문장구조가 단순하고 내용이 애매모호하지 않은 문장을 컴퓨터가 거뜬하게 번역해낸다.
현대 사회는 정보화 사회로 국가간의 정보교환이 빈번하고 또한 교환해야 할 정보의 양이 사람의 노력으로 번역하기에는 너무 많아지고 있다. 따라서 컴퓨터를 이용한 번역은 매우 중요하고 시급히 해결되어야 할 연구과제로 등장했다.
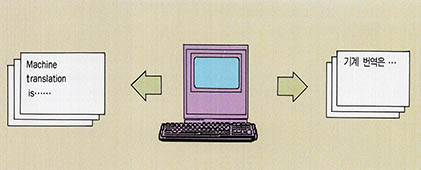
기계번역(machine translation)이란 이러한 요구에 부응하여 컴퓨터를 이용해서 문서를 번역하는 것이다. 이 때 기계번역의 대상으로 되는 문서는 한글이나 영어 등과 같이 사람들이 일상 생활에서 사용하는 자연언어(natural language)로 작성되며 번역이란 이러한 자연언어로 작성된 문서를 다른 자연언어로, 예를 들면 우리말로 쓰여진 문서를 영어로 바꾸는 것이다.
번역에 있어서 가장 중요한 점은 원문이 표현하는 내용과 번역문서가 표현하는 내용이 서로 같아야 한다는 점이다. 경우에 따라서는 문장의 내용 이외에도 문장의 구성형식이라든지 단어의 순서가 비슷해야 하는 것이 요구될 수도 있으나 일반적으로 기계번역 시스템의 목표는 문장의 의미를 그대로 전달하는 것이 가장 중요하다.
소련의 과학에 충격받아
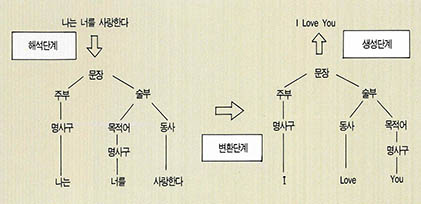
기계번역의 역사는 컴퓨터의 발명 이전인 1930년까지 거슬러 올라가지만 본격적인 연구가 시작된 것은 1949년 위버(W. Weaber)의 기계번역에 대한 메모로부터라고 볼 수 있다. 위버는 이 메모에서 현대 기계번역의 처리 방식과 같이 우선 원문을 해석하여 원문의 내용을 나타내는 적당한 중간표현으로 바꾸고 이 중간 표현을 이용하여 번역문을 만드는 방식을 제안하였다.
기계번역을 구축하려는 연구는 1960년대 초에 시작됐다. 소련이 세계 최초로 인공위성 발사에 성공하자 미국의 과학자들은 소련의 과학력에 크게 놀라게 되었고 소련의 과학정보를 입수할 필요성을 느끼게 되었다. 이에 따라 미국에서는 '러시아어-영어' 기계번역 시스템을 구축하기 위해 막대한 연구비를 투입했다. 그러나 당시의 컴퓨터 처리 능력은 보잘것 없는 것이었다(당시 컴퓨터의 처리 능력은 70년대 8비트 애플 컴퓨터보다 낮았다). 또 인간의 언어활동에 대한 이해가 전혀 없이 그저 단어를 다른 언어의 단어로 바꾸어 문장의 순서를 적당히 조정하면 번역이 된다는 생각만으로 연구를 시작했으므로 그 결과는 날이 갈수록 사람들의 기대로부터 멀어지게 되었다.
62년 당시 기계번역 연구의 중심이던 매서추세츠공과대학(MIT)의 히렐(Y.B. Hirell)은 "자동 기계번역이란 가까운 장래에는 불가능하다"는 결론을 내고 연구를 중단하게 되었다. 이에 따라 미국 과학재단은 기계번역의 현황과 장래를 조사하여 '기계번역의 장래는 No'라는 유명한 ALPAC(Automatic Language Processing Advisor Committee, 자동 언어 처리 자문 위원회) 보고서를 66년 제출하여 제1세대 기계번역 연구는 막을 내리게 된다.
ALPAC 보고서 이후 기계번역에 대한 연구는 침체기에 들어서게 된다. 그러나 컴퓨터 하드웨어는 눈부시게 발전하게 되었고, 언어이론 분야에서도 MIT의 언어학자 촘스키(N. Chomsky)에 의한 변형생성구(句)구조문법이론이라는 문법이론이 개발됐다. 이후 기계번역은 문장의 구조를 해석하여 번역에 이용하는 제 2세대로 들어서게 된다.
