2003년 4월 14일, 인간 유전체 프로젝트(HGP)를 진행해온 인간 유전체 컨소시엄은 “근본적으로 완전한 인간의 유전체 염기서열 분석을 완료했다”고 발표했다. 발표문에서 그들은 “완성된 서열은 인간 유전체의 유전자 포함 영역 중 약 99%이며, 99.99%의 정확도로 분석됐다”고 밝혔다. 사상 처음으로 인간 유전체 전체 염기서열이 분석된 것이다. 그러나 사실 당시 HGP가 분석한 유전체에는 채워야 할 ‘틈’ 8%가 남아있었다. 무엇이 틈이었을까.
01
완성? 인간 유전체 프로젝트는 시작에 불과했다
인간 유전체 프로젝트(HGP)는 미래 유전학 연구에 쓰일 ‘참조 유전체(reference genome)’, 즉 인간 종을 대표하는 하나의 가상 염기서열을 만드는 과정이었다. 그런데 HGP가 서열 분석 완성을 향해ㅁ 달려가면서, 더 많은 유전체 연구가 필요하다는 점이 명백해졌다.
첫 번째 이유는 이 유전체에 사람들의 다양한 유전적 변이가 담기지 않았기 때문이다. 혈액형이나 머리카락 색깔처럼, 인간은 개성있는 모습을 갖는다. 이 개성은 사람들 사이의 작은 유전적 변이로 생긴다. 어떤 변이가 혈액형과 머리카락 색깔 등을 결정하는지 알려면 한 명 분량의 참조 유전체로는 충분하지 않다. 수많은 사람들의 유전체를 분석해서 어디에서 유전자의 변이가 나타나는지 알아야 하기 때문이다.
두 번째 이유는 HGP로 만들어진 참조 유전체 자체가 정확하지 않다는 점이었다. 앞서 언급한 ‘인간 유전체의 유전자 포함 영역 중 99%의 염기 열을 알아냈으나, 틈 8%가 남아 있었다’는 모순적인 표현의 비밀은 ‘인간 유전체의 유전자 포함 영역’이라는 문구에 있다. 전체 유전체 중에서 유전자가 포함되지 않은 영역은 염기서열이 덜 분석됐던 것이다.
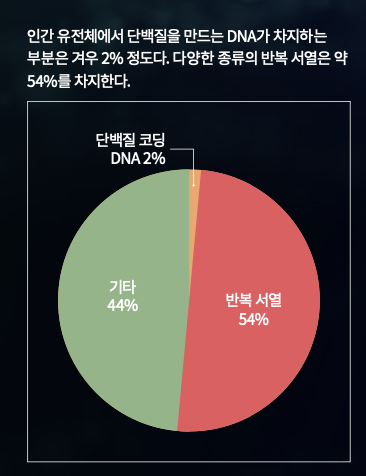
사람이 가지고 있는 유전 물질인 DNA 모두에 유전 정보가 들어있는 건 아니다. 그러니까, 염기서열 31억 개에 단백질을 만드는 유전자들이 종류별로, 기능별로 도서관 책장처럼 깔끔하게 정리돼 있지 않다는 뜻이다. 실제로 DNA 중에서는 단백질을 만들지는 않지만 단백질을 만드는 유전자의 발현만 조절하는 부위가 있다. 또 대를 이어 복제를 거듭하면서 퇴화해 자리만 차지하는 부위도 있다. 의미없는 서열이 반복되는 부위도 있다. 심지어는 바이러스에게서 주입된 DNA도 있다. 이처럼 유전체는 깔끔과는 거리가 먼, 진화의 흔적이 담긴 난장판에 가깝다. 도서관 책장보다는 시험 기간 여러분의 책상에 더 가까운 셈이다.
HGP를 통해 분석된 사실 중 하나는 단백질을 만드는 인간의 유전자 수가 생각보다 적다는 점이었다. 현재 밝혀진 인간의 총 유전자 수는 약 2만 개로, 31억 개에 달하는 DNA 염기서열 중 겨우 1.5~2% 정도를 차지한다. 98%가 넘는 나머지 DNA는 단백질을 만들지 않는다. 염기서열 중 순위가 밀린 부위, 분석이 특히 어려운 부위가 이곳에 있었다.
02
최대 난관은 반복서열 해독

“염기서열에서 분석이 가장 힘든 부분은 ‘반복 서열’입니다. 이제까지 제대로 해독되지 않은 대부분의 염기서열이 반복 서열이라 봐도 될 정도예요.”
