 X는 누구일까. 내가 X에 대해 알고 있는 것은 민정과 똑같은 이름, 나이, 본적, 그리고 주민등록상에 남아 있는 오래된 사진 뿐. X는 어떻게 생긴 사람일까. 도대체 지금은 어디에 있는 걸까. 진원은 민정의 방에서 발견한 신원불상의 DNA를 분석하면 얼굴을 추정해낼 수 있을 거라고 했다. X의 얼굴이 너무 궁금하다.
X는 누구일까. 내가 X에 대해 알고 있는 것은 민정과 똑같은 이름, 나이, 본적, 그리고 주민등록상에 남아 있는 오래된 사진 뿐. X는 어떻게 생긴 사람일까. 도대체 지금은 어디에 있는 걸까. 진원은 민정의 방에서 발견한 신원불상의 DNA를 분석하면 얼굴을 추정해낼 수 있을 거라고 했다. X의 얼굴이 너무 궁금하다.- 성준의 독백
# 법과학학회가 열리는 서울의 한 강연장
성준: (횡설수설하며) 여기에 DNA로 얼굴을 추정한다는 K 교수가 있다는 거지?
진원: 응, 그러니까 제발 진정해. 학회 발표가 끝나고 따로 뵙기로 했으니까, 차분하게 기다리자. 마침 오늘 주제가 DNA로 추정하는 외형 연구에 대한 거니까 우리도 들으면 좀 도움이 될 거야.
성준: (관심 없다는 듯 고개를 돌린다)
진원: K 교수를 잘 설득해야 돼. DNA를 가지고 외형을 추정하는 연구는 많이 되고 있지만, 실제로 과학수사에 활용하는 건 찬반이 뜨겁거든. K 교수는 어떻게 생각하는지 미리 알아볼 필요가 있어.
성준: 만약에 K 교수가 윤리적으로 문제가 있다고 생각하면? 그럼 분석을 안 해줄 수도 있다는 거야?
진원: 그럴 수도 있겠지. 만약 그렇다면… 이 학회에서 찬성하는 교수를 다시 찾아봐야겠지. 아, 시작한다. 집중해, 일단!
Session 1. DNA를 보면 얼굴이 보인다
DNA는 나에 대한 정보를 담고 있는 유전암호라고들 부릅니다. 나를 이루는 건 DNA라고 해도 과언이 아니죠. 과연 DNA로 어디까지 알 수 있을까요.
우선 민족을 추정할 수 있습니다. 이숭덕 서울대 의대 법의학교실 교수는 지난 5월 Y염색체의 짧은 반복 서열인 ‘Y-STR’을 이용해 동북아시아, 동남아시아, 서남아시아 사람을 구분할 수 있다는 연구를 발표했습니다(doi:10.7580/kjlm.2017.41.2.32). 지금까지 미국이나 유럽인들을 구분한 연구결과는 많았지만, 이렇게 아시아인들을 세분화한 연구는 이번이 처음입니다. 이 교수팀은 민족 간 차이가 큰 Y-STR의 패턴을 분석해 통계적으로 분류의 정확도를 높였는데요. 터키, 시리아, 이란 등 서남아시아인을 분류할 때는 86.8% 정확히 분류해 정확도가 가장 높았고, 동남아시아 인을 분류할 때는 72.16%로 가장 낮았습니다. 이 교수는 “후속 연구로 상염색체 STR이나 미토콘드리아 DNA를 이용해 민족을 구분하는 예측력을 높여가고 있는 중”이라고 말했습니다.
최근에는 놀랍게도 얼굴의 생김새까지도 추정할 수 있는데요. 네덜란드 로테르담에 위치한 에라스무스대 맨프레드 카이저 교수는 5개의 유전자를 가지고 얼굴의 생김새를 추정하는 연구를 했습니다(doi:10.1371/journal.pgen.1002932). 카이저 교수는 두개안면기형에 관여하는 유전자(PRDM16, PAX3, TP63, C5orf50, COL17A1)가 이목구비를 결정한다고 생각했습니다.
