클라우드는 한 마디로 빌려쓰는 서비스다. 클라우드 제공자는 사용자가 편리하고 빠르게 데이터를 처리하고 연산을 수행할 수 있도록 네트워크, 메모리, 스토리지, 애플리케이션 등 다양한 IT자원을 빌려준다. 클라우드가 기술적으로 어떻게 작동하는지 구름 속을 들여다보자.
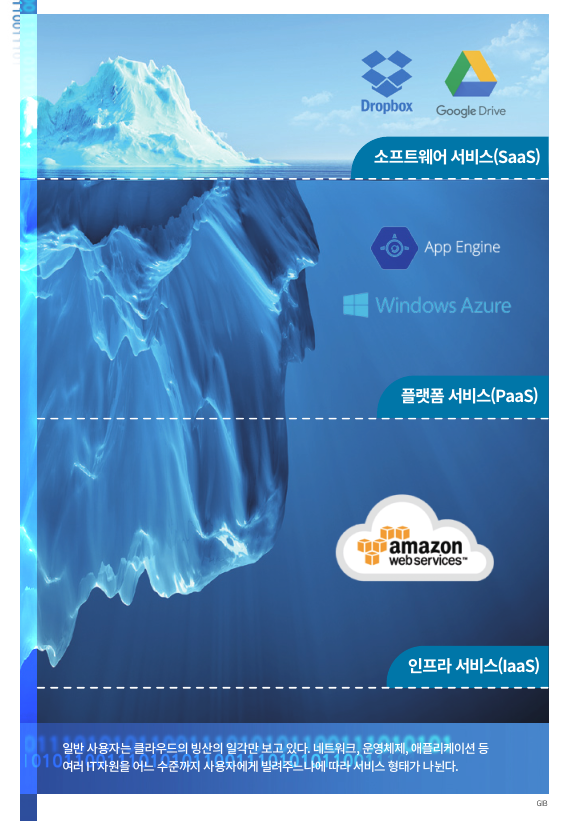
깊이가 다른 세 종류의 클라우드
‘네이버 클라우드’는 빙산의 일각
클라우드 서비스는 어느 수준까지 사용자에게 빌려주느냐에 따라 크게 세 종류로 구별된다. 우리가 가장 쉽게 접하는 건 응용 소프트웨어를 제공해주는 ‘소프트웨어 서비스(SaaS·Software as a Service)’ 클라우드 다. 구글의 ‘지메일(Gmail)’, 노트 필기 애플리케이션인 ‘에버노트(Evernote)’, 네이버 클라우드 등이 대표적이다.
사용자는 컴퓨터나 개인 단말기에 별다른 프로그램을 설치하지 않고도 인터넷을 이용해 언제 어디서든 파일을 업로드, 다운로드할 수 있다. 사용자가 소프트웨어를 이용할 때 이와 관련된 데이터 처리, 저장 등의 모든 관리는 클라우드 제공자가 맡는다.
그런가 하면 소프트웨어를 개발하고 운영할 수 있는 플랫폼을 제공하는 ‘플랫폼 서비스(PaaS·Platform as a Service)’ 클라우드 도 있다. PaaS는 개발자들이 주로 이용한다. 클라우드 공급자가 제공하는 개발 소스를 받아 원하는 소프트웨어를 만들어 클라우드 기반으로 운영할 수 있다.
마지막으로 클라우드를 운영하는 데 필요한 다양한 IT자원을 서비스로 제공하는 ‘인프라 서비스(IaaS·Infrastructure as a Service)’ 클라우드가 있다.
예를 들어 세계적인 영화, 방송 스트리밍 서비스 기업인 넷플릭스는 자체 데이터센터를 갖고 있지만 클라우드 업체인 아마존웹서비스(AWS)의 데이터센터 내 서버와 서버간 네트워크를 관리하는 인프라 서비스(IaaS)를 빌려쓴다.
