5000만 한국인이 외국어 공부에서 해방될 날이 성큼 다가온 걸까. 최근 대기업들이 앞다퉈 자동통역 서비스를 내놨다. 국제전화 서비스 업체인 SK텔링크는 00700 자동통역 시범서비스를 올해 1월 시작했고, 마이크로소프트도 지난해 12월 인터넷 전화인 스카이프에서 실시간 통역을 해주는 시범서비스를 공개했다. 여기에 구글도 음성번역 애플리케이션을 출시하겠다고 밝히며 자동통역기술 경쟁에 불을 붙였다.
구약성경에 다음과 같은 이야기가 전해진다. “온 세상이 한 가지 말을 쓰고 있었다. 사람들은 의논했다. ‘어서 도시를 세우고 하늘에 닿게 탑을 쌓아 우리 이름을 날리자.’ 야훼께서 생각하셨다. ‘사람들의 말이 같아서는 안 되겠구나.’ 야훼께서 온 세상의 말을 뒤섞어 사람들을 흩으셨다고 해서 그 도시의 이름을 바벨이라고 불렀다.”
자유롭게 대화하던 과거의 기억이 남아서일까. 언어 장벽 없이 타인과 대화하고자 하는 욕구는 인류의 랜 꿈이다. 수많은 예술 작품 속에는 이런 염원을 반영한 자동통역기가 꾸준히 등장했다. 2013년 여름 900만 관객을 모은 영화 ‘설국열차’에는 남궁민수(송강호 분)가 자동통역 단말기를 쓰는 모습이 나온다. 영화 ‘스타트랙’이나 ‘은하수를 여행하는 히치하이커를 위한 안내서’에도 외계어를 만능으로 인지하는 자동통역 개념이 등장한다.
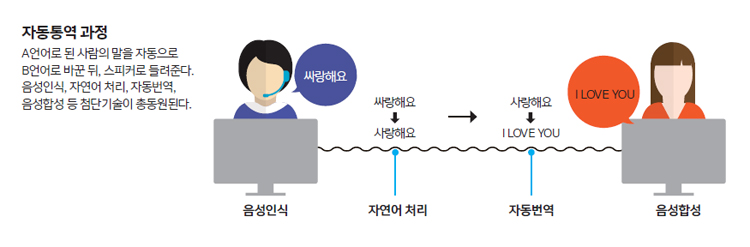
‘음성인식, 자동번역, 음성합성’ 3大 기술 총동원
자동통역은 A라는 언어로 된 사람의 말을 자동으로 다른 언어 B로 바꾼 뒤, 이를 자막으로 출력하거나 음성을 합성해 스피커로 들려주는 기술이다. 관련 연구는 20여 년 전부터 본격적으로 시작됐다. 송신자가 한 말을 문자열로 바꾸는 음성인식, 이를 수신자 언어로 바꾸는 자동번역, 그리고 번역된 문장을 읽어주는 음성합성 등 세 가지 기술이 동원된다.
중간 단계인 번역기술부터 살펴보자. 지난해 한국 전자통신연구원(ETRI) 자동통역연구실에서 발간한 ‘자동통역기술, 서비스 및 기업 동향’ 보고서에 따르면, 현재 컴퓨터 번역은 통계기반과 규칙기반 등 크게 두 가지 방식이 있다. 통계기반은 A 언어로 된 문장과 B 언어로 된 문장을 짝지은 수많은 모델 말뭉치로부터 변수를 학습해 번역하는 기술이다. 다시 말해, 사용자가 어떤 문구를 말하면 번역엔진은 기존 자료에서 비슷한 문장을 찾아내 번역문으로 제시한다. ‘눈’이라는 단어가 등장했다고 가정해보자. 하늘에서 내리는 ‘snow’일수도, 시각정보 처리 기관인 ‘eye’일 수도 있다. 이 때 통계기반의 번역엔진은 ‘눈’ 주변의 단어들을 인식해 snow와 eye 중 어떤 단어일 확률이 높은지 분석한다. 속도가 빠르고, 말뭉치만 확보하면 비교적 쉽게 다른 언어로 확장할 수 있다는 장점이 있다.
