디베이스는 프로그래밍하지 않아도 쓸 수 있다. 그러나 프로그래밍을 배워두면 풍부한 디베이스의 진수를 음미할 수 있다.
이 연재강좌는 PC초보자들을 위해 디베이스Ⅲ 의 사용법을 총 6회에 걸쳐서 소개한다는 취지로 시작된 것이다. 그 목적이 얼마나 달성되었을까 하고 걱정하는 가운데 벌써 기본적인 사용법을 마치고 프로그래밍(programming)에 대해서 다루는 고급 단계에 이르렀다. 디베이스는 프로그램을 작성하지 않고도 충분히 활용할 수 있다. 하지만 많은 사람들이 디베이스를 좋아하는 이유중의 하나가 프로그래밍이 가능하다는 점인 것을 생각한다면 한번쯤 배워두는 것도 나쁘지 않을 것이다.
아마도 어떤 독자는 이 강좌를 시작할 때 디베이스 프로그래밍까지 배우기를 기대하지 않았을지도 모른다. 그러나 지금까지의 연재를 차근차근 소화해왔고 새로운 개념을 배운다는 의욕만 가진다면 일단 시작할 준비는 된 셈이다. 게다가 디베이스 프로그램은 그렇게 어렵지 않다. 지금까지 배워 온 디베이스 명령과 함수들을 적절히 배치하면 된다. 프로그램(program)은 매번 키보드로 직접 입력하던 명령들을 저장해둔 것으로서 이를 실행하면 기억되었던 명령들이 차례대로 처리될 뿐이다.
프로그램의 개념

디베이스에서는 프로그램을 저장해둔 파일을 명령어 파일(command file)이라고 부른다. 디베이스에서 명령어 파일을 실행하면 그 안에 기록되어 있는 디베이스 명령어들이 차례대로 (순서를 바꿀 수도 있다)수행된다.
지난 달에 사용했던 PHONE. DBF를 이용하여 예를 들어보자. PHONE. DBF 파일에 들어있는 자료들의 이름 전화번호 금액을 알고 싶다. 이런 경우에는 다음의 두 명령을 입력하면 된다.
●use phone↵
●list name, phone, fee↵
그런데 이 작업을 자주 해야 한다면 매번 이들 명령을 입력해야 한다. 이런 경우에는 시간과 노력을 줄이기 위하여 이 명령들을 명령어 파일에 저장한 뒤 파일의 이름만을 저장하면 된다. 그 방법은 다음과 같다.
디베이스의 도트 프롬프트에서
●modify command test. prg↵라고
입력하면 화면이 바뀌어 프로그램을 입력하는 상태가 된다. 이것을 에디터(editor) 모드라고 한다. 이 에디터 모드에서
●use phone↵
●list name, phone, fee↵
의 두 명령을 입력한다. 이 때의 화면은 (그림1)과 같다. 여기에서〈Ctrl-End〉키를 누르면 (Ctrl키를 누른 상태에서 End키를 누른다) 디스크에 TEST. PRG 라는 이름의 명령어 파일이 만들어진다. 이 명령어 파일을 실행하려면 도트 프롬프트에서
●do test↵
를 입력하면 된다.
디베이스의 명령어 파일이 가지는 장점은 여러가지가 있지만 다음의 두가지 사항이 가장 중요한 핵심이다.
●키보드로 입력할 수 있는 어떤 디베이스 명령이라도 명령어 파일에 저장할 수 있다. 그리고 명령어 파일을 실행하면 그 안에 저장되어 있는 디베이스 명령어들이 키보드로 입력된 것처럼 수행된다.
●한 명령어 파일에서 다른 명령어 파일을 실행할 수 있다. 그리고 명령어 파일들은 서로 데이터를 주고 받을 수 있다. 이것은 간단한 기능을 담당하는 명령어 파일들을 만들어서 효과적으로 구축하면 복잡한 프로그램도 쉽게 작성할 수 있다는 뜻이다.
명령어 파일을 이용하면 여러가지 기능들을 화면에 표시하여 선택하게 하는 메뉴를 만들 수도 있다. (그림2)는 그런 메뉴 화면의 예이다. 해당 기능을 수행하는 일련의 디베이스 명령들을 입력하는 것이 아니라 번호만 입력하면 된다. 따라서 디베이스를 잘 모르는 사람이 작업할 수 있도록 도와주는데 사용되기도 한다.

명령어 파일의 작성
디베이스에서 명령어 파일을 만드려면 MODIFY 명령을 사용해야 한다. 그 형식은 MODIFY COMMAND 파일이름이다. 이 명령은 ASSIST메뉴에서는 제공되지 않기 때문에 도트프롬프트에서 입력해야 한다. TEST. PRG란 명령어 파일을 만들기 위해서는
●modi comm test↵
와 같이 입력한다. 디베이스에서 명령어 파일의 확장자는 .PRG로 약속되어 있으므로 확장자를 특별히 지정하지 않아도 된다.