10월 25일, 이아랑 미국 인간유전체연구소(NHGRI) 연구원은 과학동아와의 화상 인터뷰를 통해 HGP에서 왜 8%의 염기서열을 한동안 분석하지 못했는지 설명했다. 학부에서 컴퓨터공학을 전공한 이 연구원은 현재 NHGRI를 중심으로 세계 33개 기관이 참여한 ‘텔로미어 투 텔로미어(T2T) 컨소시엄’에서 유전체 분석 기술 연구를 진행하고 있다.
컴퓨터공학 전공이 인상적이라 말하니, “31억 개에 달하는 DNA 염기서열 자체가 빅데이터”라며 “생물정보학은 컴퓨터의 도움 없이는 돌아가지 않는다”고 말했다. 직접 유전 물질을 만지는 모습을 상상했다면 아쉽지만, 주로 하는 일도 유전체 분석 프로그래밍으로 거의 모니터만 들여다본다고 했다.
이 연구원이 서열 분석의 장애물로 언급한 반복 서열은 말그대로 특정 염기서열이 반복적으로 나타나는 부분을 의미한다. 염기 몇 개에 이르는 짧은 서열부터 유전자 하나를 통째로 담을 정도로 긴 서열까지, 특정 서열이 여러 번 나타나는 것이다.
반복 서열이 왜 장애물일까? 한 생물의 유전체를 분석하는 과정은 크게 네 단계로 이뤄진다. 첫 번째, 분석하려는 생물체의 DNA를 추출한다. 이 DNA는 염색체나 종류별로 구분된 상태가 아닌, 전체 DNA가 뒤섞인 잡탕 상태다. 두 번째, 이 많은 DNA를 한 번에 검사할 수는 없으니 DNA를 물리적 충격이나 자르는 효소를 이용해 적당한 길이로 자른다. 세 번째, 짧게 잘린 DNA 조각을 복제해 양을 불린 다음, 각 DNA 조각의 염기를 하나씩 읽는다. 염기를 읽는 방법은 매우 다양한데, 염기 하나하나에 형광 물질을 부착하고 색깔 순서대로 빛을 검사하거나 염기가 화학 반응을 일으킬 때 나오는 미세한 전류를 측정하는 방법 등이 있다. 네 번째, 이렇게 밝혀낸 DNA 조각의 염기서열을 모아 서로 겹치는 부분을 이어 조합한다. 이런 ‘유전체 조립’ 과정을 거치면 전체 DNA 서열을 알아낼 수 있다.
간단하게 들리지만, HGP 시절에는 각 단계마다 엄청난 비용과 노력이 들었다. 특히 반복 서열은 마지막 유전체 조립 단계에서 문제가 됐다. 짧게 자른 DNA를 다시 조합해서 분석할 때, 해당 반복 서열이 10번 반복되는지 100번 반복되는지 1000번 이상 반복되는지 컴퓨터로도 계산하기 어렵기 때문이다.
03
반복 서열을 극복할기술을 개발하다

심지어 반복 서열은 전체 유전체의 절반 가량을 차지할 정도로 양이 많았다. “X염색체나 Y염색체 같은 성염색체, 또는 동원체나 이질염색질과 같은 염색체의 특정 부위에 반복 서열이 모여있는 경우가 많아요. 2003년까지 해독이 덜된 8% 유전체의 대부분이 이런 부위의 반복 서열이었습니다.” 이 연구원의 설명이다.
이 연구원은 “HGP가 완료된 이후 2000년대 후반은 유전체 정밀 분석의 정체기”였다고 회고했다. 염기서열 분석에 드는 비용은 저렴해졌지만, 염기서열을 이전보다 더 정밀하게 분석하는 기술은 답보 상태에 머물렀기 때문이다. 이 연구원은 “이 시기 유전체학을 떠나는 학자도 생겼다”고 말했다.
