기상청은 국지 재해에 적합한 새로운 지역수치예보모델을 개발해 7월에 시험 운영을 거친 뒤 내년 6월부터 정식 운영할 예정이다. 한층 더 섬세하고 똑똑한 예보를 기대하며 새로운 모델의 이모저모를 미리 만나보자.
지난해 9월 21일 추석 연휴의 시작을 알리던 즐거운 날, 서울에는 때아닌 물난리가 났다. 오전 11시부터 오후 5시까지 내린 집중호우로 서울의 중심부인 광화문 일대가 물에 잠겨버린 것이다. 하수구로 빠지지 못한 물이 도로 위에 넘실대고 차들이 오도 가도 못하는 상황이 곳곳에서 일어났다. 1만 가구 이상이 침수됐으며 총 5만 4410명의 이재민이 발생했다. 2명의 안타까운 생명이 빗물에 사라졌다. 6시간 동안 광화문에 내린 비의 양은 242mm. 1년간 서울에 내리는 강수량의 18%에 해당하는 양이었다. 평화로운 추석 연휴를 만끽하려던 서울 시민들의 꿈은 빗물에 휩쓸려 버렸다.
수치예보 전문가의 이유 있는 변명
‘좁은 지역에 수 시간 동안 집중적으로 강하게 내리는 비’ 집중호우는 그야말로 잊을만하면 우리나라를 찾는 불청객이다. 우리나라는 지형이 복잡하고 삼면이 바다로 둘러싸여 있어 집중호우가 많이 발생한다. 전체 자연재해 피해액 중 집중호우로 인한 피해액은 태풍에 이어 2위다. 1916년부터 2009년까지 자연재해 사례를 피해액 순위로 배열하면 상위 10개 안에 집중호우가 6개나 포함될 정도다.
피해를 줄이기 위해서는 무엇보다 집중호우 예측 능력을 높여야 한다. 하지만 수치모델로 날씨를 예측하는 전문가의 입장에서 집중호우는 악기상 중에서 가장 예측하기 어려운 현상 중의 하나임을 고백한다. 강수 유무에 대한 예측은 상대적으로 정확도가 높다. 하지만 좁은 지역에 단시간동안 강하게 내리는 집중호우는 예측하기가 무척 어렵다. 특히 집중호우는 이른 새벽에 내리는 경우가 많다. 이때는 예보를 한다 해도 대처가 어렵다.
집중호우 예측이 어려운 이유는 수치예보가 갖는 근본적인 한계 때문이다. 수치예보모델은 기온, 기압, 바람, 수증기 같은 기상요소가 시간에 따라 어떻게 변하는지를 물리 방정식으로 표현한 것이다. 육지와 해상, 상공에서 기상장 비로 측정한 자료를 모델에 넣고 계산하면 수 시간에서 수백 년까지의 미래 대기 상태를 예측할 수 있다.
모델에서 지구의 대기 공간은 일정 간격을 갖는 입방체로 표현된다. 실제 대기는 빈 곳이 존재하지 않는 연속체지만 수치예보모델은 이런 연속성을 표현할 수 없기 때문이다. 예를 들어 현재 동아시아 지역의 기상 현상을 예측하는 지역예보모델은 가로12km×세로12km의 면적에 수백~수천m의 높이를 갖는 입방체로 표현한다. 동아시아 지역예보모델에는 이런 입방체가 1632만 9600개 들어간다. 격자(입방체의 수평면) 하나마다 기상요소 평균값들이 하나씩 계산되므로 격자의 크기가 작을수록 해상도가 높아진다.

해상도를 높이려면 그만큼 많은 초기 값(관측 값)이 필요하다. 육지는 현재 조밀하게 설치된 자동기상관측장비(AWS)로 많은 관측값을 수집하고 있지만 해양이나 산악, 대기 상공 등은 위성과 레이더 같은 원격 장비로 얻은 관측 자료로 채워 넣고 있다. 하지만 이런 자료를 모두 동원해도 채울 수 있는 초기 값은 2만개에 지나지 않는다. 전체 격자수의 2%에도 미치지 못한다. 관측 자료만으로 초기 값을 생산하기가 불가능하다는 얘기다. 그래서 지금은 이전 시간에 수치예보모델로 예측한 현재 값을 현재 관측 값으로 보정해 초기 값을 실제 값으로 만드는 자료동화 과정을 거치고 있다. 이는 예측 값에서 추정한 값을 실제 값으로 사용하므로 초기 값부터 불확실성이 포함돼 있다는 것을 의미한다. 이러한 불확실성은 수치예보모델로 기상요소들을 계산할 때마다 점점 늘어나 예측 정확도를 낮추는 원인이 된다.