그러면 화면은 (그림1)과 같은 디베이스의 내장 에디터로 바뀌게 된다. 이 에디터에서 사용할 수 있는 키는 화면의 상단에 표시되어 있다. 이 키들을 이용하여 디베이스 프로그램을 입력한 다음〈Ctrl-End〉키를 누르면 된다. 디베이스의 내장 에디터는 디베이스에서 바로 호출할 수 있으므로 편리하지만, 명령어 파일의 크기를 4천자 정도로 제한하고 있다. 이보다 더 큰 명령어 파일을 작성하려면 별도의 에디터나 워드프로세서를 사용해야 한다. 단 명령어 파일을 저장할 때 아스키(ASCII)텍스트 파일로 만들어야 하며, 파일의 확장자는 꼭 .PRG로 해야 한다.
명령어 파일은
DO 파일이름의 형식으로 실행한다. 파일의 확장자는 .PRG로 고정되어 있으므로 입력할 필요가 없다.
프로그램의 구성요소
앞에서 디베이스의 프로그램인 명령어 파일은 디베이스의 명령어들이 나열된 것이라고 설명했다. 그러나 명령어들만으로는 효과적인 프로그램을 만들 수는 없다.
디베이스 프로그램이라는 집을 벽돌(디베이스 명령어)만으로 짓는다는 것은 좀 곤란하다. 벽돌들을 쌓기 위해 시멘트도 있어야 하고, 힘을 받는 곳에는 철근도 사용해야 한다. 여기에서 시멘트나 철근으로 비유된 것은 상수 변수 연산자 함수 제어구조 등을 말하는 것이다. 이들이 무엇인지 살펴 보기로 하자.
■상수/숫자와 문자
상수(constant)란 값이 변하지 않는 데이터이다. 우리가 흔히 사용하는 숫자들, 문자들이 모두 상수이다. 문자 상수들은 모두 따옴표로 둘러 싸야 한다. 이렇게 낯설은 이름을 사용하는 이유는 다음에 설명할 변수와 대비되기 때문이다.
■변수/첫 글자는 알파벳
변수(variable)는 중고등학교의 수학시간에서 배운 X와 Y라고 생각하면 된다. 상수를 보관하는데 사용하는 것이 변수이다. 변수는 10자 이내의 이름을 가진다.
변수의 이름은 알파벳 숫자 밀줄로만 구성되며 첫 글자는 꼭 알파벳이어야 한다. 디베이스는 미국에서 만들어진 소프트웨어이기 때문에 변수 이름으로 한글을 사용할 수는 없다 (한글화된 한글디베이스에서는 한글 변수가 허용된다). 또 영어라 하더라도 디베이스 명령어를 변수의 이름으로 사용할 수 없으며, 필드의 이름은 변수의 이름으로 적당치가 못하다.
변수는 디베이스 프로그램이 맡은 일을 처리하기 위하여 기억해야 하는 데이터들을 잠시 저장하는데 적격이다. 변수에 어떤 값을 저장하는 형식은
STORE 식 TO 변수이름 이다. 이것을
변수이름 = 식
이라고 적는 것도 가능하다. 여기서 식(expression)이란 상수 변수 필드의 어느 하나일 수도 있고 아니면 이들의 혼합일 수도 있다.
디베이스에서 변수는 그것이 저장하는 데이터의 종류에 따라 수치형 문자형 날짜형 논리형으로 나뉜다. 숫자형 변수는 숫자만을, 문자형 변수는 문자들을, 날짜형 변수는 날짜를 MM/DD/YY 와 같은 형식으로, 논리형 변수는 진실이냐 거짓이냐를 T(True)나 F(False)로 저장한다. 이런 변수의 종류는 변수에 처음 데이터를 넣을 때 그 데이터의 종류에 의해 결정된다.
다음은 변수 donga-age에 수치 3을 넣는 예이다.
●store 3 to donga-age↵
만약 donga-age의 값을 1만큼 증가시키려면
●store donga-age+1 to donga-age↵
과 같이 하면 된다. 변수의 내용을 확인하려면
●? donga-age↵
으로 확인하거나 DISPLAY MEMORY 명령을 사용한다.
필드에 들어 있는 값을 변수로 이동시킬 수도 있다. PHONE. DBF를 오픈한 상태라면
●store fee to money↵
으로 필드 FEE의 내용을 변수 MONEY로 복사할 수 있다. 다음은 문자열을 변수에 저장하는 예이다.
●store "과학동아" to donga-name↵
논리값은 T와 F로 표시하는데, 문자와 구분하기 위하여 앞뒤에 마침표를 붙인다. 다음 명령은 변수 CHOICE에 논리값 거짓을 부여하는 것이다.
●store.F. to choice↵
날짜형 변수에 날짜 데이타를 넣는 것은 함수에 대한 이해가 필요하므로 뒤에서 설명하겠다.