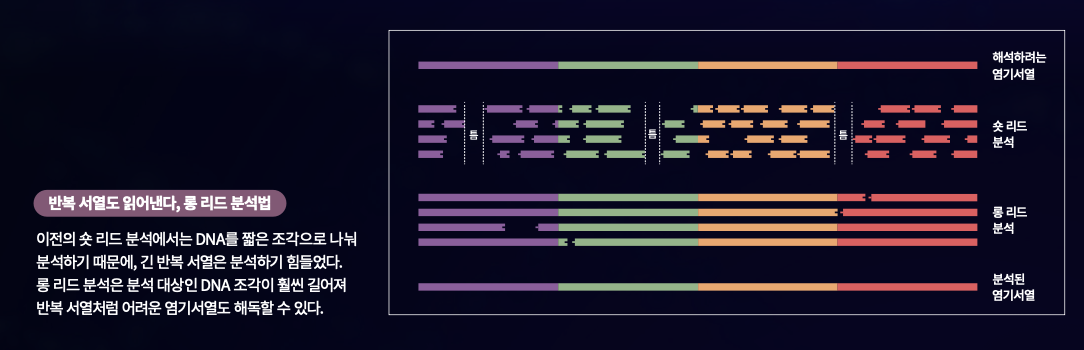
침체된 분위기는 2010년대 혁신적 분석 기술들이 등장하면서 개선되기 시작했다. 2010년대 초반, ‘3세대’로 불리는 염기서열 분석법들이 등장했다. 생명공학 기업 ‘퍼시픽 바이오사이언스’와 ‘옥스포드 나노포어 테크놀로지’, 두 회사의 기술로 대표되는 3세대 분석법은 ‘롱 리드(long-read)’ 분석법이라고도 불린다. 많아봤자 100~500개 정도의 염기를 읽어내던 이전 기술들보다 훨씬 긴 염기서열을 한 번에 읽을 수 있기 때문이다. 예를 들어 옥스포드 나노포어 테크놀로지는 나노미터 크기의 구멍에 DNA를 통과시키면서 발생하는 전기 신호를 판독하는데, 무려 100만 개에 달하는 염기서열을 읽을 수 있었다.
이 기술을 통해 반복 서열을 해독할 돌파구가 생겼다. 서열을 읽을 DNA를 조각낼 때, 반복 서열을 포함한 긴 길이로 자르고 이후에 조합하면 반복 서열도 읽어낼 수 있었다. 이 연구원이 몸담은 T2T 컨소시엄에서는 2010년대 후반부터 이 기술들을 사용해서 지금까지 미답의 고지로 남겨져있던 인간 유전체의 8%를 분석하기 시작했다.
04
인간 유전체의 마지막틈을 메우다

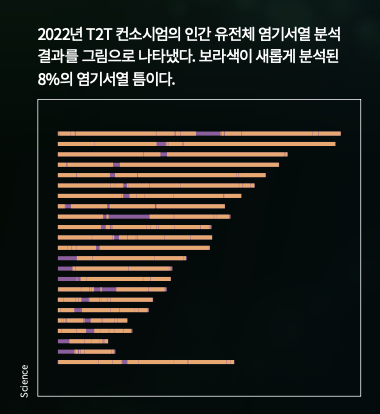
2020년, T2T 컨소시엄은 새롭게 수정된 X 염색체 염기서열 분석 결과를 발표했다. doi: 10.1038/s41586-020-2547-7 2022년에는 더 중요한 연구가 나왔다. 8%의 ‘틈’으로 여겨졌던 염기서열을 분석한 것이다. doi: 10.1126/science.abj6987 T2T 컨소시엄 연구팀은 여러 3세대 염기서열 분석법을 이용해 반복 서열들, 특히 분석되지 못했던 염색체의 짧은 팔 부위와 동원체 영역을 분석했다. 수정하거나 새로 분석한 염기만 2억 3800만 개. 여기에는 약 1956개의 유전자가 들어있을 것으로 추정됐다.
유전체 연구자들의 마지막 성배는 ‘Y 염색체’였다. 인간 남성에게 나타나는 성염색체인 Y 염색체는 유전체 분석 목표 중에서도 난이도가 높기로 악명이 높았다. 짧은 반복 서열은 물론 긴 반복 서열, DNA 염기서열이 역방향으로 반복돼 ‘토마토’ ‘기러기’처럼 앞으로 읽으나 뒤로 읽으나 똑같은 ‘회문’ 배열까지 해독 난이도 최상급의 반복 서열이 모여 있었기 때문이다. 2023년 8월, T2T 컨소시엄은 기존 Y 염색체의 오류를 수정하고 3000만 개의 염기서열을 추가한 분석 결과를 발표했다. doi: 10.1038/s41586-023-06457-y 새롭게 해석된 염기서열에서는 41개의 단백질 유전자가 추가로 발견됐다. 2003년 이후 20년 간 진행된 인간 유전체 연구의 방점을 찍는 결과라 할 만하다.