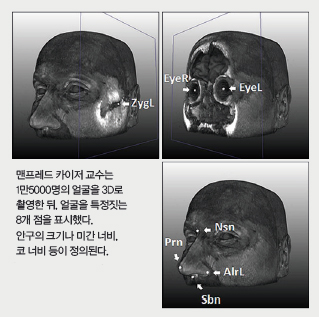
우선 1만5000명의 얼굴을 3D로 촬영한 사진으로부터 얼굴의 주요 8개 점의 정보를 얻었습니다. 그리고 난 뒤 점의 정보와 해당 유전자와의 관계를 통계적으로 분석해 우리가 흔히 볼 수 있는 평면 형태의 몽타주를 만들었습니다. 카이저 교수는 e메일 인터뷰에서 “DNA로 얼굴 모양을 추정하는 이번 연구는 향후 과학수사에 응용될 가능성이 매우 높다”고 말했습니다.
 Session 2. DNA 데이터베이스 어디까지 허용돼야 하나
Session 2. DNA 데이터베이스 어디까지 허용돼야 하나
본격적인 토론을 하기 전에 우선 전 세계적으로 DNA를 활용한 과학수사가 어디까지 허용되는지를 알아보겠습니다.
현장에서는 다양한 DNA가 발견됩니다. 지문도 발견되죠. 우리나라 국민이라면 지문을 필수로 등록해야 하기 때문에, 현장에서 발견된 지문은 금방 신원을 파악할 수 있습니다. 하지만 DNA는 다릅니다. 전국민의 DNA가 보관돼 있지는 않기 때문이죠. 현장에서 DNA가 발견되더라도 대조할 DNA가 없으면 무용지물입니다. 그냥 떠도는 신원불상의 DNA가 되는거죠. 그래서 DNA의 데이터베이스가 필요하다는 주장이 나오는 것입니다.
가장 먼저 범죄자의 DNA 데이터베이스를 구축한 나라는 영국입니다. 1995년 4월, 310만 명 이상의 범죄자 DNA 정보가 담긴 ‘NDNAD(National DNA Database)’를 구축했습니다. 전체 국민 중 5% 이상의 DNA 정보를 가지고 있어, 세계에서 가장 큰 규모입니다.
미국은 1994년 미국연방수사국(FBI)에게 범죄 현장에서 수집한 DNA 정보를 저장한 데이터베이스의 설립 권한을 주는 ‘DNA 신원 확인법(DNA Identification Act of 1994)’을 제정했습니다. 1998년 미국 연방 전체의 DNA 시스템을 통합한 ‘NDIS(National DNA Index System)’를 만들었고, 유죄를 선고 받은 300여 명의 DNA가 저장돼 있습니다.
반면 우리나라는 ‘디엔에이신원확인정보의이용및보호에관한법률’에 의해 DNA의 정보를 수집하는 것이 법적으로 불가능합니다. 이 법 제7조에는 ‘DNA 감식시료에서 얻은 DNA신원확인정보는 신원이 밝혀지지 않은 것에 한해서만 데이터베이스에 수록할 수 있다’고 나와있습니다. 즉 해결되지 않은 신원불상의 DNA 정보만 저장돼 있는 셈입니다. 2006년 ‘유전자감식정보의수집및관리에대한법률’이 국회에 제출되면서 DNA 데이터베이스에 대한 논의가 본격적으로 이뤄졌지만, 법률 제정까지는 이르지 못했습니다.
DNA 정보에 이렇게 예민한 이유는 몇 가지 윤리적인 문제들이 있기 때문입니다. 우선 우리나라는 ‘피고인 또는 피의자는 유죄판결이 확정될 때까지는 무죄로 추정한다는 원칙’인 무죄추정의 원칙을 따르고 있습니다. 범죄자의 DNA를 데이터베이스로 관리하는 것은 이미 저지른 범죄에 대해 대가를 치른 이들을 잠재적 범죄자로 취급하는 행위라는 점에서 무죄추정의 원칙에 어긋난다는 문제가 있습니다.
DNA는 나에 대한 정보를 담고 있는 유전암호라고들 부릅니다. 나를 이루는 건 DNA라고 해도 과언이 아니죠. 과연 DNA로 어디까지 알 수 있을까요.
