50년의 난제를 풀었다니, 알파폴드2는 정말 대단한 일을 해낸 거군요. 도대체 알파폴드2는 어떻게 단백질의 구조를 예측한 걸까요?
단백질은 ‘글리신’, ‘히스티딘’ 등 보통 20가지의 아미노산 250~300개가 실에 꿴 구슬처럼 길게 연결돼 만들어져요. 아미노산은 종류에 따라 다른 화학적 특성을 가지는데, 그중 중요한 특성은 ‘물과 친하냐’는 거예요. 예를 들어 ‘류신’은 물을 싫어하는 ‘소수성 아미노산’이고, ‘라이신’은 물을 좋아하는 ‘친수성 아미노산’이지요. 세포 내부는 물로 가득 차 있으니, 소수성 아미노산들은 물과 만나는 면적을 줄이기 위해 서로 덩어리를 이루어 뭉쳐요. 친수성 아미노산들은 소수성 아미노산을 둘러싸지요. 이 과정에서 아미노산 사슬이 가장 안정한 상태를 찾을 때까지 접히며 단백질이 만들어져요.
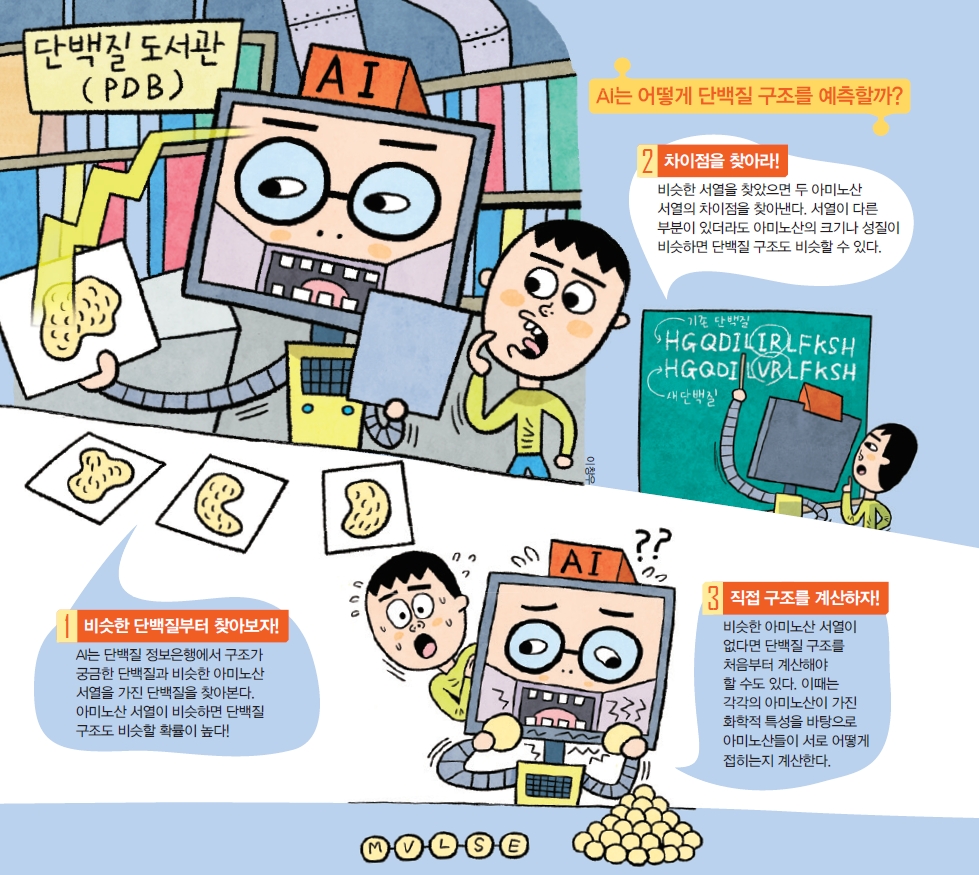
그런데 아미노산 하나하나가 어떻게 접혀서 단백질이 만들어지는지 알아보기는 힘들어요. 엄청난 계산을 동원해야 해서 실제로는 거의 불가능하죠. 그래서 인공지능은 먼저, ‘이미 그 구조가 밝혀진 단백질의 아미노산 서열’ 중에서 ‘구조를 찾으려는 단백질의 아미노산 서열’과 비슷한 서열이 있는지 찾아봐요. 약 17만 종의 단백질 정보가 수록된 ‘단백질 정보은행’등에 지금까지 밝혀진 단백질과 서열 정보가 이미 저장되어 있거든요. 아미노산의 서열이 비슷하다는 것은 기능이나 구조도 비슷하다는 점을 뜻해요.