왜 굳이 이렇게까지 유전체를 정밀하게 분석해야 할까. 이 연구원은 “유전체 정밀 분석은 유전체 연구를 위한 정확한 지도를 만드는 것과 같다”고 설명했다. 모든 유전체 연구의 기반이 되기 때문에, 참조 유전체 연구는 정밀할수록 유용하다는 뜻이다.
2022년 이전까지의 유전체 연구에 쓰인 참조 유전체는 ‘게놈 레퍼런스 컨소시엄의 38번 째 인간 빌드’, 약자로 ‘GRCh38’이다. 2013년에 처음 발표되고 2022년까지 14번의 보완이 이뤄졌다. 오래 전에 발표된 만큼 부정확한 부분이 상당히 많다. 만약 병의 원인이 되는 유전자가 이 8% 범위 내에 있다면 연구가 진행되기 어려웠다.
T2T 컨소시엄 연구팀은 8%의 틈을 메운 연구를 토대로 최신 참조 유전체인 ‘T2T-CHM13’을 발표했다. 생물학자들이 유전자를 찾기 위한 더 정확한 지도가 주어진 셈이다.
05
인간을 인간답게 만드는 유전자를 찾아

2003년은 인간 유전체 프로젝트의 끝이자, 본격적인 유전체학 연구를 알리는 시작이었다. HGP를 통해 기술적 혁신을 거듭한 유전체 분석 기술은 인간 유전체 분석을 넘어 생물학 현장 구석구석에 큰 영향을 미쳤다. 더 적은 양의 시료로, 더 정확한 분석이 가능해졌기 때문이다. 물, 흙, 대기 중 먼지에 섞여있는 DNA를 검사해 생물을 찾아내는 환경 DNA(eDNA), 이미 멸종한 생물의 유전체를 재구성하는 고DNA(aDNA) 연구가 한 예다. 조그만 어금니 화석에서 멸종된 고인류 데니소바인의 존재를 밝혀내고, 바닷물 한 컵으로 멸종위기종 매너티의 존재를 찾는 연구는 발전한 유전체 분석 기술이 아니었더라면 모습을 드러내지도 못했을 것이다.
물론, 이 연구원은 “여전히 연구해야 할 불분명한 인류 염기서열은 남아있다”고 말했다. 예를 들어 13, 14, 15, 21, 22번의 다섯 개 염색체는 서로 다른 염색체임에도 중심체 가까이에 똑같은 반복 서열이 존재해서 분석이 무척 어렵다. 또한, 같은 이유로 분열 과정에서 다른 염색체끼리 붙는 등의 구조 돌연변이가 일어나기도 한다. 이 연구원은 “이 반복 서열을 더 연구하면 다운증후군 등 염색체 구조 변이로 인한 유전 질환을 이해하는 데 큰 도움이 될 것”이라고 말했다.
앞으로 인간의 유전체를 더 깊이 이해하기 위해서는 어떻게 해야 할까. 인간 밖에 답이 있을지도 모른다.
“인류 유전체를 이해하려면 인류 유전체와 비교할 수 있는 유전체를 얻는 게 좋습니다. 인간과 가장 가까운 영장류가 한 예입니다.” 10월 31일, 화상 인터뷰로 만난 유동안 미국 워싱턴대 유전체학과 연구원은 현재 ‘영장류 유전체 프로젝트(PGP・Primate Genome Project)’에서 인간과 가장 가까운 영장류의 유전체를 분석하고 있다. PGP에서 목표로 하는 유전체는 침팬지, 보노보, 고릴라, 두 종의 오랑우탄 등의 영장류와 긴팔원숭이까지 총 6종이다. “이들의 유전체를 비교 분석하면 같은 기능을 하는 유전자가 어떻게 진화해왔는지 알 수 있습니다. 이것을 이용해 궁극적으로는 어떤 유전자가 인간을 인간답게 만드는가를 알아내는 것이 목표예요.”
어떤 유전자가 인간을 인간답게 만드는가. 이 질문은 유전체학이 생물학의 범위 내에서 알아내고자 하는 답에 가깝다. 이 답을 찾을 때까지, 더 정확한 유전체 지도를 만들기 위한 노력은 계속될 것이다.