지수귀문도는 고래로 전해오는 마방진 계열의 문제로 조선시대 영의정을 지낸 수학자 최석정이 고안한 문제다. 최석정은 그의 저서 ‘구수략’에 3차(3행3열)부터 10차까지의 마방진을 기술하고 있다. 최석정은 마방진에 우주의 진리와 주역의 원리가 함축돼 있다고 생각했다. 따라서 그는 다양한 모습의 숫자배열을 연구했는데, 사각형 형태인 마방진은 물론 원형, 십자형, 거북등형 등의 숫자배열에 깊은 관심을 가졌다.
지수귀문도의 비밀
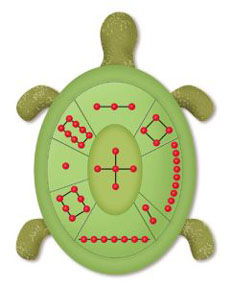
최석정이 제시한 여러 배열도 중에서 가장 눈길을 끄는 것은 거북등 모양으로 숫자를 배열하는‘지수귀문도’(地數龜文圖)다. 이는 육각형을 벌집모양으로 이어 각 꼭지점에 서로 다른 숫자를 써넣고 하나의 육각형을 이루는 6개의 숫자의 합이 같도록 하는 배열이다. 그의 ‘구수략’에 제시된 지수귀문도는 숫자의 개수가 총 30개이고 각 육각형의 합이 93이 되는 교묘한 배열이다. 이런 모양은 가장 기초적인 6개의 숫자를 배열한 육각형 하나로 이뤄진 모양에서부터 16개의 숫자를 배열한 육각형 4개, 30개의 숫자를 배열한 육각형 9개(지수귀문도) 등 여러 모양을 만들 수 있고 배열하는 숫자의 개수에 따라 무한히 확장할 수 있다.
최석정 이래 많은 사람이 지수귀문도의 해결에 관심을 보였고, 일부 새로운 방법들이 발견됐다. 그러나 얼마나 다양하고 많은 해가 존재하는지에 대해서는 별로 알려진 바가 없다. 이것은 그동안의 연구가 주로 사람의 생각에 의존했기 때문에 해답 가능성에 대한 탐색에 한계가 있었기 때문이다.
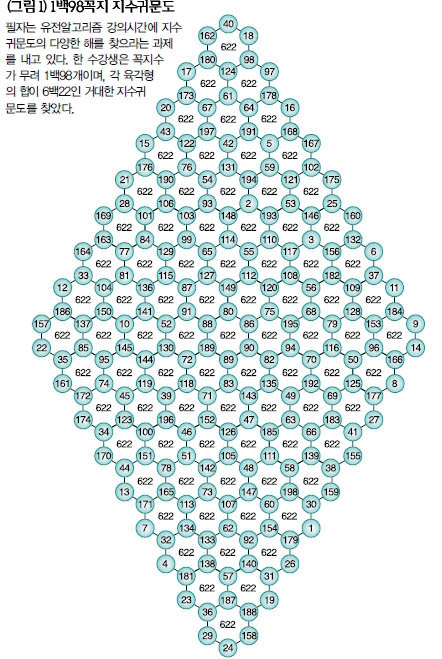
30꼭지 지수귀문도에 대해 지금까지 문헌을 통해 알려진 해들에서 육각형의 합은 89, 90, 91, 92, 93, 95, 97이 있다. 하지만 필자의 연구실에서 유전알고리즘으로 찾아본 결과, 이보다 훨씬 다양한 79에서 107까지의 해가 관찰됐다.
실제로 지수귀문도의 정답수를 추정해보면 놀라운 사실이 발견된다. 16꼭지 지수귀문도의 경우만 하더라도 무려 6억개 이상의 정답이 존재한다. 6억개라면 정답이 널린 것 같지만 가능한 모든 숫자 배정 방법들 중 대략 3만개 중의 하나가 정답인 셈이다.