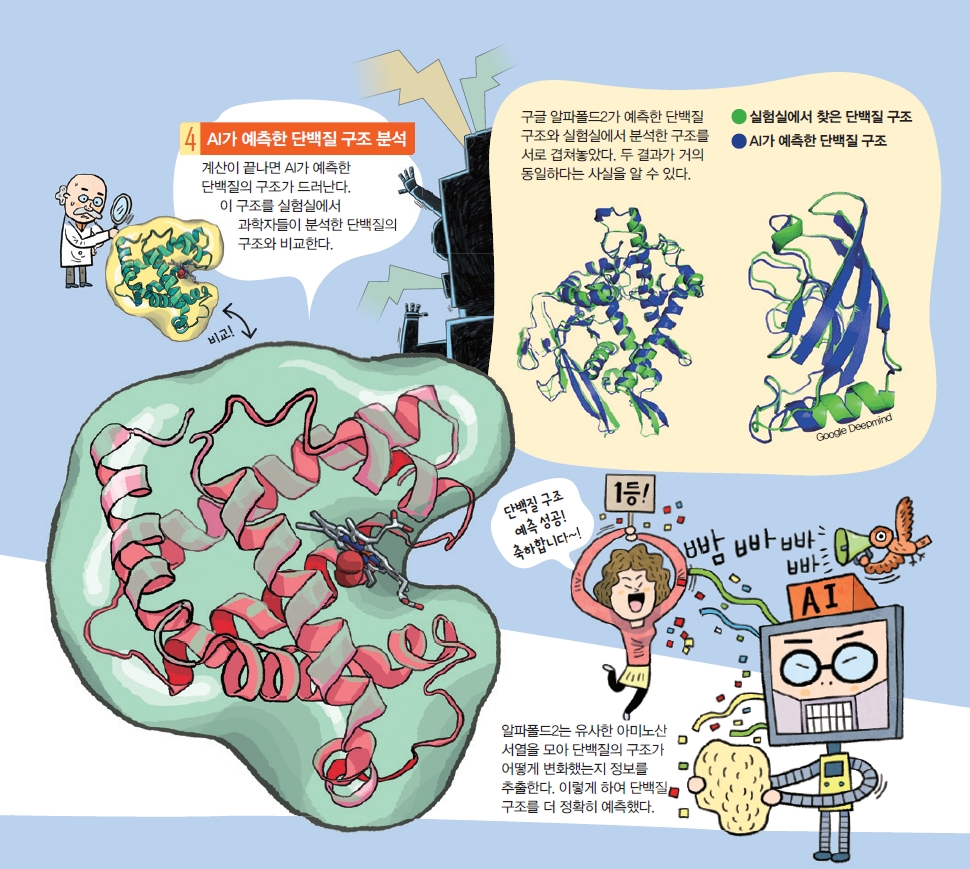
알파폴드2는 비슷한 아미노산 서열을 최대한 많이 찾아봐요. 비슷한 아미노산 서열을 많이 찾을수록, 단백질이 어떻게 변화했는지 파악해서 찾으려는 단백질의 구조를 예측하기 더 쉽거든요. 이를 위해 알파폴드2는 수억 개의 단백질과 아미노산 서열 자료를 학습했어요. 그 후 비슷한 아미노산 서열을 찾으면 그 데이터를 인공지능에 입력해 단백질 구조를 예측하지요. 또한, 알파폴드2는 학습한 단백질 자료를 바탕으로 아미노산끼리의 상호작용도 더 정확하게 예측할 수 있답니다.


.jpg)