“규정 타석을 만족시키는 타자 수가 연간 30~40명에 불과해요.”
“생각보다 ‘빅데이터’가 아니네요?”
지난 3월 10일 토요일 오전 서울 신사동의 한 옥탑방. 이곳에 모인 12명의 사람들이 의외라는 표정을 지었다. 엑셀로 그린 그래프를 살펴보던 중이었다.
“그래도 자료를 여러 사람이 나눠서 검증하니 공동 연구의 의의가 있지요.”
이들은 정재승 KAIST 바이오및뇌공학과 교수와 트위터를 통해 모인 ‘백인천프로젝트’ 멤버들. 올해 30주년을 맞은 한국 프로야구의 역사를 데이터를 통해 분석한 뒤 이를 과학논문으로 완성해보자는 집단지성 프로젝트를 수행하는 중이다. 호텔 매니저, 건축가, 의사, 대학원생, 법률가, 엔지니어, 기자 등 전문 과학자가 아닌 사람들 50여 명이 참여해 데이터를 모으고 분석해 논문을 쓰는 작업을 함께 하고 있다.
이들의 목표는 한국판 ‘굴드 보고서’를 만드는 것. 미국의 진화생물학자 스티븐 제이 굴드가 저서 ‘풀하우스’에서 제기한 “프로야구에서 왜 4할 타자가 사라졌는가”라는 질문을 한국 야구 데이터를 이용해 답해 보는 것이다. 굴드는 “계(시스템)가 안정화되면 변이가 줄어들어 튀는 기록이 사라진다”며 “미국 프로야구 역시 안정화에 접어들기 전엔 4할 타자라는 튀는 기록이 있었지만, 이후 기량이 상향 평준화되며 안정돼 4할 타자가 나타나지 않았다”고 설명했다. 한국 역시 프로야구 출범 첫 해인 1982년 백인천 당시 MBC 청룡 선수가 단 한 번 4할 1푼 2리를 기록한 이후 4할 타자가 사라졌다.
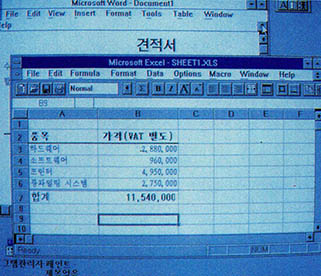
이 날 오후, 참가자들은 메일을 한 통씩 받았다. 메일에는 엑셀 파일 두 개와 PDF 파일이 하나 있었다. 각각 타자와 투수의 30년치 기록 데이터와 한국야구협회(KBO)의 공식 연감이었다. 엑셀 파일은 프로젝트에 참여한 야구 블로거 오원기 씨가 수집한 데이터 초안이다. 투수 기록 11만 4496개, 타자 기록 16만 7994개가 항목별로 빼곡하게 입력된 귀한 자료였다.
50여 명의 참여자 전원이 데이터를 나눠 맡아 일일이 확인하기로 했다. 사람에 따라 수천~수만 개의 데이터를 확인했다. 기자도 가나다 순으로 이성열 타자의 2005년 기록부터 이연수 타자의 1995년 기록까지 2781개 항목을 대조했다. 각자가 집에서 자신의 컴퓨터를 이용해 한 이 작업은 3월 12일 오원기씨가 취합하며 완전히 끝났다.
백인천프로젝트는 비전문가가 모인 집단지성 프로젝트답게 느리지만 착실히, 자발적으로 진행되고 있다. 결과는 4월 프로야구 시즌 개막 이후에 발표될 예정이다.

[3월 10일 서울 신사동에 위치한 정재승 교수 개인 연구실에서 ‘백인천프로젝트’ 참가자 일부가 모여 논문 방향을 논의하고 있다. SNS를 통해 자발적으로 모인 사람들이 자율적으로 데이터를 수집하고 분석해 논문을 쓴다.]