INFOGRAPHIC
클라우드 기술 어떻게 작동할까
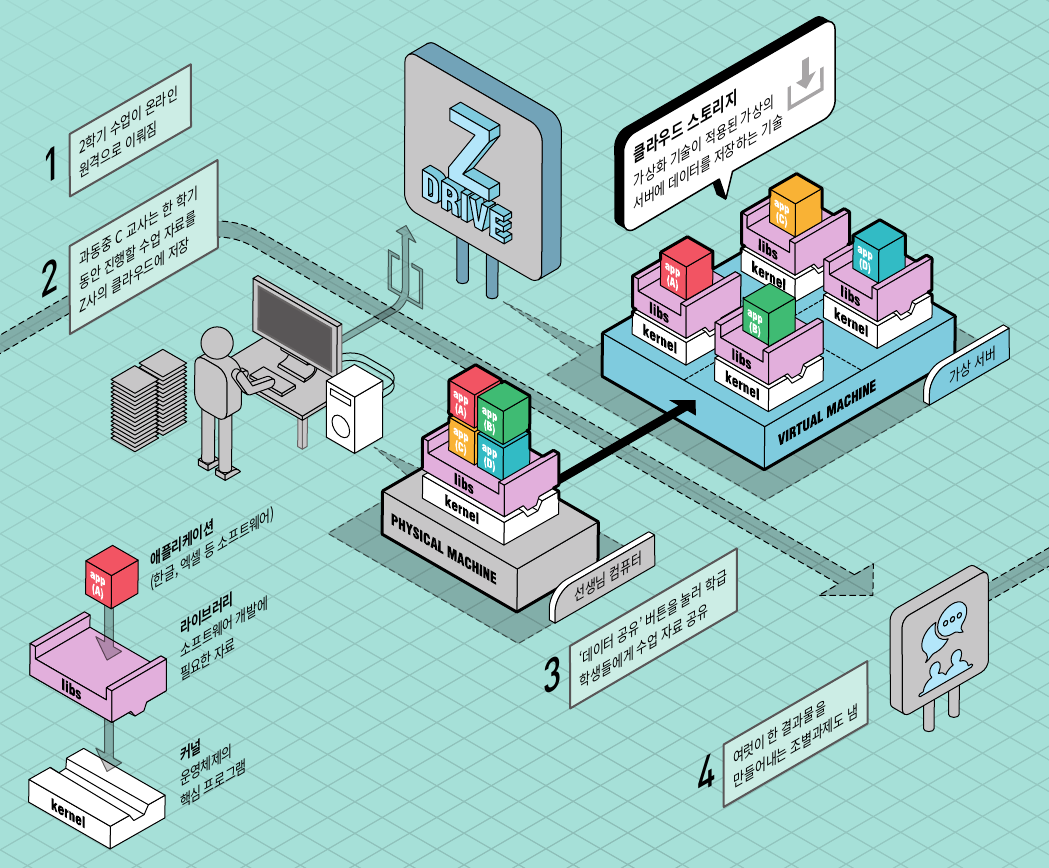
일상에서 클라우드는 매우 손쉽게 이용할 수 있다. 그러나 그 속에는 복잡한 기술이 녹아들어 있다. 원격 수업을 진행하게 된 과동중 C 교사와 학생들이 클라우드를 이용하는 상황을 가정해 클라우드 기술이 어떻게 작동하는지 살펴보자.
클라우드 스토리지 기술
클라우드는 인터넷상의 가상의 저장 공간에 정보를 보관해두고 필요할 때 웹서버에 접속해 불러올 수 있게 한다. 과동중 교사가 올려둔 정보를 학생들은 별도의 프로그램을 설치하지 않고 간단한 인터넷 접속만으로 어디서든 내려받을 수 있다.
이는 가상의 저장공간에 데이터를 보관할 수 있게 해주는 ‘클라우드 스토리지(cloud storage)’ 기술이다. 드롭박스, 구글 드라이브, 네이버 클라우드, 원드라이브 등이 대표적인 클라우드 스토리지 서비스다.