24꼭지 문제의 정답 총수는 16꼭지보다 훨씬 많은 무려 40조개 정도로 추정된다. 이는 1백억개 중의 하나 정도 꼴로 정답이 드문드문 발견되는 것이다. 불과 16꼭지에서 24꼭지로 커지면서 정답의 수가 6억에서 40조로, 정답의 희소성은 3만분의 1에서 1백억분의 1로 변했다. 그러면 198꼭지 지수귀문도는 정답의 총수가 얼마나 엄청날지, 그러면서도 얼마나 드물게 발견될지를 상상해보라.
쉬운 문제에는 적합하지 않다
지수귀문도의 답을 하나 구하는 일은 이렇게 엄청난 수의 ‘정답 후보군’ 중에서 조건을 만족하는 배열을 찾아내는 작업이다. 정형적인 극소수의 예를 제외하고는 인간의 두뇌로 해결하기는 거의 불가능하다. 유전알고리즘은 지수귀문도와 같이 정답 후보군이 방대해서 정형적인 탐색으로 어려운 문제들에 유용하다.
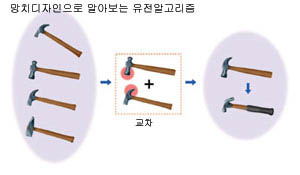
유전알고리즘은 이름처럼 진화의 원리를 차용한다. 생물체가 염색체 교차와 유전자 변이를 통해 환경에 적응하는 진화의 메커니즘을 차용해 문제해결에 응용하는 것이다.
비유적인 예를 통해 알아보자. (그림 2)는 효율적인 망치를 디자인하는 과정을 유전알고리즘의 연산자와 대비시켜 설명한 것이다. 처음에는 해집단을 임의의 망치들로 채운다. 이로부터 하나의 새로운 망치가 만들어지는 과정은 다음과 같다. 먼저 해집단에서 두개의 망치를 선택한 다음 두 망치의 특징을 부분 결합해 새로운 망치를 만들어낸다. 이를 ‘교차’(crossover)라 한다. 이렇게 만들어진 망치에 약간의 변형을 하는데 이를 ‘변이’(mutation)라 한다. 이렇게 만들어진 망치들의 매력을 평가한 다음 기존의 해집단을 대치한다. 이 과정을 반복하면 매력적인 망치들을 디자인할 수 있다.
유전알고리즘은 현실적인 시간내에 최적의 해를 찾기가 불가능해 보이는 문제 해결에 적당하다. 현실적인 시간내에 쉽게 풀 수 있는 문제에 대해서는 적당치 않다. 유전알고리즘의 작동 메커니즘이 시간을 최우선으로 고려하지 않기 때문이다. 만약 보통의 방법으로도 쉽게 풀리는 문제에 유전알고리즘을 적용한다면 시간만 낭비하는 결과를 초래할 것이다. 예를 들어 N개의 원소를 크기순으로 정렬하는데 유전알고리즘을 사용한다면 바보짓이다. 효율적인 정렬 알고리즘이 널려있기 때문이다.
유전알고리즘은 지수귀문도 등 현실적 시간에 쉽게 풀리지 않는 난제를 해결하는데 큰 힘을 발휘한다. (그림 1)은 유전알고리즘으로 찾은 1백98꼭지 지수귀문도의 한 예다. 유전알고리즘으로 발견한 다양한 해들을 보면 지수귀문도의 정답들 중 정형적인 방법으로 만들 수 있는 것은 너무나 제한적이라는 사실을 알게 된다.
자연을 프로그램하라
유전알고리즘은 40여년의 역사를 갖고 있으나 세간의 관심을 본격적으로 끌게된 것은 최근 10년 동안이다. 유전알고리즘은 생물학과 컴퓨터공학의 연관성을 일찌감치 감지한 존 홀랜드에 의해 시작됐다. 홀랜드는 병렬처리에 관한 논문으로 미국 최초의 컴퓨터과학 박사학위를 받은 사람이다. 재미있는 것은 최초의 컴퓨터과학 박사인 홀랜드가 주도해온 유전알고리즘 분야가 컴퓨터과학 분야의 막내둥이로 간주되고 있다는 점이다.