웰컴 투 데이터유니버스! 데이터의 공습
일상에서 생산되는 데이터의 양은 웹과 모바일 환경이 발전하면서 더욱 많아졌다. 지난 1월부터 시작된 미국 공화당 대선후보 경선은 소셜네트워크서비스(SNS) 상에서도 수많은 데이터를 만들고 있다. 아무리 정치에 관심이 없는 사람도 선거철이 되면 후보에 대해 한두 마디 말을 하게 마련이다. 미국도 예외는 아니어서 주별 경선을 거듭할수록 지지하거나 반대하는 후보에 대한 말이 늘어난다. 이런 경향은 SNS에서도 똑같다. 트위터 본사가 경선 후보가 들어간 트윗 문장을 추출한 결과를 보면, 많을 땐 하루 한 후보에 대해 31만 건의 문장이 생산된다. 무척 많은 데이터지만, 트위터에서 하루 생산되는 문장 1억7700만 건(2011년 3월 기준)의 0.17%에 불과하다.
의료 기록은 환자의 여러 가지 질병 정보가 담겨 있는 복잡한 데이터다. 정하웅 KAIST 물리학과 교수는 “의료보험 진료 기록을 이용하면 질병과 사람 사이의 네트워크 관계를 규명할 수 있다”고 말했다. 하지만 의료 데이터는 환자의 개인정보에 속하기 때문에 연구에 어려움을 겪고 있다. 해외에는 사례가있다. 알베르트-라즐로 바라바시 미국 노스이스턴대 교수가 2009년 미국 노년층 건강보험(메디케어)의 공식 진료 기록을 연구한 사례가 대표적이다. 이 때 사용된 기록 수는 1993년까지 누적된 3억 2341만 1348건이다. 진료 기록하나의 용량을 1KB로만 잡아도(실제로는 이보다 훨씬 크다) 323GB에 달하는 방대한 양이다.
18대 국회의원 등 우리나라 정치인들의 홈페이지 가운데 가장 데이터가 많은 후보는 얼마나 많은 자료를 담고 있을까. 4GB(약 41억 바이트)다. 사람 1명이 지니고 있는 염기 서열 데이터량(30억 쌍 또는 60억 개, 1개를 1바이트로 보면 6GB)보다 약간 작은 수다. 60억 염기서열은 1초에 하나씩 한 번 읽기만 하는 데도 90년이 걸리는 빅데이터다.
하늘로 눈을 돌려보자. 우주 전체를 디지털 데이터로 만드는 ‘슬론 디지털 우주 조사(SDSS)’ 프로젝트는 하루 200GB의 천문 데이터를 생산하고 있다. 책은 어떨까. 전세계의 디지털 책에서 사용된 단어 중 2010년 12월 구글이 분석한 것만 모아도 5000억개가 넘는다. 하지만 전 세계 책의 4%에 불과하다. 디지털화되지 않은 책 데이터는 더 크다. 미국국회도서관이 보유한 책은 데이터로 환산하면 14TB(테라바이트, 14조 바이트)에 이른다. 하지만 이조차 전 세계 책의 극히 일부다.

제2유니버스 데이터사이언스의 반격
데이터가 점점 커지면서 데이터를 읽고 분석하고 저장하는 데 문제가 생겼다. 데이터를 생산하는 기술의 발전 속도가 분석이나 저장에 필요한 기술의 발전 속도보다 빠르기 때문이다. 대표적인 분야가 게노믹스다. 미국의 바이오기업 일루미나의 스콧 칸 박사는 2011년 2월 ‘사이언스’ 기고문에서 “2007년에 이미 하루에 읽을 수 있는 유전자 염기서열 데이터량이 컴퓨터의 처리 속도는 물론 하드디스크의 저장 능력을 넘어섰다”고 밝히고 있다. 김태형 테라젠바이오연구소 유전체 사업부장은 “염기서열 해독에 1달이 걸리면 분석에 1년이 걸리는 식으로 데이터 처리 병목 현상이 심하다”고 말했다.
병목 현상은 데이터를 다루는 과학자들이 꼭 해결해야 할 문제다. 김 부장은 국립암센터에서 진행 중인 위암 발병인자 연구를 예로 들었다.
“위암 환자 20명에게서 정상세포와 암세포를 얻어 유전체를 분석하는데 이 과정에서 약 4조 개의 염기서열 정보가 생산됩니다. 이 데이터를 서로 교차 비교해서 위암 유전자를 1~2개 찾아내는데, 치료와 예방에 중요하게 씁니다.”