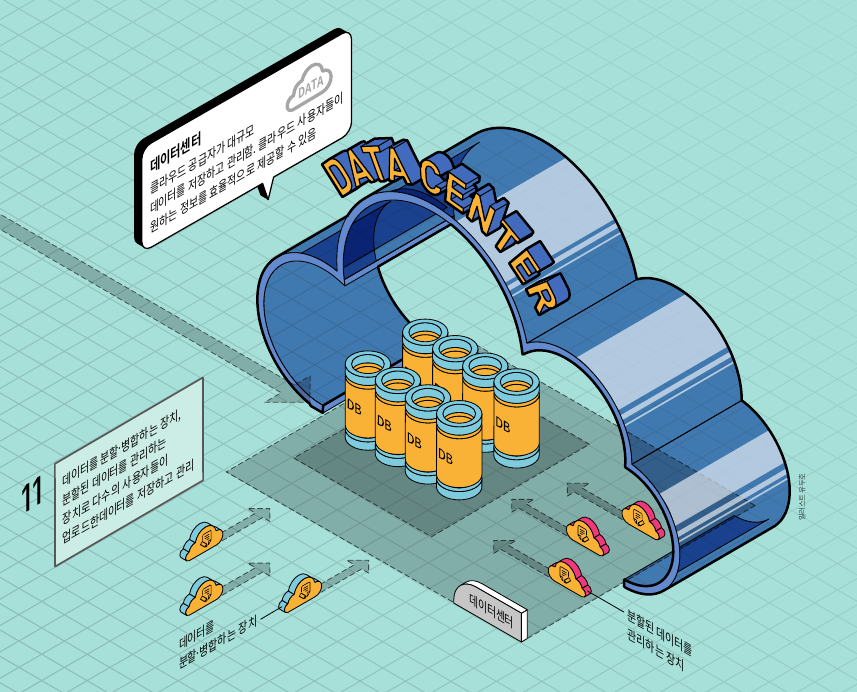
클라우드 스토리지 기술의 핵심은 ‘가상화’다. 가령 가상화 기술은 지구상에 어딘가에 있을 여러 대의 실물 컴퓨터를 하나인 것처럼 묶은 뒤 목적에 따라 다시 여러 개의 가상 서버(컴퓨터와 유사한 기능을 한다. 이 글에서는 클라우드에서 사용하는 365일 접속가능하고 성능이 뛰어난 컴퓨터를 서버라고 구분해 부른다)로 분할한다. 사용자는 작게 쪼개놓은 가상 서버에 원격으로 접속해 애플리케이션을 이용해 데이터를 저장한다. 이렇게 가상화를 통해 컴퓨터를 분산 운영하면 보유한 IT자원의 효율적으로 활용할 수 있다. 가상화 기술은 네트워크에도 쓰이는데, 하나의 네트워크를 여러 가상의 네트워크로 분할하면 통신의 효율을 높일 수 있다.
한편 가상화 기술은 물리적으로 분산된 여러 대의 컴퓨터를 네트워크로 연결해 한 대의 거대한 가상 서버처럼 통합적으로 운영하기도 한다. 전 세계에 흩어져 있는 컴퓨터가 하나의 서버처럼 데이터를 저장한다는 뜻이다. 대용량 데이터를 이 서버에 저장하면, 실제로는 여러 대의 컴퓨터에 분산 저장된다. 데이터를 잃어버릴 염려가 없고, 업로드와 다운로드 속도가 빨라지는 장점이 있다.
강동재 한국전자통신연구원(ETRI) 클라우드기반SW연구실 책임연구원은 “일반 사용자의 경우 클라우드에 저장할 수 있는 정보의 양은 사실상 무제한”이라고 설명했다. 이동식저장장치(USB)의 크기는 10년 전과 크게 다르지 않지만 저장 용량은 비약적으로 증가한 것처럼, 클라우드 기술이 발전하면서 하나의 서버만으로도 충분히 많은 양의 자료를 긴 시간 동안 보관할 수 있게 됐기 때문이다. 클라우드 사용자는 이 모든 것을 신경쓰지 않아도 되고 사용한 만큼 비용만 지불하면 된다.