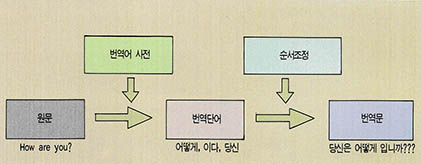
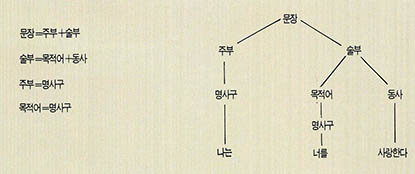
제 2세대 기계번역의 연구는 제 1세대 기계번역과는 달리 우선 번역이란 작업이 단순히 단어를 치환함으로써 이루어지는 간단한 작업이 아니라 인간의 모든 지식이 총동원되어야 하는 복잡한 작업이라는 사실을 깨닫게 되었다. 제 2세대 기계번역의 특징은 변형생성 구구조문법의 구문규칙을 이용하여 문장의 구조를 해석하려고 했다는 점에 있다. 문장의 구성은 각각의 언어마다 다르기 때문에 같은 의미를 표현하는 문장이라도 그 구조가 서로 다를 수 있다. 따라서 번역을 하기 위해서는 원문장의 구조를 번역문장에 적합한 구조로 변환하는 과정이 필요한데 이 과정을 변환(transfer) 과정이라고 한다.
제 2세대 기계번역에서는 따라서 원문장을 구구조 규칙을 이용하여 해석하는 과정과 해석된 결과를 번역문장의 구조로 바꾸는 변환과정, 그리고 변환된 구조로부터 번역문을 만드는 생성과정으로 나누어 번역을 하게 된다. 제 1세대에서 단어 대 단어로 바로 치환한 것(직접번역이라고 함)에 비해 2세대에서는 해석과 변환 과정을 거쳐서 번역을 하므로 2세대 번역을 간접번역(indirect translation)이라고 한다.
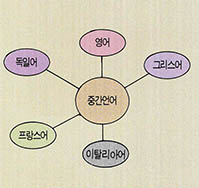
한편 구문구조는 언어에 따라서 서로 다르므로 구문구조를 중간 표현으로 사용하지 않고 개별언어에 의미를 나타낼 수 있는 언어(pivot, 중립언어라고 함)를 중간구조로 사용하려는 시도가 있는데 이러한 시도를 피봇방식이라고 한다.
제 2세대에 이르러서는 여러 나라에서 실용적인 기계번역 시스템을 구축하려는 연구가 시도되었는데 대표적인 예로는 프랑스 그레노블 대학의 CETA GETA ARIANE- 78, 서독 쟈르란데스 대학의 SUSY, 유럽공동체(EC)의 SYSTRAN, 캐나다 몬트리올 대학의 TAUM-METEO 등을 들 수 있다.
인공지능연구와 결합
80년대에 이르러 기계번역은 비로소 인공지능연구와 결합되고 있다. 제3세대로 불리는 이 시기에는 문장의 구성 구조뿐만 아니라 여러가지 지식들을 이용하여 기계번역을 하려는 연구들이 진행되고 있다. 제 3세대 기계번역의 특징으로는 지식의 적극적인 활용과 다(多)언어간 기계번역을 들 수 있다.
제 3세대 기계번역에 이르러서는 문장의 구조보다는 의미를 중심으로 해석을 하며 문장의 정확한 의미를 구하기 위해서는 여러가지 상식이나 문장이 다루고 있는 특정 분야의 전문적인 지식이 필요하게 되어 지식의 표현, 추론 등의 분야에 활발한 연구가 이루어지고 있다. 또한 인간의 인식과정에 대한 연구도 활발히 진행되어 인간의 언어활동 모형과 유사한 기계번역 시스템을 구축하려는 연구가 진행됐다. 기계번역은 이제 전산학 뿐만 아니라 언어학 심리학 인지과학 등 여러 학문의 종합적인 연구영역으로 되어가고 있는 실정이다.
