


지금 당장 컴퓨터를 켜고 인터넷 검색창에 ‘타지 마할(Taj mahal)’을 입력해 보자. 가장 먼저 보이는 결과는 인도의 아름다운 사원 타지 마할이다.
그런데 검색한 사람의 의도가 타지 마할이 아니라면? 실제로 그래미상을 받은 뮤지션, 근처 인도 음식점, 호주에서 만든 독립 영화 이름도 타지 마할이다.
근처 인도 음식점 이름을 머릿속에 두고 타지 마할로 검색했다면 만족할 만한 결과를 얻을 수 없을 것이다. 꽃미남 배우 ‘김수현’을 검색하면 어떨까.
이름이 김수현인 배우는 여러 명이다. 유명 드라마 작가도 있다. 과연 검색자는 어떤 의도로 ‘김수현’을 검색했을까. 검색은 이제 현실의 사물과 사람을 이해하고 검색어에 연결된 관계까지 파악하기 시작했다. 이런 검색을 대표하는 구글 검색은 어떻게 탄생했을까. 구글의 ‘은밀한’ 데이터 과학의 세계로 들어가 보자.

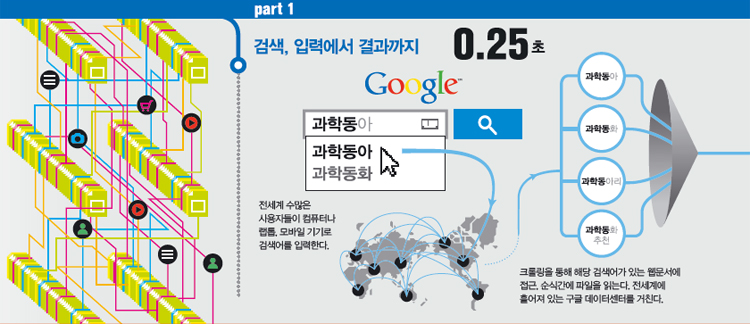
구글 검색창에 키워드를 입력하면 해당 검색어는 인터넷 회선을 타고 세계에 흩어져 있는 구글의 데이터센터(방대한 양의 자료와 파일이 오고가는 서버와 저장장치를 한 데 모은 곳) 중 한 곳에 도착한다. 그 곳에서 구글이미리 수집해 놓은 해당 검색어가 들어있는 자료와 비교해 일치하는 내용을

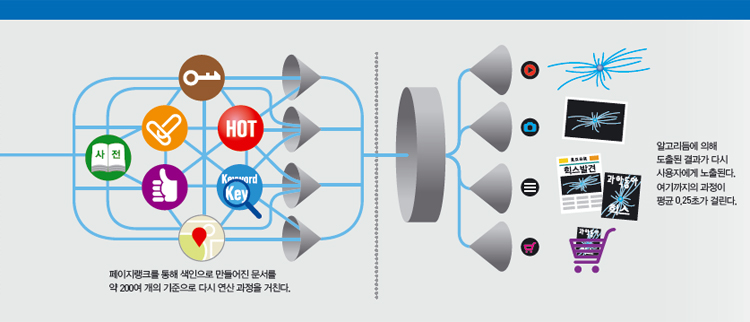
여기까지는 일반 검색엔진이 하는 작업과 같다. 구글은 웹문서를 수집할 때 ‘페이지랭크’라는 획기적인 방식을 개발해 세계적인 검색기업으로 떠올랐다. 어떤 웹사이트를 다른사이트가 많이 언급할수록 좋은 정보를 지닌 사이트라고 가정하고, 그런 언급이 많은 사이트를 검색 결과 상단에 노출하는 수학적 연산 방법이 바로 페이지랭크다. 이렇게 수집된 웹문서를 색인처럼 만들고 각 색인이 포함된 문서를 200여 개 기준으로 다시 컴퓨터 연산과정을 거친다. 콘텐츠의 최신성, 웹문서에 포함된 키워드, 연결된 사용자가 추천한 검색결과 등이 그 기준이다. 검색 결과는 다시 인터넷 회선을 타고 검색창에 뜬다. 이렇게 검색어 하나가 여행하는 물리적 거리는 평균 2400km. 미국 아이오와와 오클라호마,
노스캐롤라이나 등 6곳의 데이터센터와 유럽의 핀란드 등 2곳, 홍콩, 대만, 싱가포르 등에 있는 데이터센터 중 사용자와 가까운 곳에 있는 데이터센터를 거친 결과다.
