유치원생 수십 명과 소풍을 간다고 상상해 보자. 인지 수준이 낮은 어린이들은 자칫 사고가 날 수 있다. 그렇다고 아이 한 명에 선생님이 일일이 붙을 수 도 없는 노릇. 그래서 아이들이 어느 정도 스스로 판단 하고 대처할 수 있도록 행동 규칙을 미리 알려준다. 짝 꿍의 손을 꼭 잡고, 낯선 아저씨가 사탕 준다고 해도 따 라가지 말라고.
군집로봇도 마찬가지다. 여러 대의 로봇이 한 데 모여 움직이지만, 각 로봇은 비싼 센서나 인공지능을 탑재하 지 않았다. 당연히! 주변 로봇과 충돌하기 쉽다. 더구나 하나하나 조종할 수도 없다. 로봇이 알아서 움직여야 한다는 얘기다. 이 때 충돌도 막고 군집로봇을 원하는 방향으로 정교하게 보내려면 움직이는 방법, 즉 ‘원칙’을 잘 만들어 머리 속에 넣어줘야 한다. 이런 프로그램이 바로 ‘군집 알고리듬’이다. 군집로봇의 성패는, 군집 알 고리듬이 얼마나 정교한가에 달렸다.
드론 군집비행이 준 충격과 공포
이런 측면에서 미국 펜실베니아대 비제이 쿠마 교수 팀이 선보인 드론 군집비행(1파트 참조)은, 로봇공학자 인 필자에겐 ‘충격과 공포(!)’였다. 쿠마 교수가 2012년 2 월에 올린 유튜브 영상 속에서 드론들은 마치 나비처럼 날아올라 벌처럼 쏘는 듯 재빠르고 화려한 군무를 선보 인다. 거침없이 편대를 바꾸고, 주변 드론이 날개를 돌 릴 때 나오는 세찬 바람에도 영향을 받지 않는다. 일렬 로 줄 맞추는 것도 어려워하던 유치원생들이 갑자기 프로 댄싱팀으로 탈바꿈한 현장을 목격한 기분이었다. 당시 같은 주제를 연구하던 필자는 조바심이 났다. 그로부터 2년 뒤 박사학위를 받았으니, 지구 반대편에 사는 그가 필자를 채찍질한 셈이다.
 어쨌든 그의 드론 군집비행이 독보적으로 훌륭 하긴 했어도, 쿠마 교수 혼자 이뤄낸 결과는 아니 다. 하루아침에 이뤄진 건 더더욱 아니다. 30년 전 부터 생물학자와 수학자, 전산학자 등 수많은 과학자들 은, 거대한 군집을 이뤄 포식자로부터 스스로를 보호하 는 물고기나 편대비행을 통해 체력 소모를 최소화하며 장거리를 비행하는 철새의 행동을 규명하고 컴퓨터 시 뮬레이션으로 구현하려 했다. 마침내 1987년, 미국의 컴퓨터그래픽 전문가인 크레이그 레이놀즈가 세계 최 초로 군집 알고리듬을 개발해 새떼의 움직임을 시뮬레 이션하는 데 성공했다. 그는 군집을 이루는 각 개체에 세 가지 단순한 규칙을 주입했다. 서로 너무 가까이 접 근하지 않는 ‘분리성’, 주변 개체가 이동하는 방향으로 움직이는 ‘정렬성’, 서로 너무 멀어지는 것을 피하는 ‘응 집성’ 등이다. 그의 연구 결과는 군집 이론의 기본 조건 으로 자리잡았고, 이를 응용한 다양한 알고리듬이 꾸준히 발표됐다.
