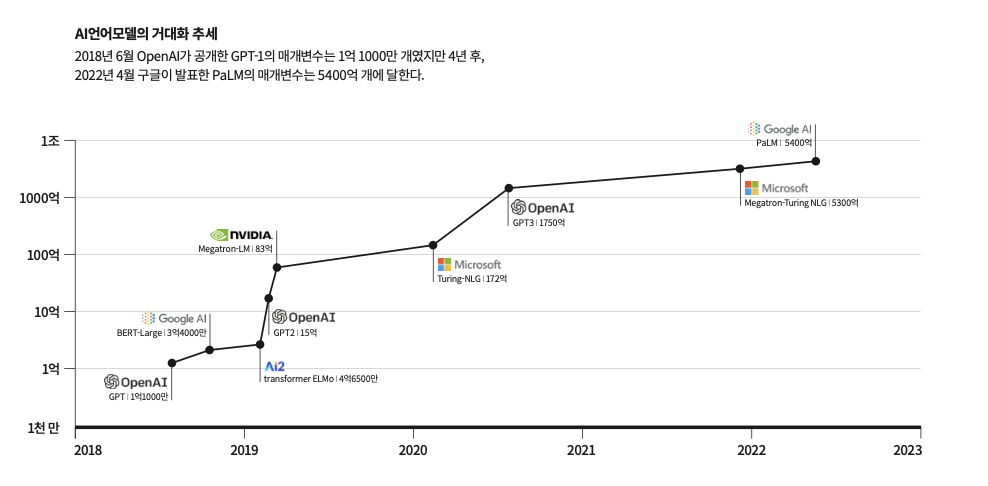
GPT-4는 GPT-3보다 더 커질 거란 추측이 있다. AI모델의 크기는 폭과 깊이로 측정하는데 이때 폭이 ‘매개변수(파라미터)’의 개수고 깊이는 ‘레이어’의 개수다.
딥러닝 모델은 복잡한 함수 식이다. 입력이 주어졌을 때 출력을 만드는 일련의 연산인 것이다. 매개변수는 이 복잡한 식을 구성하는 연산을 만드는 값이다. 입력 x에 a를 곱하는 연산과 b를 더하는 연산이 한 번씩 수행되는 ‘y=ax+b’ 식에서 매개변수는 a와 b다. 매개변수가 많을 수록 AI모델은 학습 데이터에서 더 많은 정보를 받아들일 수 있다. 한편 레이어는 AI모델이 수많은 매개변수를 처리하는 알고리즘 단계다. 입력 데이터에서 출력 데이터가 만들어지기까지, 매개변수들이 통과하는 계산 단계를 의미한다.
지금까지의 초거대 언어모델들은 레이어를 대략 100개 수준으로 비슷하게 유지하면서 매개변수의 개수를 늘리는 방향으로 성능을 높여왔다. 특히 OpenAI는 GPT-3에서 1750억 개의 매개변수를 사용하면서, 매개변수의 크기를 키우는 것만으로도 AI의 성능을 높일 수 있다는 것을 증명했다. 이 때문에 GPT-4도 매개변수를 늘려 더 큰 AI모델이 될 수 있다는 추측이 나온다. GPT-4가 억 단위를 넘어 1조 혹은 100조 개 매개변수를 가질 수 있다는 주장도 있다. 2022년 4월에 구글 딥마인드가 공개한 언어모델, PaLM은 무려 5400억 개 매개변수를 갖는다.
AI모델이 커지면 커질수록 좋은 성능을 내는 이유는 명확하게 밝혀지지 않았다. 서민준 카이스트 김재철AI대학원 교수는 “매개변수가 늘어날수록 복잡한 현상을 함수화할 수 있기 때문”이라고 그 이유를 추측한다. y=ax+b와 같이 매개변수 개수가 적은 식은 직선밖에 표현하지 못해 단순한 현상만 나타낼 수 있다. 반면 연산의 개수가 많아지면 우리가 표현할 수 있는 함수의 복잡성이 증가한다.
복잡성의 함수화가 가능해지면 AI의 일반화 능력이 크게 증가한다. 대개 하나를 가르치면 열을 아는 것을 똑똑하다고 말하는데 바로 이것이 일반화 능력이다. 매개변수가 늘어날수록 배운 적 없는 입력 데이터에 대해도 AI가 적절한 대답을 내놓는 것이다.
하지만 최근 AI연구와 개발은 ‘클수록 좋다’는 단순한 신조에서 벗어나고 있다. 특히 구글은 매개변수를 늘리는 것만이 능사는 아니라며 양질의 데이터를 충분히 학습해야만 초거대 언어모델 성능이 향상된다는 것을 실험한 논문을 2022년에 발표한 바 있다. 따라서 GPT-4가 커질 수는 있더라도 100조와 같이 터무니없는 숫자는 아닐거라 예상할 수 있다.