말뭉치가 많을수록 번역 정확도가 높아진다. 매일 웹에서 엄청난 양의 데이터를 모으는 구글이 자동번역에서 앞서 나가는 이유다. 한영보다 일영 번역이 더 자연스러운 것도 일영 데이터가 더 많기 때문이다. 규칙기반은 형태소를 분석해 목적 언어의 문법대로 다시 조합하는 방식이다. 예컨대, “나는 학교에 간다”는 문장을 나는/학교/에/간다/로 나눠 I/school/to/go로 바꾼 뒤, 영문법에 따라 “I go to school”로 제시하는 방식이다. 엄격한 문법을 따르기 때문에 개발은 어렵지만, 정확도를 높일 수 있다. 통역비서 애플리케이션 ‘지니톡’을 개발한 김상훈 ETRI 자동통역연구실장은 “규칙기반은 통계기반과 달리 어순이 다른 언어끼리도 수준 높은 번역이 가능하다”며 “지니톡의 한영 통역(규칙기반)도 구글 한영 번역보다 정확도가 높다”고 말했다.
SK텔링크와 합작해 업계 최초로 국제전화 자동통역 서비스를 개발한 시스트란 인터내셔널은 속도가 빠른 통계기반과 번역 정확도가 높은 규칙기반의 장점을 더한 ‘하이브리드 번역기’를 개발했다. 조창수 책임연구원은 “두 방식 모두 데이터베이스의 크기에 따라 품질이 결정된다”라며 “기업들이 앞다퉈 시범 서비스를 운영하는 것도 데이터를 축적해 번역 품질을 높이기 위해서다”라고 말했다.
이렇게 번역된 문장을 쪼개 미리 만들어 놓은 대규모 음성 DB에서 맞는 걸 가져온다. 연결했을 때 더 매끄럽거나 운율이 자연스러운 것으로 골라 이어 붙인 뒤, 스피커를 통해 출력한다. 이런 음성합성 기술은 다른 요소 기술에 비해 상대적으로 구현하기 쉽고 현재 수준도 높다. 최근에는 말한 사람의 음성과 최대한 가까운 음색을 만들거나 합성음에 감정을 싣는 기술도 연구 중이다.

2000년대 중반, 전환점 마련한 ‘딥 러닝’ 기술
“쟈기양~, 샤릉행~!”
“…인식할 수 없습니다.”
자동통역의 첫 관문은 음성인식이다. 만약 인식이 신통치 않다면 통역은 처음부터 불가능하다. 현재 이 분야의 수준은 어떨까. 조창수 연구원은 “음성인식 붐이 일었던 15년 전이나 지금이나 어려운 건 매한가지”라고 말했다. 일반적으로 사람이 말하는 대화체, 즉 ‘자연어’는 글로 쓴 문장과 다르다. 대부분 비문이다. 번역기에 들어가는 문자열부터 오류를 포함하는 셈이다. 음성인식에는 단어와 단어를 인식하는 방식, 연속적인 단어열을 인식하는 방식, 시스템에 등록된 단어만 검출해 인식하는 방식 등 다양한 기술이 있지만, 자연어 처리 문제를 해결해야 하는 건 마찬가지다. 김현성 SK텔링크 비즈혁신팀 대리는 “자연어 DB를 얼마나 갖고 있느냐에 따라 자동통번역의 전체 품질이 결정된다”고 말했다.
특히 번역엔진은 검색엔진보다 오류에 훨씬 민감하기 때문에 자동통역용 음성인식 기술은 검색용 음성인식 기술보다 정확도가 훨씬 높아야 한다. 예를 들어, 검색엔진은 오자를 입력해도 비슷한 단어를 검색해 주거나 추천 검색어를 띄워주는 데 비해 번역엔진은 아예 엉뚱한 번역문을 만들어 내놓는다. 음성인식 시스템이 사람의 말을 제대로 받아 적었더라도, 텍스트에는 포함되는 구두점, 문장부호, 대소문자 정보 등이 음성인식 결과에는 없다. 가령, “나, 간다”와 “나간다”는 띄어쓰기는 다르지만 소리 내 말해보면 비슷하다. 이를 보상하는 기술이 필요하다.
