“아이고, 게임을 더 해야 시험을 잘 보지!” “책 그만 읽고 게임을 하라니까?”
게임을 좋아하는 독자라면 부모님께 이런 잔소리를 듣는, 엉뚱하지만 기분 좋은 상상을 해본 적이 있을 겁니다. 아쉽게도 실현되기 쉬운 상상은 아닙니다. 우리가 인공지능(AI)이 아니라면 말이죠.
미국 매사추세츠공대(MIT) 연구팀이 최근 게임을 이용해 AI를 똑똑하게 만들 방법을 찾았습니다.

오픈AI의 GPT, 메타의 LLaMA(라마), 구글의 BERT 등 최근 빅테크 기업에서 인간만큼 자연어를 잘 이해하는 대규모언어모델(LLM)을 속속 내놨습니다. 과거 단순했던 인공지능(AI)과 달리 자연어를 이해할 수 있는 AI인 언어모델은 AI의 두 가지 역할을 모두 해냅니다.
AI는 크게 생성과 판별의 역할을 합니다. 생성 모델은 주어진 데이터로 데이터 분포를 학습해 새로운 데이터를 만들어내고, 판별 모델은 주어진 데이터로 데이터 간 ‘경계’를 예측하고, 새로 주어진 데이터가 어느 쪽에 속하는지 판별합니다. 두 모델은 각각 그럴듯한 데이터를 만들어 낼 수도 있고, 주어진 데이터가 맞았는지 틀렸는지 평가할 수도 있습니다.
그런데 문제가 있습니다. 가끔 하나의 언어모델을 사용한 AI의 생성 모델과 판별 모델이 ‘한 입으로 두말하는’ 경우가 있거든요. 예를 들어 생성 모델을 사용하면 “미국 대통령은 누구입니까?”라는 질문에 “조 바이든”이라는 답을 쉽게 얻을 수 있습니다. 그러나 판별 모델은 “조 바이든”이라는 답변이 맞는지 평가할 때 “맞다”고 평가할 수도 있고, “조 바이든이 아니다”고 평가할 수도 있습니다. 제이콥 안드레아스 미국 매사추세츠공대(MIT) 컴퓨터과학 및 AI연구소 교수팀은 이 문제를 해결하기 위해 언어모델에 적용할 수 있는 ‘합의 게임’을 고안했습니다. doi: 10.48550/arxiv.2310.09139
더 똑똑한 언어모델을 위한 합의 게임


대체 어떤 게임을 했기에
연구팀이 고안한 합의 게임의 규칙은 꽤 간단합니다. 예를 들어 A와 B는 “과학동아 편집실은 어디에 있나요?”라는 질문 카드를 받습니다. 그리고 A는 동전을 던지죠. 만약 동전 뒷면이 나왔다면 A는 자신이 알고 있는 정답이 아닌 오답인 ‘용산’을 답합니다. 사실은 몇 달 전 과학동아는 충정로로 이사를 했는데 말이죠. B는 A의 대답을 자신이 알고 있는 내용 안에서 판단합니다. 만약 B가 A의 대답이 진실이라고 말하면 A가 거짓을 말했다는 사실을 맞히지 못했기 때문에 0점, 거짓이라고 말하면 A가 거짓을 말했다는 사실을 맞혔기 때문에 1점을 얻습니다. 꽤 단순해 보이지만 이 게임에서 점수를 얻기 위해선 A와 B 모두 정확한 정답을 알고 있어야 합니다. 두 사람이 다르게 알고 있다면 점수를 얻을 수 없죠.
연구팀은 생성 모델이 A의 역할, 판별 모델이 B의 역할을 하도록 설정하고 이들이 합의 게임을 하도록 했습니다. 생성 모델과 판별 모델은 주어진 질문에 대해 초반에는 각자 학습한 내용에 따라 답하고 판별했습니다.
앞서 설명한 예로 모델이 어떻게 합의에 이르는지 자세히 살펴봅시다. 게임 시작 전 생성 모델이 학습한 결과는 과학동아 편집실이 용산에 있을 확률이 40%, 충정로에 있을 확률이 60%이고 판별 모델이 학습한 결과는 용산 80%, 충정로 20%입니다. 판별 모델은 한번의 게임이 끝나면 학습 결과의 확률 값이 충정로 25%, 용산 75%로 바꿉니다. 이 과정을 반복해 n번의 게임 후에는 충정로가 60%, 용산이 40%로 생성 모델과 같아지는 거죠. 만약 두 모델의 정답이 같다면, 학습된 확률이 같아질 때까지 게임을 반복합니다. 생성 모델과 판별 모델이 ‘내쉬 균형’ 상태에 이르러 같은 대답을 내놓을 때까지요.
내쉬 균형은 게임 이론 중 하나로 각 플레이어가 상대방의 전략을 알게 됐을 때, 자신의 전략을 변경할 유인이 없는 상태를 뜻합니다. 합의 게임에서 생성 모델과 판별 모델은 점수를 더 많이 획득하기 위해 서로의 학습 값을 일치시키는 방향으로 전략을 세우게 되는데요. 이 과정이 반복되면서 점차 균형에 이르게 되는 거죠.
내쉬 균형을 이루는 것에는 한계도 있습니다. 생성 모델과 판별 모델이 정답과는 다른 확률로 합의에 도달할 수도 있거든요. 연구팀은 생성 모델과 판별 모델이 학습한 초기 결과에서 크게 멀어지는 상황에 벌점을 부과하는 규칙을 추가해 이런 한계를 극복했습니다.