이런 방대한 계산을 값싸고 빠르게 하는 것이 생명정보학이다. 테라젠바이오연구소도 컴퓨터 등 생명정보학 전문가가 전체 인원의 절반을 넘어서고 있다. 그 덕분에 유전자 분석에 특화된 빠르고 값싼 병렬컴퓨터를 만드는 데에 성공해 상용화를 앞두고 있다. ‘엑소믹스’라고 이름 붙인 이 시스템은 그래픽카드 1792개를 병렬 연결해 수백 개의 CPU를 지닌 슈퍼컴퓨터 못지 않은 처리속도를 낸다.
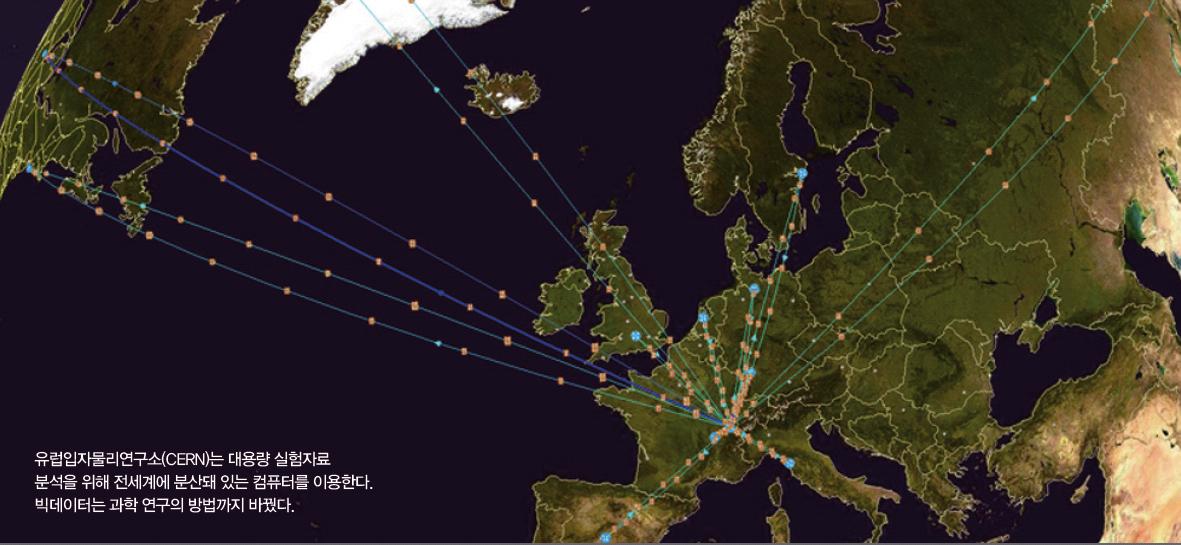
2000년대 초, 유럽입자물리연구소(CERN)에서는 이미 컴퓨터의 분석 속도가 대용량의 실험 데이터를 따라가지 못한다는 문제가 제기됐다. 그래서 데이터를 여러곳의 컴퓨터에서 나눠서 계산하는 새로운 계산 방식을 개발했다. CERN은 지금도 거대강입자가속기(LHC)의 네 개 검출기에서 생산되는 매해 13PB(페타바이트, 1015바이트) 분량의 데이터를 세계 34개국에 퍼져 있는 20만개 CPU에 나눠서 계산하고 있다. 데이터는 CPU와 함께 분산해 놓은 150PB 저장장치에 나눠서 저장된다.
빅데이터는 연구 방식도 바꿨다. 백인천프로젝트를 예로 들어보자. 이 프로젝트는 연구 초기에 논문의 구체적인 주제를 미리 정하지 않았다. 대신 “굴드가 던진 질문을 검증한다”는 목표를 느슨하게 정해뒀다. 이후 직접 데이터를 가공해가며 연구 방향을 잡아나갔다. 이런 새로운 연구 패러다임을 ‘데이터 기반 연구’라고 부른다.