유전알고리즘이 세상에 본격적으로 알려진 것은 미국 산타페연구소의 궤적과 관계가 깊다. 산타페연구소는 노벨 물리학상을 받은 머레이 겔만과 필 엔더슨, 노벨 경제학상을 받은 케네스 에로우 등이 복잡성과학을 연구하기 위해 1984년 설립한 연구소다. 아인슈타인과 폰 노이만이 활동하던 고등연구소 이래 가장 뛰어난 천재들이 모였다는 사실만으로도 화제가 됐던 기관이다.
홀랜드는 이 연구소가 설립된지 몇년 후 한 세미나를 통해 합류하게 됐는데, 산타페연구소의 연구 방향을 ‘복잡계’에서 ‘적응적 복잡계’로 선회시킬 정도로 깊은 영향을 미쳤다. 현재 유전알고리즘은 산타페연구소의 힘을 입어 본격적인 황금기를 맞고 있다.
1980년 이후에 유행한‘인공생명’연구도 유전알고리즘이 알려지는데 상당한 기여를 했다. 유전알고리즘은 인공생명 연구의 대표적 도구 중 하나다. 현재는 홀랜드의 제자인 데이비드 골드버그가 일리노이 대학에서 뛰어난 연구그룹을 이끌며 활발한 활동을 펼치고 있고, 필자의 연구실도 이론적. 실험적으로 가장 앞서가는 연구실 중 하나다.
진화의 메커니즘에 대한 통찰을 통해 홀랜드가 생각한 질서의 구성 방식은 ‘위에서 아래로’가 아니라 ‘아래에서 위로’였다. 유전알고리즘은 거대한 패턴 짜맞추기 게임이다. 초기의 해들은 대부분 임의적으로 만들어지므로 대체로 품질이 형편없다. 이런 초기 해들에는 나중에 좋은 해에 기여할 수 있는 작은 패턴들이 숨어있다. 진화의 과정을 통해 이런 작은 패턴들이 결합돼 점점 더 큰 패턴을 만들어가는 과정이 유전알고리즘이다. 이런 패턴들을 ‘스키마’라고 하는데, 이에 대한 자세한 내용은 다음 연재에서 다룬다.
스티븐 레비는 그의 저서 ‘인공생명’(Artificial Life)에서 유전알고리즘을 다음과 같이 비유했다. “우연성을 바탕으로 그 속에 자연을 프로그램하라! 그러면 그 다음부터는 자연이 모든 것을 떠맡을 것이다.”
마방진
마방진은 1에서 N제곱까지 모든 숫자들을 한번씩만 사용해서 N행N열의 배열을 만들었을 때 어떤 행이나 열, 대각선의 수를 합해도 항상 합이 같아지는 배열을 말한다. 마방진은 영어의 ‘magic square’를 번역한 말로, 사각형 모양의 숫자배열인 방진 중 상하좌우 대각선의 합이 모두 같은 특수한 조건을 만족하는 ‘마술같은 방진’이라는 뜻이다. 역사상 많은 마방진들이 만들어졌는데, 최초의 것은 3행3열의 마방진이라고 알려져 있다. 전설에 따르면 중국 하나라의 우임금이 매년 범람하는 황화의 물길을 정비하던 중 강에서 이상한 그림이 새겨진 거북의 등껍질을 얻었다. ‘낙서’(洛書)라 불리는 이 그림에는 1부터 9까지의 숫자가 3행3열로 배열돼 있는데, 어느 쪽으로 더하든지 모두 합이 15가 되는 마방진이었다고 한다.