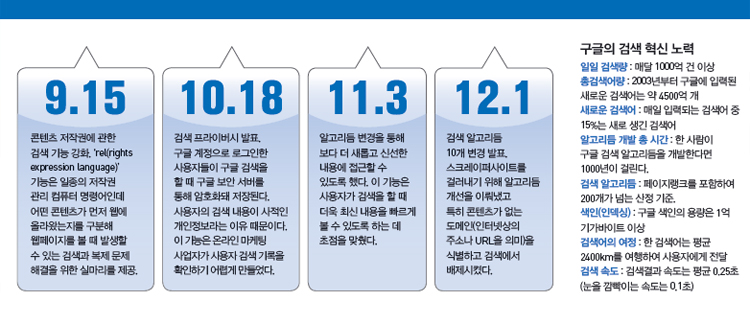
구글은 검색결과 순위산정 알고리듬을 매년 500회 이상 개선하고 있다. 2011년에만 500회, 2012년에 665회 개선했다. 전세계 다양한 사람들을 고용해 같은 검색어에 2개의 다른 결과를 보여주며 어떤 결과가 도움이 되는지 평가하는 방식이다. 미국 마운틴뷰에 있는 구글 본사에서 만난 여러 검색 엔지니어들은 “새로운 순위 산정을 위한 아이디어를 내고 현재 결과와 비교 대조하기 위한 실험을 직접 수행하는 것이 하는 일의 전부”라며 “어떤 아이디어라도 실험을 거치기 전에는 비판받지 않는다”고 분위기를 전했다. 이런 문화가 기술 발전의 인프라가 돼 현재의 구글을 만든 것이다.


영국 맨체스터 하면 떠오르는 것은? 어떤 이는 맨체스터라는 도시의 지역 정보를, 또 어떤 이는 프로축구팀 맨체스터유나이티드나 맨체스터시티를 떠올린다. 그렇다면 ‘맨체스터’라는 키워드로 검색하면 어떤 결과를 보여줘야 할까. 아니면 ‘날씨가 따뜻해지는 봄에 보면 좋을 만한 콘서트를 추천해 주세요’라는 질문에 대한 대답을 컴퓨터가 할 수 있을까.
이런 질문은 인공지능에 관한 오래된 연구지만 구글은 지식그래프라는 새로운 검색 서비스를 통해 웹에서 답을 찾으려 하고 있다. 예를 들어
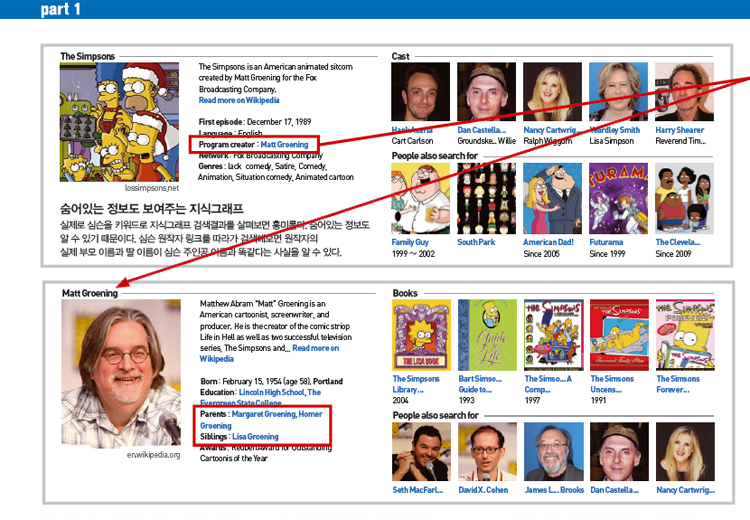
보자. 미국 뉴욕의 전현직 시장은 각각 루디 줄리아니와 마이클 블룸버그다. 지난해 5월 구글이 선보인 지식그래프 결과는 흥미롭다. 엄청난 재산을 지닌 블룸버그 현 뉴욕 시장의 경우 재산이 요약돼 제공된다. 반면 줄리아니 전 시장의 경우에는 재산이 누락돼 있다. 검색 키워드와 연관된 정보를 자동으로 추출하는 알고리듬에 의한 것이다.