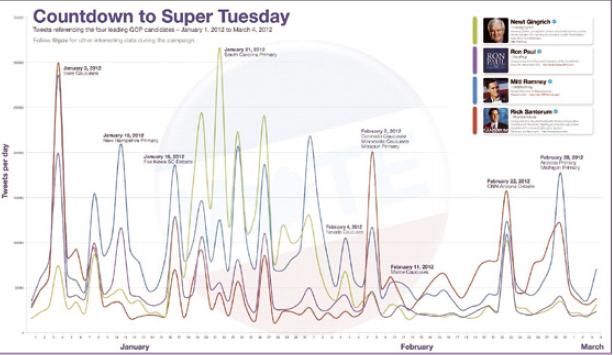
[트위터 본사에서 수집한 미국 공화당 경선 주요 후보들의 트윗 수 변화. 후반으로 갈수록 롬니 후보(파란 선, 아래 사진)와 샌토럼 후보(빨간 선)의 선전이 두드러진다.]


제3유니버스 데이터 재공습
데이터과학의 대응은 여기서 그치지 않는다. 세계에서 가장 빠른 슈퍼컴퓨터(일본 이화학연구소 ‘케이’ 컴퓨터)는 1초에 1경 회의 연산을 수행할 수 있다. 인간도 가세했다. 슈퍼컴퓨터보다 뛰어난 데이터 처리 컴퓨터, 즉 인간의 두뇌는 초속 10경 번의 연산을 할 수 있다.
하지만 지구에서 만들어지고 있는 데이터의 양도 갈수록 만만치 않다. 2010년 전세계에서 만들어진 데이터는 12.5해 바이트(해는 경의 1000배, 1.25ZB, 제타바이트=1021)에 이른다. 1년 뒤인 작년에는 50%가 더 늘어 18해 바이트(1.8ZB)를 넘어섰다.
다행히 두뇌가 만든 데이터는 아직 인류가 처리한 데이터보다는 적다. 320만 년 전 오스트랄로 피테쿠스 ‘루시’가 태어난 이후 인류의 두뇌 속 시냅스는 1035번이라는 무시무시하게 많은 계산을 했다. 당분간 지구에서 아무리 많은 데이터가 만들어져도 이보다 큰 수는 아닐 것 같다.
하지만 우주로 시선을 돌리면 얘기가 달라진다. 최신 물리학 이론인 홀로그래피 이론에 따르면, 블랙홀의 표면에는 상상할 수 있는 가장 작은 정보가 가장 압축된 형태로 기록될 수 있다. 물리학자들은 반지름이 0.5m인, 눈사람 몸통만 한 구를 블랙홀로 만들면 그 경계면(사상의 지평선)에는 1057바이트의 정보가 저장된다고 주장한다(정확히는 비트지만 이 정도 빅데이터에서는 차이가 없다).
블랙홀이 비현실적이라면 일상적인 물질과 에너지 속에서 만들어질 수 있는 모든 데이터의 양을 계산해 보자. 양자컴퓨터의 기본 단위가 되는 입자(양자)의 양을 계산한 뒤 이들이 우주공간에서 무작위적으로 배열될 경우의 수를 찾으면 된다. 그 값은 자그마치 10을 10122번 제곱한 수다. 이론적으로 우리 우주 안에는 이만큼의 데이터(정보)가 만들어질 수 있다. 우주는 곧 데이터다.
이제 아득한 데이터유니버스의 끝이 보이는 것 같다. 하지만 마지막의 마지막이 하나 남았다. 우주가 여럿 존재할 수 있다는 다중우주론이다. 이 이론 중 하나인 풍경우주론에 따르면 이런 우주가 자그마치 10500개 존재한다. 보다 극단적인 버전으로 데이터유니버스 여행을 끝내자. 인플레이션 다중우주론에서는 우리 우주만큼의 데이터를 담은 우주가 ‘무한 개’ 존재한다!
▼관련기사를 계속 보시려면?
Intro. WELCOME TO 데이터유니버스
Part1. 왜 4할 타자가 사라졌을까
Part2. 2012 세상을 바꿀 빅데이터 5