어쨌든 그의 드론 군집비행이 독보적으로 훌륭 하긴 했어도, 쿠마 교수 혼자 이뤄낸 결과는 아니 다. 하루아침에 이뤄진 건 더더욱 아니다. 30년 전 부터 생물학자와 수학자, 전산학자 등 수많은 과학자들 은, 거대한 군집을 이뤄 포식자로부터 스스로를 보호하 는 물고기나 편대비행을 통해 체력 소모를 최소화하며 장거리를 비행하는 철새의 행동을 규명하고 컴퓨터 시 뮬레이션으로 구현하려 했다. 마침내 1987년, 미국의 컴퓨터그래픽 전문가인 크레이그 레이놀즈가 세계 최 초로 군집 알고리듬을 개발해 새떼의 움직임을 시뮬레 이션하는 데 성공했다. 그는 군집을 이루는 각 개체에 세 가지 단순한 규칙을 주입했다. 서로 너무 가까이 접 근하지 않는 ‘분리성’, 주변 개체가 이동하는 방향으로 움직이는 ‘정렬성’, 서로 너무 멀어지는 것을 피하는 ‘응 집성’ 등이다. 그의 연구 결과는 군집 이론의 기본 조건 으로 자리잡았고, 이를 응용한 다양한 알고리듬이 꾸준히 발표됐다.최초 군집 알고리듬의 세 가지 규칙
미국의 컴퓨터그래픽 전문가 크레이그 레이놀즈가 1987년 세계 최초로 구현한 군집 알고리듬의 세 가지 규칙. 군집 이론의 기본 조건으로 자리잡았다.
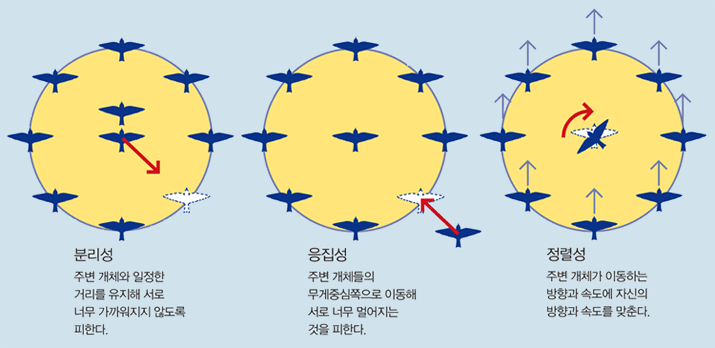
미국의 컴퓨터그래픽 전문가 크레이그 레이놀즈가 1987년 세계 최초로 구현한 군집 알고리듬의 세 가지 규칙. 군집 이론의 기본 조건으로 자리잡았다.
하지만 군집 알고리듬을 군집로봇에 그대로 적용할 수 없었다. 로봇의 ‘운동 요소’를 고려하지 않았기 때문 이다. 예를 들어 가정용 청소로봇은 로봇 바닥에 있는 바퀴 두 개의 회전 수를 조절해 직진이나 회전을 하는 데, 만약 옆으로 가고 싶으면 먼저 제자리에서 회전을 한 뒤 직진해야 한다. 수상 로봇은 물 위에서 아무리 추 력을 내도 제자리에서 급격히 회전하기가 어렵기 때문 에 회전 반경을 고려해 알고리듬을 짜야 한다. 1990년 대 중반부터 로봇공학자들은 이런 물리적 한계를 고려 한 ‘포메이션 제어기법’을 연구하기 시작했다. 자연계의 군집행동을 로봇에 특화한 알고리듬인 셈이다.
리더가 고장나면 나머지 로봇은 어떡하지?.
최초의 포메이션 제어기법은 1998년 미국 조지아공 대 로널드 아킨 교수가 개발했다. 몇 가지 ‘모드’를 정해놓고 필요할 때 켜고 끄는 방법이다. 예를 들어, 각 로 봇에 대형유지, 장애물회피, 목표지점추종 등의 모드를 저장해 둔다. 그리고 센서로 들어온 외부 정보를 종합 해 아무런 변화가 없을 때는 대형유지 모드를, 갑자기 장애물이 나타났을 때는 장애물회피 모드를 켠다. 매 우 간단하지만, 돌발상황이 발생했을 때 로봇이 어떻게 행동할지 모른다는 단점이 있다.