벤 곰스 구글 검색 기능 엔지니어링 총괄 부사장은 “사람이 어떤 한 단어에 대해 생각하는 것을 ‘엔터티(실체)’라고 한다면 한 단어에는 무수한 엔터티가 포함돼 있다”고 말한다. 곰스 부사장은 “이 엔터티가 어떤 웹문서를 참조하고 있는지, 이 엔터티에 대해 사람들이 어떤 관심사를 갖고 있는지, 또 다른 어떤 것과 어떻게 관계를 맺고 있는지를 수학의 원리인 행렬로 계산해 낸다”고 설명했다. 구글 지식그래프 검색에서 ‘엔터티’라는 개념은 매우 중요하다. 컴퓨터 사이언스에서 엔터티는 ‘실체’라는 의미인데 정보학의 관점에서는 의미있는 정보의 단위 또는 두 개 이상의 속성과 의미를 지닌 집합이다. 여러 의미나 속성을 지닌 엔터티(여기서는 검색 키워드)의 연관된 의미를 찾아나서는 여정이 바로 구글 지식그래프의 시작이다. 이를 실제 검색에 적용해 보면 이렇다.
해당 키워드로 검색한 사용자가 그 검색어와 관련해서 어떤 내용을 담은 웹문서를 참조했는지를 데이터베이스로 만들어 사용자의 의도를 파악한다. 사용자의 웹활동을 수학적으로 분석하는 집단지성을 이용하는 것이다. 나아가 집단지성과 웹에서 인공지능(AI)의 단초를 제시할 수 있다는 게 구글의 비전이다.
구글 본사에서 만난 곰스 부사장은 “사람들의 관심사는 무척 다양하기 때문에 각 주제별로 데이터베이스를 만들어 서로 통합하고 연결해, 연산하는 과정을 거쳐야 한다”며 “최적의 결과를 순간적으로 계산해 자동으로 제공하는 것이 핵심”이라고 설명했다. 전현직 뉴욕시장에 대한 지식그래프 검색 결과가 다른 이유도 현 뉴욕시장은 많은 재산이 관심사이지만 전 시장은 그렇지 않기 때문이다.
지식그래프 검색은 검색어간의 관계도 보여줄 수 있다. 위대한 과학자 퀴리 부인을 검색하면 기본적인 정보 외에도 남편인 피에르 퀴리와 2명의 자식 중 한 명도 노벨상을 받았다는 내용까지 자동으로 제시된다. 구글은 지식그래프 서비스를 위해 5억 개 이상의 인물, 지명, 사건 관련 정보를 확보했다.
우리나라에선 배우나 가수, 앨범, 영화, TV프로그램, 게임, 요리법, IT용어, 대학, 국가 등 10개 카테고리에서만 제한적으로 지식그래프
서비스가 이뤄지고 있다. 왜 그럴까. 우리나라 사람들은 짧은 키워드를 선호하기 때문에 각 키워드가 어떤 의미를 갖고 있는지, 해당 키워드를 검색한 사용자의 의도가 정확히 무엇인지 데이터베이스로 확보하는 데 시간이 많이 걸린다.


‘구글 번역기는 단어 뜻도 모른다.’
언어를 이해하고 지식 정보를 이해하는 것. 웹에 흩어져 있는 인류가 만든 지식정보에 접근하고 원하는 결과를 찾는 데는 필수적이다. 그런데 구글 번역기가 개별 단어의 뜻도 모른다니… 무슨 말일까.