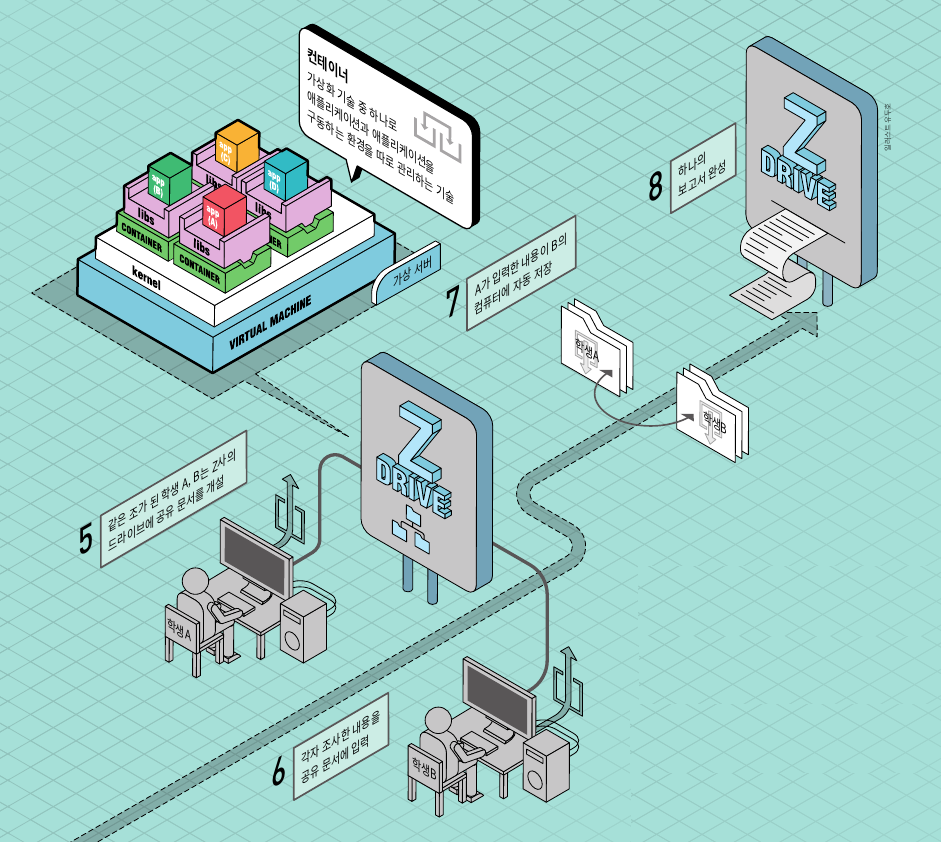
내 컴퓨터 환경을 그대로 옮기는 컨테이너
학생 A, B가 편리하게 공유 문서를 사용한 건 클라우드 기반 응용 소프트웨어(애플리케이션)에 ‘컨테이너’ 기술이 적용된 덕분이다. 사전에서 컨테이너는 어떤 물체를 격리하는 공간이라는 뜻을 갖고 있다.
클라우드의 컨테이너 기술은 서버 가상화 기술 중 하나로, 기존 가상화 기술에서는 가상 서버가 윈도우 등 무거운 운영체제와 애플리케이션, 그리고 애플리케이션을 구동하는 환경을 함께 관리한다.
반면 컨테이너는 애플리케이션과 애플리케이션을 구동하는 환경을 따로 관리한다. 가상 서버보다 가벼워 다른 곳으로 손쉽게 옮길 수 있고, 애플리케이션 구동 환경을 포함하기 때문에 이동한 곳에서 애플리케이션을 안정적으로 사용할 수 있다.
가령 학생 A, B가 메일이나 USB로 주고받은 보고서를 각자 개인 컴퓨터에서 열어본다고 가정해보자.
학생 A가 만든 보고서를 학생 B의 컴퓨터에서 열었을 때 서체가 달라지거나 글씨가 깨지거나 이미지가 보이지 않을 수 있다. 컴퓨터마다 소프트웨어의 버전이나, 네트워크, 보안 설정이 달라서다. 컨테이너는 애플리케이션을 구동하는 환경에 제약을 받지 않기 때문에 이런 문제를 해결할 수 있다.
학생 A가 집에 있는 컴퓨터로 문서 작업을 하다가 학교 컴퓨터로 이어서 작업을 할 때도 컨테이너 기술이 작용한다. 집에서 작업할 때 사용하던 서브 프로그램이나 코드가 컨테이너에 함께 저장돼 따라다니므로 학교에서 문서를 열 때도 이전 작업 내용이 그대로 남아있다.
김병섭 ETRI 클라우드기반SW연구실 책임연구원은 “컨테이너는 소프트웨어에 독립적인 실행 공간을 제공하는 기술로 소프트웨어가 안정적으로 실행되게 만든다”고 설명했다.