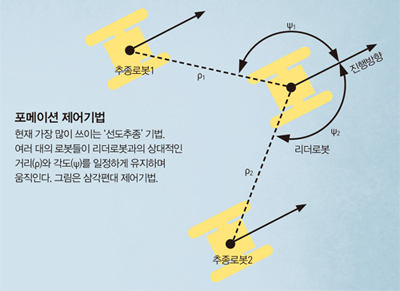 포메이션 제어기법도 발전을 거듭해, 현재는 ‘선도추 종 제어기법’이 가장 많이 쓰인다. 2001년 미국 드렉셀 대 제이데브 데사이 교수(현 메릴랜드대 교수)가 철새들 의 V자 편대비행을 본 따 만들었다. 철새들은 맨 앞에 있는 리더를 중심으로 자기 앞에 보이는 다른 새들과의 상대적 위치를 유지하면서 비행한다. 마찬가지로 군집 로봇도 한 대의 리더로봇을 중심으로 추종로봇들이 일 정한 거리와 각도를 유지하면서 움직인다. 이 기법을 적 용하면 로봇 대수를 무한정으로 늘리면서 편대를 유지 할 수 있다. 또 알고리듬의 성능과 안정성을 수학적으 로 증명할 수 있다는 것도 장점이다.
포메이션 제어기법도 발전을 거듭해, 현재는 ‘선도추 종 제어기법’이 가장 많이 쓰인다. 2001년 미국 드렉셀 대 제이데브 데사이 교수(현 메릴랜드대 교수)가 철새들 의 V자 편대비행을 본 따 만들었다. 철새들은 맨 앞에 있는 리더를 중심으로 자기 앞에 보이는 다른 새들과의 상대적 위치를 유지하면서 비행한다. 마찬가지로 군집 로봇도 한 대의 리더로봇을 중심으로 추종로봇들이 일 정한 거리와 각도를 유지하면서 움직인다. 이 기법을 적 용하면 로봇 대수를 무한정으로 늘리면서 편대를 유지 할 수 있다. 또 알고리듬의 성능과 안정성을 수학적으 로 증명할 수 있다는 것도 장점이다.필자가 속한 연구팀이 개발하고 있는 해파리퇴치 군 집로봇 ‘제로스(JEROS)’도 선도추종 제어기법을 쓰는 데, 로봇을 추가로 제작할 때마다 알고리듬을 크게 수 정하지 않고도 시스템을 바로 구현할 수 있다. 물론 이런 장점 덕분에(?) 로봇을 추가로 제작할 것을 염두에 두고 처음부터 ‘엄청나게 신중히’ 로봇을 설계해야 했던 경험은, 우리들에게 또 다른 고통이었다.
하지만 선도추종 제어기법엔 큰 단점이 하나 있다. 스티브 잡스가 사망했을 때 애플이 흔들렸던 것처럼, 리 더 로봇이 고장 나면 남은 군집로봇들이 임무를 더 이 상 수행할 수 없게 된다. 그래서 리더로봇과 추종로봇 을 구분하지 않고 각 로봇이 동등한 지위에서 주변 정 보만으로 움직이게 하는 방법도 연구 중이다. 일부 로 봇이 기능 정지 상태에 빠져도 다른 로봇은 임무를 계 속해서 수행할 수 있다.
컴퓨터 속도가 빨라지면서 최근에는 ‘최적화 기법’을 이용해 더 똑똑한 군집로봇이 나오고 있다. 최적화 기 법은 주변 로봇이 앞으로 움직일 경로와 함께 로봇간 충돌회피, 장애물회피, 로봇의 최대속도 등 다양한 조 건을 고려해 가장 좋은 경로를 찾는다. 나란히 서서 전 진하는 두 대의 로봇 앞에 장애물이 있다고 가정해보 자. 부딪치지 않으려면 언젠가 반드시 방향을 틀어야 한다. 이 때 로봇이 서로 현재 위치만 안다면, 다른 로 봇이 언제 어떻게 꺾을지 몰라 자칫 충돌할 수 있다. 그 러나 각자 앞으로 어떻게 움직일지 안다면, 장애물과 상대 로봇 모두와의 충돌을 완벽하게 피할 수 있다.