우선 민족을 추정할 수 있습니다. 이숭덕 서울대 의대 법의학교실 교수는 지난 5월 Y염색체의 짧은 반복 서열인 ‘Y-STR’을 이용해 동북아시아, 동남아시아, 서남아시아 사람을 구분할 수 있다는 연구를 발표했습니다(doi:10.7580/kjlm.2017.41.2.32). 지금까지 미국이나 유럽인들을 구분한 연구결과는 많았지만, 이렇게 아시아인들을 세분화한 연구는 이번이 처음입니다. 이 교수팀은 민족 간 차이가 큰 Y-STR의 패턴을 분석해 통계적으로 분류의 정확도를 높였는데요. 터키, 시리아, 이란 등 서남아시아인을 분류할 때는 86.8% 정확히 분류해 정확도가 가장 높았고, 동남아시아 인을 분류할 때는 72.16%로 가장 낮았습니다. 이 교수는 “후속 연구로 상염색체 STR이나 미토콘드리아 DNA를 이용해 민족을 구분하는 예측력을 높여가고 있는 중”이라고 말했습니다.
최근에는 놀랍게도 얼굴의 생김새까지도 추정할 수 있는데요. 네덜란드 로테르담에 위치한 에라스무스대 맨프레드 카이저 교수는 5개의 유전자를 가지고 얼굴의 생김새를 추정하는 연구를 했습니다(doi:10.1371/journal.pgen.1002932). 카이저 교수는 두개안면기형에 관여하는 유전자(PRDM16, PAX3, TP63, C5orf50, COL17A1)가 이목구비를 결정한다고 생각했습니다.
우선 1만5000명의 얼굴을 3D로 촬영한 사진으로부터 얼굴의 주요 8개 점의 정보를 얻었습니다. 그리고 난 뒤 점의 정보와 해당 유전자와의 관계를 통계적으로 분석해 우리가 흔히 볼 수 있는 평면 형태의 몽타주를 만들었습니다. 카이저 교수는 e메일 인터뷰에서 “DNA로 얼굴 모양을 추정하는 이번 연구는 향후 과학수사에 응용될 가능성이 매우 높다”고 말했습니다.
Session 2. DNA 데이터베이스 어디까지 허용돼야 하나본격적인 토론을 하기 전에 우선 전 세계적으로 DNA를 활용한 과학수사가 어디까지 허용되는지를 알아보겠습니다.
현장에서는 다양한 DNA가 발견됩니다. 지문도 발견되죠. 우리나라 국민이라면 지문을 필수로 등록해야 하기 때문에, 현장에서 발견된 지문은 금방 신원을 파악할 수 있습니다. 하지만 DNA는 다릅니다. 전국민의 DNA가 보관돼 있지는 않기 때문이죠. 현장에서 DNA가 발견되더라도 대조할 DNA가 없으면 무용지물입니다. 그냥 떠도는 신원불상의 DNA가 되는거죠. 그래서 DNA의 데이터베이스가 필요하다는 주장이 나오는 것입니다.
가장 먼저 범죄자의 DNA 데이터베이스를 구축한 나라는 영국입니다. 1995년 4월, 310만 명 이상의 범죄자 DNA 정보가 담긴 ‘NDNAD(National DNA Database)’를 구축했습니다. 전체 국민 중 5% 이상의 DNA 정보를 가지고 있어, 세계에서 가장 큰 규모입니다.
미국은 1994년 미국연방수사국(FBI)에게 범죄 현장에서 수집한 DNA 정보를 저장한 데이터베이스의 설립 권한을 주는 ‘DNA 신원 확인법(DNA Identification Act of 1994)’을 제정했습니다. 1998년 미국 연방 전체의 DNA 시스템을 통합한 ‘NDIS(National DNA Index System)’를 만들었고, 유죄를 선고 받은 300여 명의 DNA가 저장돼 있습니다.
반면 우리나라는 ‘디엔에이신원확인정보의이용및보호에관한법률’에 의해 DNA의 정보를 수집하는 것이 법적으로 불가능합니다. 이 법 제7조에는 ‘DNA 감식시료에서 얻은 DNA신원확인정보는 신원이 밝혀지지 않은 것에 한해서만 데이터베이스에 수록할 수 있다’고 나와있습니다. 즉 해결되지 않은 신원불상의 DNA 정보만 저장돼 있는 셈입니다. 2006년 ‘유전자감식정보의수집및관리에대한법률’이 국회에 제출되면서 DNA 데이터베이스에 대한 논의가 본격적으로 이뤄졌지만, 법률 제정까지는 이르지 못했습니다.