거대 언어모델 능가하는 성능 보여
합의 게임의 성능은 어땠을까요. 연구팀은 기존의 언어모델이 사용하는 학습법, ‘퓨 샷 러닝(few shot learning)’과 합의 게임의 성능을 비교했습니다. 퓨 샷 러닝은 적은 수의 샘플로 새로운 분류 문제를 학습하는 학습법입니다. 연구팀은 메타가 개발한 언어모델인 ‘LLaMA-7B 모델’이 퓨 샷 러닝과 합의 게임으로 학습하도록 한 뒤 독해력, 상식 추론, 수학 문제 해결, 대화 등 다양한 작업에 걸쳐 성능을 평가했습니다. 그 결과 퓨 샷 러닝으로 학습한 LLaMA-7B는 대규모멀티태스킹이해(MMLU・Massive Multitask Language Understanding, 언어모델의 기능을 평가하기 위한 시험)에서 35.1%의 정확도를 보였습니다. 이에 반해 합의 게임으로 학습한 LLaMA-7B는 39.9%의 정확도를 보여 기존의 학습법을 능가했습니다.
연구팀은 합의 게임이 언어모델 개선에 얼마나 영향을 미쳤는지 확인하기 위해 LLaMA-7B(매개변수 70억 개)보다 더 많은 매개변수를 사용하는 언어모델인 ‘PaLM-540B(매개변수 540억 개)’과도 비교했습니다. 언어모델은 매개변수가 많을수록 더 여러 층에 걸쳐 학습할 수 있어 더 높은 성능을 발휘할 수 있거든요. 결과는 어땠을까요? 놀랍게도 초등학교 과학 문제를 냈을 때, 합의 게임을 플레이하지 않은 PaLM-540B 모델의 정답률은 76.6%, 합의 게임을 플레이한 LLaMA-7B 모델의 정답률은 76.4%로 거의 비슷한 성능을 보였습니다. 두 모델의 매개변수 개수 차이가 8배에 달하는데도요.
합의가 아닌 경쟁으로 똑똑해지는 생성적 대립 신경망
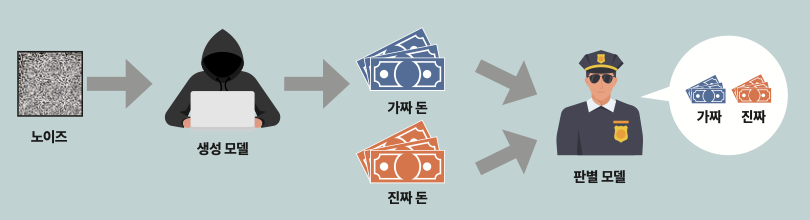
더 똑똑한 인공지능(AI)을 만들기 위해 생성 모델과 판별 모델을 결합하는 방법은 이전부터 있었습니다. 가장 대표적인 것이 생성적 대립 신경망(GAN・Generative Adversarial Network)입니다. GAN은 진짜보다 더 진짜 같은 데이터를 만들 때 사용되는 모델로, 생성 모델과 판별 모델이 서로 경쟁하며 발전합니다.
경찰과 위조지폐범으로 예를 들어 봅시다. 먼저 일정 수준으로 진짜 지폐와 가짜 지폐를 구분하는 법을 학습한 경찰이 위조지폐범이 만든 가짜 지폐를 구분하는 임무를 수행합니다. 위조지폐범은 경찰이 판별해 낸 위조지폐를 다시 진짜처럼 보이게 수정합니다. 이 과정을 여러 번 반복하며 경찰과 위조지폐범은 서로의 기술을 학습하며 위조 및 판별 기술을 고도화합니다. 그러다 위조지폐범이 만든 지폐를 경찰이 구분할 수 없는 순간까지 학습이 반복되면, 진짜보다 더 진짜 같은 지폐를 생산할 수 있는 거죠.
다만 GAN과 ‘합의 게임’의 학습 목적은 조금 다릅니다. GAN은 무작위 데이터 속에서 새로운 데이터를 생성하고자 한다면, 합의 게임은 언어모델의 일관성과 정확성을 높이는 데 집중합니다.
AI 분야, 내일은 또 어떤 연구가?
LLM 연구자들은 합의 게임의 놀라운 성능에 주목하고 있습니다. 합의 게임을 적용할 때 필요한 연산이 매우 적어, 일반적인 노트북으로도 학습할 수 있었고 시간도 몇 밀리초밖에 걸리지 않았습니다. 구글 딥마인드팀 개발 연구자인 아흐마드 베이라미는 MIT 뉴스와의 인터뷰를 통해 ‘연구팀이 새롭게 제안한 합의 게임은 언어모델에서 더 정확한 문장 생성을 위한 혁신적인 게임 이론 프레임워크”라며 “새로운 응용 프로그램 개발을 이끌 수 있는 모델”이라고 감탄했습니다.
김수현 한국과학기술연구원(KIST) 인공지능연구단 책임연구원은 “최근 AI 연구 트렌드는 휴대전화나 웨어러블 기기에 탑재할 수 있도록 작지만 성능이 좋은 모델을 만드는 쪽으로 흘러가고 있다”며 “해당 연구는 적은 매개변수를 가지고 좋은 성능을 낼 수 있다는 점에서 앞으로 활용 가능성을 기대해 볼 수 있다”고 말했습니다.
오픈AI는 2024년 4월 9일 GPT-4의 최신 버전인 GPT-4 Turbo를 발표한 지 한 달 만에 2배 더 빠르고, 가격은 절반인 GPT-4o를 발표했습니다. GPT-4o는 영어 외의 다른 언어에 대한 이해도가 확실히 높고 인간과 대화하듯 음성으로 소통할 수 있는데요. 생성 AI가 이렇게 빠른 속도로 발전할 수 있는 건 ‘합의 게임’과 같은 독창적인 연구들 덕입니다. 앞으로 또 어떤 참신한 AI 연구가 나올지, 그 연구는 또 어떻게 우리 삶을 바꿀지 기대됩니다.