INSIDE | 통신에서 물류까지, 팔방미인 무리지능

최적화 기법 중 자연계의 군집행동에서 힌트를 얻어 개발된 ‘무리지능(Swarm Intelligence)’ 알고리듬은, 수학적 접근 방법으로는 도저히 풀기 어려운 최적화 문제를 해결할 수 있게 해준다. 개미들이 페로몬 분비를 기반으로 길을 찾는 과정을 모사해 그래프에서 최적 경로를 찾는 개미집단 최적화 알고리듬이 대표적이다. 이외에도 반딧불의 발광 주기가 비슷해지는 과정을 본 딴 반딧불 알고리듬, 새떼나 물고기떼의 유기적인 움직임을 모사한 입자군집최적화 알고리듬 등이 있다. 간혹 이런 무리지능 알고리듬을 군집로봇 제어와 동일하게 설명하는 글을 볼 수 있는데, 꼭 그렇지는 않다. 무리지능 알고리듬은 통신/물류 최적화, 조합최적화 등 군집로봇 외 각종 시스템에 대한 최적 제어에 광범위하게 쓰인다.
최적화 기법엔 크게 결정론적 방법과 확률론적 방법 이 있다. 결정론적 방법은 수학적으로 최적의 값(해)을 찾는 방법으로, 주어진 조건이 같다면 항상 같은 해를 얻는다. 행동을 결정하는 시간이 짧기 때문에 단순한 환경이나 임무에 잘 어울린다. 확률론적 방법은 변수를 무작위로 발생시켜 해를 찾는 방법으로, 주어진 조건이 같아도 다른 결과가 얻어진다. 시간이 많이 걸리지만 좀 더 복잡한 문제를 다룰 수 있다.
로봇 점검에만 하룻밤 꼬박 새기도
군집로봇 알고리듬 이론은 그간 상당히 발전해왔다. 그러나 실제로 움직이는 로봇에 적용한 검증은 잘 이뤄 지지 않고 있다. 아무리 좋은 소고기라도 소금과 후추가 있어야 맛좋은 스테이크가 되듯, 아무리 훌륭한 알고리 듬이라도 로봇간 통신이나 경로계획, 위치인식 등 다양 한 기반기술이 뒷받침돼야 실제 군집시스템으로 구현될 수 있다. 가끔 “연구 과정에서 무엇이 가장 힘들었냐”는 질문을 받으면 “로봇을 실제로 구현하는 것”이라고 답하 는 이유다. 해파리퇴치 군집로봇도 넓은 해양에서 임무 를 수행하기 위해 수많은 전자장치를 갖추고 있는데, 실 험 전날 점검하는 데만 모든 팀원들이 꼬박 밤을 새야 한다. 아무리 꼼꼼히 점검해도 막상 바다에 가면 꼭 말 썽이 일어난다.
앞으로는 실제 로봇을 통한 검증뿐만 아니라 야외의 어떤 환경에서도 똑같이 작동하는 군집 알고리듬 연구 가 필요하다. 처음에 말한 드론 군집 비행도 실험실에 서 여러 대의 카메라를 설치해 위치를 정밀하게 인식할 수 있었기 때문에 가능했다. 자동차 내비게이션이 종종 건물이나 산을 뚫고(!) 가라고 오작동하는 걸 보면, 위 치를 인식한다는 게 얼마나 어려운 일인지 알 수 있다. 고층 빌딩 사이에서는 GPS신호조차 이용하기 어렵다. 그래서 필자는 제한된 정보만으로 스스로 군집을 이루 는 시스템을 향후 연구할 계획이다. 군집로봇은 지금부터 시작이다.
▼관련기사를 계속 보시려면?
뭉치면 강하다 군집로봇
INTRO - 거대로봇과 새떼로봇이 싸운다면?
PART1 - 영화 속 거미군단이 온다
PART2 - 군집로봇 뇌 속엔 무엇이 들었을까
PART3 - 한반도 재난 해결할 토종 군집로봇 9마리해파리퇴치 로봇내년 마산만 누빈다