구글 번역 개발 업무를 총괄하고 있는 맥더프 휴즈 엔지니어링 디렉터는 “2006년부터 오랜 기간 동안 각종 리서치와 실험을 진행했다”며 “번역의 핵심은 사전을 찾는 것이 아니라 통계적 기법에 의한 데이터 과학에서 찾을 수 있다”고 설명했다. 사실 구글 번역기는 단어의 의미를 신경쓰지 않는다. 이미 번역된 수많은 웹문서에서 번역의 힌트를 얻는다.
우선 구글이 보유한 어마어마한 컴퓨팅 자원을 이용해 눈 깜빡할 사이에 웹문서를 훑고 웹문서에 쓰여진 글자를 분석한다. 유엔이나 EU 등 국제기구의 다중언어 자료집, 국제재판소나 다국적기업이 사용하는 다중 언어 계약서, 개인·도서관·출판사·작가·학술 자료 등에서 나오는 모든 문서가 바탕이 된다. 이미 사람들이 번역해 놓은 문서를 통해 해당 어휘들이 어떻게 번역됐는지 데이터베이스로 만들고 그 토대 위에 기계적, 수학적 메커니즘으로 구글 번역이 이뤄지는 것이다. 그렇다면 쌍을 이루는 웹문서를 어떻게 찾을 수 있을까. 휴즈 디렉터는 “웹페이지의 나머지 주소가 똑같은데 ‘~.com/en~’ 또는 ‘~.com/ko~’인 두 문서가 확률적으로 같은 내용일 가능성이 높다”고 말했다. 그는 “그밖에 단어나 심볼, 날짜나 숫자, 유명인 이름(오바마, Obama) 등이 각 문서의 비슷한 위치에 존재한다면 같은 내용의 문서일 것이라는 추측으로 이뤄지지만 대단히 힘든 작업”이라고 덧붙였다.
같은 단어인데 다양한 의미를 지니거나(rose : 장미 또는 rise의 과거형), 서로 다른 단어가 모여 전혀 다른 의미를 지니는(raining cats and dogs : 억수 같이 비가 내리는) 어구는 어떻게 알아낼까.
이 때는 단어 주변에 반복적으로 나오는 단어에 주목한다. 장미의 경우 ‘a rose’처럼 ‘rose’ 앞에 ‘a’가 있는 경우는 장미로, ‘My wife rose from her chair’와 같은 어구가 반복될 경우 ‘rise’의 과거형으로 인식하도록 데이터베이스를 구축하는 방식이다.

영화 스타트렉에서 우주 전함을 탄 등장인물들은 컴퓨터에 대고 “가장 최근에 접촉한 외계 행성의 대기 밀도에서 주목할 만한 점은?” “1940년대 뉴욕의 일상복 디자인은?”과 같은 질문을 던진다. 구글 검색은 이런 질문에 답을 제시할 수 있을까. 스타트렉에서 주인공들이 컴퓨터와 대화하는 기술을 만드는 게 목표라는 벤 곰스 구글 부사장은 “구글 지식그래프는 아직 ‘유아기’에 불과하다”며 “자연어 질문을 이제야 이해하기 시작한 단계”라고 말했다.
하지만 곰스 부사장은 “인공지능의 걸림돌은 음성 인식, 자연어 이해, 번역 등이었는데 모두 해결의 실마리를 보이고 있다”고 덧붙였다. 구글의 ‘엔터티’ 기반 검색 알고리듬은 미래 로봇에도 적용될 수 있다. 만일 ‘아이 돌보미 로봇’이 있다면 로봇은 이미 아이가 항상 배고프고 연약하다는 것을 웹을 통해 배운다. ‘항상 배고픈’이라는 문맥이 ‘아이’와 의미가 연결되어 있기 때문이다. 언제쯤이면 스타트렉에서 나오는 컴퓨터와의 대화가 가능해질까.
▼관련기사를 계속 보시려면?
PART 1. 검색은 김수현(작가, 탤런트)을 구분할 수 있을까
PART 2. Sixth Sense Mobile!
PART 3. 구글의 눈으로 보는 세상
PART 4. 구글 in Science