최근 음성인식 기술은 돌파구를 찾았다. 자동통역 서비스가 봇물처럼 쏟아져 나오는 이유다. 1990년대 초반만 하더라도 제한된 단어로 이뤄진 문장을 어색한 ‘낭독체’로 읽어야 했는데, 2000년대 중반 영상인식에서 출발한 ‘딥 러닝’ 기술이 전환점이 됐다. 미국의 정보기술 회사인 가트너가 2014년 주목할 만한 IT 기술로 꼽은 딥 러닝은, 데이터를 분류하는 데 쓰는 일종의 방법론이다. 컴퓨터가 훈련을 반복하면서 패턴을 찾아내 개 사진을 개로, 고양이 사진을 고양이로 판독하도록 만든다. 현재 다양한 딥 러닝 기법들이 영상인식, 음성인식, 자연어 처리, 음성·신호처리 등의 분야에 적용되고 있다.
2012년 미국 스탠포드대 앤드류 응 교수와 구글은 공동으로 ‘딥 러닝 프로젝트’를 시작했다. 이들은 1만 6000개의 컴퓨터 프로세스와 10억 개 이상의 인공신경망을 이용해 유튜브에 올라와 있는 1000만 개 이상의 비디오 가운데 고양이를 골라내는 데 성공했다. 구글과 마이크로소프트는 이미 자사의 음성검색에, 국내에서는 네이버가 음성인식 서비스에 딥 러닝을 도입했다. 이번에 개발된 SK텔링크의 00700 국제전화 자동통역 서비스에서는 음성인식과 자동번역 엔진에 이 기술이 사용됐다.
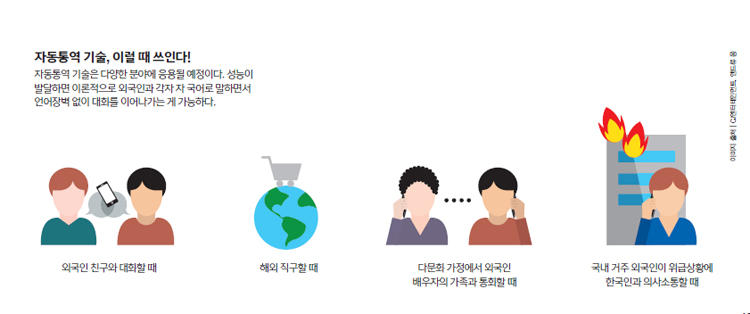

자동통역 연구하면 아이언맨 자비스 가까워진다
ETRI는 지난 4월 지니톡 시범 서비스를 종료했고, 성능을 보강해 2018년 평창동계올림픽에서 8개국 통역서비스를 선보일 예정이다. 한국을 찾는 수많은 외국인들이 언어 장벽 없이 스포츠와 여행, 쇼핑을 즐길 것으로 기대된다. SK텔링크의 00700 국제전화 자동통역 서비스는 국내에 거주하는 외국인이나, 다문화 가정에서 외국에 사는 배우자 가족과 통화 할때 유용할 것으로 보인다.
물론 아직은 갈 길이 멀다. DB를 쌓아 번역 성능을 높이고 자연어 인식률을 높이는 것 외에도 할 일이 많기 때문이다. 요소 기술을 서로 연결하는 중간 기술을 개선하는 연구가 대표적이다. 자동통역을 연구하는 과학자들도 당장 외국인과 언어 장벽 없이 대화하기를 기대하지는 않는다. 그럼 왜 연구를 계속하는 걸까. 조창수 연구원은 “자동통역을 연구하면 자유로운 휴먼인터페이스(사람과 컴퓨터의 교류)에 한발 더 다가가는 셈”이라고 말했다.
“휴먼인터페이스는 최종적으로 컴퓨터와 사람이 음성만으로 교류하는 형태가 될 겁니다. 휴먼인터페이스에는 음성인식, 자동번역, 의도파악, 검색, 음성합성 등 다양한 기술이 필요한데, 벌써 세 가지가 자동통역과 관련된 기술이지요. 자동통역기로 외국인과 언어 장벽 없이 대화할 수 있다면 아이언맨의 자비스도 한층 가까워집니다. 자동통역을 하루 빨리 실현해야 할 이유입니다.”