제 3세대 기계번역 시스템의 예로는 우선 유럽공동체의 유로트라(EUROTRA) 시스템을 들 수 있는데, 이 시스템은 9개국 언어(영어 프랑스어 독일어 이탈리아어 그리스어 등)간의 번역을 목표로 하고 있다. 미국에서는 카네기멜론 대학에서 지식을 기반으로 한 기계번역 시스템을 연구, 구축하고 있으며, 일본에서는 과학기술청의 Mu 기계번역시스템과 NEC의 VENUS 기계번역시스템이 연구되고 있다.
인간이 컴퓨터를 도와준다(?)
많은 사람들은 기계번역 연구가 수행되면 번역가들은 직업을 잃을 것이라고 걱정을 한다. 그러나 컴퓨터가 사람과 같이 유창하게 번역을 하는 시대가 쉽게 올 것 같지는 않다.
우선 간단하게 생각해보면 사람의 뇌세포는 4조(${10}^{12}$)개 이상 된다고 한다. 그럼 컴퓨터의 기억 용량은 얼마나 될까. 현재 쓰이고 있는 컴퓨터 중 가장 대규모라 하더라도 하드디스크가 몇 기가(${10}^{9}$) 바이트 이상 되는 것은 드물다. 우선 기억장소의 크기만으로도 사람을 따라가기가 힘들다. 뿐만 아니라 사람과 같이 여러가지 지식들을 효율적으로 저장하고 그 지식을 이용하여 처한 상황을 이해하고 추론하는 컴퓨터시스템을 만드는 것은 먼 훗날에나 가능할 꿈과 같은 이야기다.
그러면 현재 컴퓨터의 능력으로 기계번역은 과연 가능한가. 이 물음에 대한 해답은 비록 인간과 같이 유창한 번역은 할 수 없지만 만약 번역하는 문장의 범위를 축소한다면 어느 정도 이해할 수 있는 번역결과 가능하다는 것이다. 또한 위와 같이 번역의 전과정을 컴퓨터가 수행하기 보다는 어려운 문제에 직면했을 때 사람이 도와준다면 현재 보다는 훨씬 적은 비용과 노력으로 질이 좋은 번역결과를 얻을 수 있다. 따라서 현재 개발 중이거나 시판되는 시스템의 처리 범위를 보면 거의 모든 시스템이 컴퓨터 분야의 매뉴얼이나 비행기보수 매뉴얼, 날씨보도기사 등의 제한적 영역을 대상으로 기계번역을 시도하고 있다. 즉 문장의 구조가 어느 정도 제한되어 있으며 그 내용이 애매모호하지 않는 어떤 특정한 한 분야를 대상으로 하고 있다. 또한 여러 시스템에서 컴퓨터가 풀기에는 너무 어려운 문제가 발생했을 때 사람에게 질문을 하여 사람이 그 문제를 해결해 주는 '인간이 컴퓨터를 도와주는 번역' (humanaided computer translation) 방법이 많이 사용되고 있다.
기계번역에 대한 연구는 이미 40년 이상 지속되고 있다. 하지만 광범위한 분야에 걸쳐서 사람의 도움이 전혀 없이 좋은 번역 결과를 낼 수 있는 시스템을 개발하기까지는 훨씬 더 많은 연구가 진행되어야 한다. 그러나 인공지능이나 인지과학, 그리고 기타 여러 인접 분야의 발달과 최근 여러나라의 기계번역에 대한 다양한 시도와 투자를 고려하면 기계번역의 본격적인 실용화 시대도 멀지 않음을 느낄 수 있다.
그러나 기계번역의 실용화란 컴퓨터가 문학작품과 같은 전문가의 세심한 고려를 요구하는 분야의 번역에까지 사용될 수 있다는 의미는 아니라는 것을 알아야 한다.
하루 아침에 모든 종류의 문장을 번역해 낼 수 있는 시스템을 개발하는 것은 무리이다. 앞으로 당분간은 제한된 영역, 예를 들면 컴퓨터 매뉴얼 등의 분야에서 지금보다는 더 좋은 번역 결과를 내는 시스템을 구현하거나 또는 전문 번역가의 작업을 도와주는 보조 번역 시스템에 대한 연구가 지속될 것이다. 그리하여 점점 번역하는 범위를 넓히거나 번역에서 컴퓨터가 담당하는 부문을 확대함으로써 기계번역을 처음 사람들이 기대했던 넓은 분야에 걸친 전자동 기계번역 시스템 개발로 접근해갈 것이다.