가능성 ❷ 멀티모달
다양한 형태의 입력과 출력이 가능할 것이다
‘멀티모달’이란 모달리티가 여러 개란 뜻으로 다양한 양식의 출입력이 가능한 모델을 뜻한다. 텍스트나 이미지, 생체신호 등이 모달리티의 대표적인 예다. GPT시리즈는 텍스트만을 입력과 출력 양식으로 하는 단일 모달리티 언어모델이다.
GPT-4가 멀티모달 방식일 수 있다는 주장이 제기되는 건 멀티모달이야 말로 AI가 인간다워지는 방식이기 때문이다. 과학동아 독자들이 기사를 읽으면 글자와 함께 옆에 있는 사진과 그림도 동시에 살펴보며 기사를 이해한다. 하지만 아무리 성능이 좋은 언어모델이라 할지라도 단일 모달리티를 채택하기에 텍스트로 이루어진 입력만 받아들일 수 있다.
OpenAI는 현재 텍스트를 입력하면 이미지가 출력(text to image)되는 DALL-E 프로젝트로 멀티모달 AI를 연구하고 있다. 임준호 한국전자통신연구원(ETRI) 언어지능연구소 책임연구원은 “언젠가 멀티모달 방식의 거대 AI모델이 나오면 DALL-E에서 시도하지 못하는 형태의 일도 가능해질 수 있다”며 한 개의 그림을 보고 인간과 AI가 그림에 대한 평가를 주고받는 예를 들었다.
다만 당장 출시를 앞둔 GPT-4가 멀티모달을 채택할 가능성은 높지 않다. GPT 시리즈는 OpenAI의 언어모델로 텍스트를 기반으로 한 모델의 성능 향상에 초점을 맞추고 있기 때문이다. 서 교수는 “만약 OpenAI가 초거대 모델에 멀티모달 방식을 채택한다면 GPT 시리즈가 아닌 다른 이름으로 출시될 가능성이 높다”고 말하기도 했다.
가능성 ❸ RLHF
인간의 피드백을 활용해 더 인간다워 질것이다
GPT-3.5를 기반으로 출시된 챗GPT는 ‘RLHF(Reinforcement Learning from Human Feedback인간 피드백을 통한 강화학습)’ 방식이 적용돼 화제가 됐다. 강화학습은 기계 학습의 하나의 방식으로, 실수와 보상을 통해 최적의 선택을 배우는 방법이다.
RLHF는 강화학습의 한 방법으로 사람의 피드백을 활용한다. RLHF의 대표적인 예는 여러 개의 답변을 제시하고 그 중 가장 적절한 대답을 사람들이 선택하게 하는 것이다. 서 교수는 “RLHF가 AI모델의 성능을 향상시키는 데 큰 도움이 된다는 것은 현재 일반적으로 알려진 지식”이라고 설명했다.
실제 RLHF를 사용해 훈련된 챗GPT에게 오류가 난 코드를 보여주며 어떻게 고칠 수 있냐는 질문을 하면 “이것이 전체 코드인지 아니면 일부인지” 되묻는다. 사용자가 일부라고 답하면 “추가적인 정보(전체 코드 맥락) 없이 정확한 답을 하기 어렵다”면서도 “제시한 코드만 살펴봤을 때 어떤 문제가 보인다”고 답을 하는 등 수준 높은 성능을 자랑했다.
따라서 OpenAI가 이미 언어모델 성능 향상을 이뤄낸 RLHF가 GPT-3.5에 이어 GPT-4에서도 다시 채택될 가능성은 높다고 할 수 있다.
가능성 ❹ WebGPT
‘구글링’을 해 더 적절한 답을 찾을 것이다
GPT-4는 검색하는 AI일 수 있다는 주장도 있다. 이는 최근 AI는 매개변수에 의한 추정에만 기반하는(fully parametric) 방법론에서 벗어나 검색을 통해 더 정확한 답변을 내는(semi-parametric) 방법론을 연구하는 추세기 때문이다. 특히 OpenAI는 2021년 12월에 ‘웹 검색을 통해 언어모델의 사실 정확성을 개선할 수 있다’는 WebGPT의 프로토타입을 개발해 논문을 발표한 바 있다.
현재 검색하는 언어모델은 모델의 정확성과 신뢰도를 향상시키는 방안으로 꼽힌다. 검색과 함께 답변의 출처를 함께 표시하기 때문이다. 인간이 대화를 할 때도 ‘카더라’의 신뢰성은 낮지만 정확한 출처가 있는 정보는 신뢰성이 높은 것과 같은 맥락이다. 임 책임연구원은 “AI 신뢰성엔 사실일반성과 설명가능성, 공정성, 보안성 등의 카테고리가 있는데, 이 중 WebGPT방식은 설명가능성을 충족한다”고 설명했다. 만약 GPT-4가 WebGPT방식을 채택한다면 인간보다 더 똑똑한 AI가 될 수 있다.