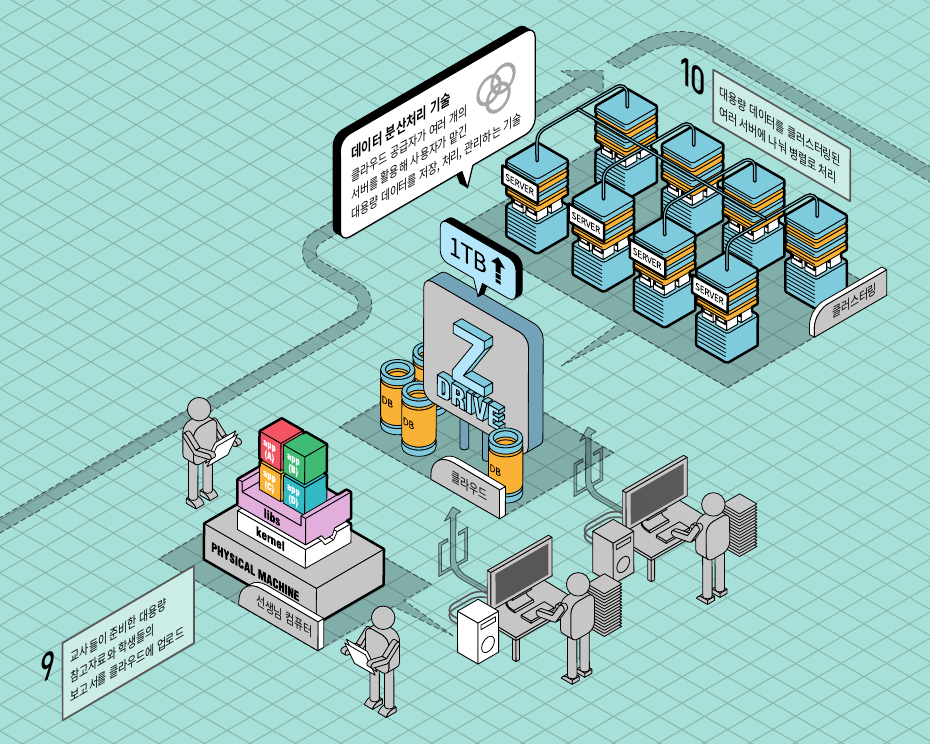
대규모 데이터 분산처리 기술
C 교사가 사용한 클라우드 스토리지는 1TB에 불과하지만, 기업, 연구소 등에서는 이보다 몇천, 몇만 배 큰 데이터가 발생한다. 예를 들어 우주를 관측하는 미국항공우주국(NASA)에서는 단 며칠만 우주를 관측해도 수십 PB(페타바이트·1PB는 약 105만GB)의 데이터가 생성된다.
대용량 데이터는 전송하는 데도 오랜 시간이 걸린다. 데이터를 분석하고 처리하는 시간도 만만치 않다. 고성능 중앙처리장치(CPU)와 대용량 메모리가 탑재된 초고성능 컴퓨터가 필요하다.
하지만 모든 사람이 초고성능 컴퓨터를 소유하는 것은 아니고, 사실 그럴 필요도 없다. 데이터 분산처리 기술을 제공하는 클라우드 서버를 빌려 쓰면 된다.
데이터 분산처리는 클라우드 공급자가 데이터를 여러 서버에 나눠 병렬로 처리하는 기술이다. 이를 위해 클라우드 공급자는 여러 개의 서버를 하나의 서버처럼 엮는다. 조금 어려운 용어로 클러스터링이라고 부르는데, 클러스터링을 하면 대용량 데이터를 처리하는 중간에 몇 개 서버에 장애가 발생해도 나머지 서버에 자동으로 작업을 할당함으로써 데이터 처리 작업을 이어나갈 수 있다. 데이터 처리 과정 중에 일부 서버에 과부하가 걸리면 그 서버 사용을 줄이거나, 혹은 구동 중이지 않던 새로운 서버를 사용하는 식으로 작동하기 때문이다. 결과적으로 대용량 데이터를 고속으로 처리할 수 있다.
이외에도 클라우드에는 대용량 데이터를 특정 형식으로 표현해 편리하게 쓸 수 있는 데이터베이스 기술, 인터넷을 통해 서비스를 이용하게 하고, 정보 공유를 지원하는 기술 등이 적용돼 있다.