DNA 정보에 이렇게 예민한 이유는 몇 가지 윤리적인 문제들이 있기 때문입니다. 우선 우리나라는 ‘피고인 또는 피의자는 유죄판결이 확정될 때까지는 무죄로 추정한다는 원칙’인 무죄추정의 원칙을 따르고 있습니다. 범죄자의 DNA를 데이터베이스로 관리하는 것은 이미 저지른 범죄에 대해 대가를 치른 이들을 잠재적 범죄자로 취급하는 행위라는 점에서 무죄추정의 원칙에 어긋난다는 문제가 있습니다.

또 이런 유전자 데이터베이스가 거대한 국가 통제시스템으로 나아가는 시작점이 될 거라는 주장도 있습니다. ‘미끄러운 비탈길(slippery slope)’ 문제라고 하는데요. 마치 한번 미끄러지기 시작하면 저 아래까지 쭉 미끄러지듯이, DNA로 표현형을 추정하는 연구가 법과학에서 시작되면, 언젠가는 일상적으로 유전자 검사를 하는 시대가 올지 모른다는 우려가 있습니다. 많은 개인 정보를 담고 있으니 조심히 다뤄야 하는 데도 불구하고요.
마지막 문제는 DNA가 외형을 얼마나 잘 예측할 수 있겠느냐는 정확성의 문제입니다. 현재 미국에서는 파라본 나노랩스(parabon nanolabs), 아이덴티타스(Identitas) 등 여러 생체정보인식기술 회사들이 DNA로 얼굴을 예측하는 서비스를 제공하고 있습니다. 수사기관에서도 도움을 받고 있는 상황이죠. 하지만 유전자의 영향을 비교적 많이 받는 눈동자 색의 정확도가 94%, 머리카락 색의 정확도가 75% 수준입니다. 얼굴의 형태는 노화나 환경, 생활습관의 영향을 매우 많이 받기 때문에 이보다 정확도가 더 낮습니다.
이런 문제들이 산재해 있음에도 계속해서 DNA 데이터베이스의 구축이 필요하다는 주장이 나오는 이유는 DNA 정보를 활용할 경우 범인을 검거할 가능성이 매우 높아지기 때문입니다. 실제 우리나라에서는 2013년 제주지역에서 10대 미성년자 성폭행범을 검거하기 위해 DNA를 대량 검색했습니다. 사건 현장 주변에 사는 1300여 명의 DNA를 채취했고, 사건 피해자의 옷에서 발견된 범인의 DNA와 비교 분석해 결국 성폭행범을 잡았습니다.
마지막 문제는 DNA가 외형을 얼마나 잘 예측할 수 있겠느냐는 정확성의 문제입니다. 현재 미국에서는 파라본 나노랩스(parabon nanolabs), 아이덴티타스(Identitas) 등 여러 생체정보인식기술 회사들이 DNA로 얼굴을 예측하는 서비스를 제공하고 있습니다. 수사기관에서도 도움을 받고 있는 상황이죠. 하지만 유전자의 영향을 비교적 많이 받는 눈동자 색의 정확도가 94%, 머리카락 색의 정확도가 75% 수준입니다. 얼굴의 형태는 노화나 환경, 생활습관의 영향을 매우 많이 받기 때문에 이보다 정확도가 더 낮습니다.
이런 문제들이 산재해 있음에도 계속해서 DNA 데이터베이스의 구축이 필요하다는 주장이 나오는 이유는 DNA 정보를 활용할 경우 범인을 검거할 가능성이 매우 높아지기 때문입니다. 실제 우리나라에서는 2013년 제주지역에서 10대 미성년자 성폭행범을 검거하기 위해 DNA를 대량 검색했습니다. 사건 현장 주변에 사는 1300여 명의 DNA를 채취했고, 사건 피해자의 옷에서 발견된 범인의 DNA와 비교 분석해 결국 성폭행범을 잡았습니다.