300m 한라산이 엉터리 예보 원인
그렇다면 해상도를 올리는 것은 불가능할까. 그렇지 않다. 기온, 기압, 바람, 수증기 같은 관측 자료의 수를 늘리는 것 외에 매우 중요한 요소가 또 있다. 바로 지형, 식생, 해륙 구분 같은 지표특성이다. 지표특성은 해상도에 따라 매우 다르게 표현된다. 예를 들어 해발고도가 1950m인 한라산을 해상도가 12km인 지역예보모델에 넣으면 실제에 한참 못 미치는 300m로 표현된다. 하지만 해상도 1.5km인 상세 국지예보모델에 넣으면 실제 해발고도와 거의 비슷한 1700m로 표현된다.
산 높이 하나가 낮게 표시되는 게 무슨 큰 문제일까 싶지만 집중호우의 특성을 고려한다면 이는 중대한 사고다. 바람을 맞는 면과 등지는 면에서 집중호우는 각기 다르게 나타나기 때문이다. 산의 경사가 급할 때 대부분의 강수 현상은 바람을 맞는 면에서 일어난다. 반대로 바람을 등진 면에서는 건조한 바람이 불고 기온이 상승한다. 만일 수치예보모델에서 산의 경사를 완만하게 표현한다면 강수가 산 좌우로 고르게 표현될 것이다. 실제로 태백산맥을 낮은 구릉으로 표현한 수치예보모델에서는 산 정상 부근의 넓은 영역에 약한 눈이 올 것으로 예측해 영동지역에 내린 폭설을 예측하지 못했다. 이런 결과를 통해 집중호우 같은 작은 규모 기상현상은 꼭 해상도가 높은 수치예보모델로 예측해야 한다는 것을 알 수 있다. 일반적으로 10km 수평 규모의 집중호우를 예측하기 위해서는 적어도 1km 해상도의 수치예보모델이 필요하다고 보고 있다.
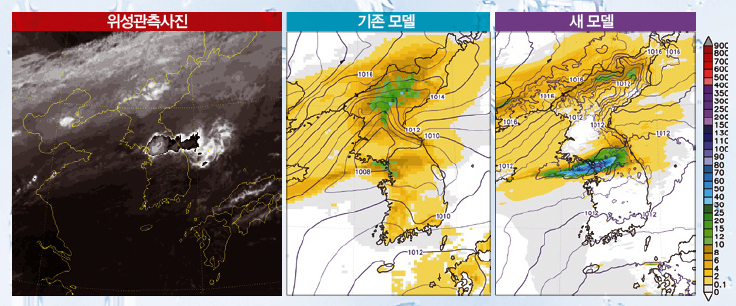
신·구 지역예보모델의 영역과 해상도의 차이
해상도가 12km인 기존 모델(왼쪽)은 격자의 크기가 커서 지표 특성을 매우 성글게 표현했다. 하지만 해상도를 1.5km까지 끌어올린 새 모델은 격자 크기가 기존보다 64분의 1로 작아졌기 때문에 섬세한 지표 표현이 가능하다. 집중호우는 좁은 지역에서 일어나는 작은 규모의 기상현상이므로 정확한 지표 표현이 매우 중요하다.


해상도 64배 높인 새로운 모델
기상청은 최근 집중호우 예측에 한계를 가져오는 요인들을 개선하고 해상도를 상당히 높인 상세 국지예보모델을 구축했다. 새로운 모델의 해상도는 1.5km다. 현재 지역예보모델의 격자 1개가 예측하는 지역을 새로운 모델에서는 격자 64개가 예측해 해상도가 64배 증가한다. 예측 영역이 현재 모델의 7%에 불과하지만 격자 개수는 4833만 240개로 현재 모델보다 3배 많다. 이 같이 해상도가 증가하면 태풍 중심 부근의 강풍과 강우대, 뇌전과 돌풍을 동반한 집중호우, 폭설 등 국지적으로 발생하는 위험기상 현상들의 예측 정확도가 향상될 것으로 기대하고 있다.
예측 성능을 높이기 위해 새로운 모델에는 레이더 자료를 적극 활용할 예정이다. 레이더는 5~10분마다 한 번씩 3차원 대기를 250m 간격으로 관측한다. 특히 관측 자료가 거의 없는 서해상의 대기 상태를 유일하게 관측할 수 있다. 최근 기상청은 국토해양부와 국방부 등 관련 기관이 보유하고 있는 레이더를 함께 활용할 수 있도록 협약을 체결했다. 관측 지역을 확대하고 관측 전략을 최적화해 관측 자료의 품질도 효율적으로 관리하기 위해서다.
실제로 몇몇 사례를 통해 새 모델의 우수한 성능이 입증됐다. 지난해 9월 21일 발생한 집중호우의 경우 현재 모델은 경기만 부근에 10~12mm 정도로 비가 온다고 예측했다. 그러나 새 모델은 서울을 비롯한 중부 지방에 동서 방향의 강수분포를 예측했다. 기존 모델이 전국적으로 넓은 영역에 약한 비를 예측한 데 비해, 새 모델은 실제 관측과 유사하게 중부 지방에만 강수를 예측했다.
기상청은 올해 7월 시험 운영을 거쳐 내년 6월에 상세 국지예보모델을 정식 운영할 예정이다. 1일 8회 12시간 예보할 계획이며, 1회 예보에 소요되는 시간은 약 40분이므로 최대 11시간 정도 집중호우에 대비할 시간이 확보될 것이다.
2010년 9월 21일 집중호우 사례 예측 결과
지난 9월 21일 집중호우 사례를 기존 모델과 새 모델로 각각 예측했다. 기존 모델은 경기만 부근에 10~12mm의 약한비를 예측했으나 새 모델은 서울을 비롯한 중부 지방에 동서방향으로 넓게 비가 있을 것이라고 예측했다. 실제로 같은 시각에 위성으로 관측한 자료를 보면 새 모델이 예측한 결과와 매우 비슷했다.
집중호우 100% 예측할 수 있나?
상세 국지예보모델이 기존 모델보다 더 낫다고 해도 모든 오차 원인을 해결한 것은 아니므로 여전히 예측 한계가 존재한다. 뿐만 아니라 일반적으로 나비효과라고 불리는 혼돈법칙 때문에 수치예보모델로 집중호우를 100% 정확하게는 예측할 수 없다. 왜냐하면 날씨는 초기의 매우 작은 차이가 임의 시점부터 급격하게 커지기 때문이다. 수치예보의 초기 값은 앞에서 제시한 바와 같이 상당히 부족한 관측 자료로 구성되므로 초기 값의 부정확성은 항상 존재한다.
수치예보는 발생할 확률이 높은 시나리오 중의 하나이므로 예측 값뿐만아니라 이 값이 갖는 오차(불확실성)를 함께 제공하려는 노력들이 이뤄져 있다. 최근에는 앞에서 언급한 오차를 고려해 여러 개의 초기 값 혹은 여러가지 수치예보모델로 수십 번 계산해 예보를 내는 것이 세계적인 추세다. 이러한 예보 기법을 앙상블 예보 혹은 확률론적 예보라고 한다.
결정론적인 예보(하나의 모델로 한번만 계산)인 상세 국지예보모델에서 예측된 호우의 위치, 시간, 양을 100% 정확하다고 가정하기보다는 발생할 확률이 가장 높지만 불확실성을 내포한 하나의 시나리오로 가정하여 의사결정을 해야 한다. 기상청은 현재 전 지구예보모델의 앙상블 예측을 수행 중이며, 상세 국지예보모델을 앙상블로 운영하여 예측 값뿐만 아니라 불확실성도 함께 제공하기위한 장기 계획을 준비하고 있다.