■연산자/비교의 척도
컴퓨터에서 프로그램을 작성하려면 연산자란 개념을 이해해야 한다. 그러나 그것도 중학교 정도의 수학을 배운 사람이라면 그리 어렵지 않게 이해할 수 있을 것이다. 디베이스 프로그램에서 사용하는 연산자는 산술연산자 관계 연산자 논리연산자 문자열연산자 정도이다.
산술 연산자에는 음수 부호(-) 지수 연산자(^) 나눗셈 연산자(/) 곱셈 연산자(*) 빼기 연산자(-) 덧셈 연산자(+)의 6가지 종류가 있다. 여러 개의 연산자가 함께 사용되면 앞으로 나열한 순서대로 우선순위를 가지게 된다. 즉 음호 부호가 가장 먼저 처리되고, 지수 연산자, 나눗셈 연산자 혹은 곱셈 연산자, 빼기 연산자나 덧셈 연산자의 순서대로 처리된다. 우선순위가 같은 경우에는 왼쪽에서 오른쪽의 순서대로 처리된다는 점까지도 학교에서 배운 수학과 일치한다. 물론 이 계산의 순서를 바꾸기 위해서 괄호를 사용할 수도 있다.
관계 연산자도 작다(<;) 크다(>;) 같다(=) 같지 않다(<;>; 또는 #)작거나 같다(<;=)크거나 같다(>;=)의 6가지 종류가 있다. 이 연산자들은 주로 수치 데이터의 크기를 비교하는데 사용된다. 예를 들면 8>;7의 결과는 .T., 즉 진실이다. 또 X>;3의 결과는 X의 값에 따라 달라진다. 재미있는 것은 "과학동아">;"과학기술"과 같은 문자열의 크기 비교도 가능한 점이다. 문자열들도 결국은 숫자의 형태로 기억되기 때문에 이들을 비교할 수 있는 것인데, 한글은 ㄱ에서 ㅎ으로 갈수록 그 숫자가 커지므로 앞의 비교는 .T.가 된다. 알파벳의 경우에도 A에서 Z로 갈수록 그 숫자가 커지는데, 주의할 것은 대문자보다 소문자들의 숫자가 더 크기 때문에 Z보다 a가 더 크게 된다는 점이다.
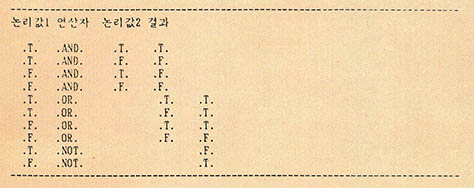
논리 연산자는 논리합(.AND.) 논리곱(.OR.) 논리부정 (.NOT.)의 3가지이다. 이들중 논리합과 논리곱은 두 개의 논리값 조합에 따라 결과를 논리값으로 내며, 논리부정은 주어진 논리값을 반대로 만든다. 그 연산표는 (표1)과 같다.
디베이스에서 사용할 수 있는 문자열연산자는 + 하나뿐이다. 이것은 산술 연산자 +와는 달리 두 개의 문자열을 합쳐 준다. 예를 들어 "과학"+"동아"는 "과학동아"를 결과로 돌려준다. 문자열 대신 문자열 변수를 사용할 수도 있다. 다음은 그 예이다.
●store "과학"to name 1↵
●store "동아"to name 2↵
●? name 1 + name 2↵
과학동아
■함수/특수한 기능
함수는 디베이스 명령어들에게 특수한 기능을 부여하기 위하여 만들어진 것이다. 디베이스는 70여개에 달하는 많은 함수들을 가지고 있다. 여기에서 이들 각각에 대하여 설명한다는 것은 무리이고, 일반적으로 자주 사용되는 EOF( )와 BOF( ) 함수를 설명하는것으로 함수에 대한 자세한 설명은 디베이스 관련서적을 참고 하기 바란다.
실습을 위하여 PHONE. DBF파일을 사용하기로 하자.
●use phone↵
하여 파일을 오픈한 다음
●go bottom↵
명령으로 마지막 레코드로 이동한다. 여기에서
●display↵
를 입력하면 마지막 레코드임을 확인할 수 있을 것이다. 이때
●? eof( )↵
와 같이 EOF( ) 함수를 사용하면 .F.가 출력된다. 이것은 현재의 위치가 파일의 끝이 아니라는 것을 의미한다. 그래서
●skip↵
으로 다음 레코드로 이동한 뒤
●? eof( )↵
를 하면 이번에는 .T.가 출력된다. 이제 파일의 끝에 있는 것이다. 이와 같이 EOF( ) 함수는 현재의 레코드 포인터가 파일의 끝을 가리키고 있는지 아닌지를 알려준다.
BOF( ) 함수는 EOF( ) 함수와 반대의 역할을 한다. 즉 레코드 포인터가 파일의 처음을 가리키고 있으면 .T., 그렇지 않으면 .F.를 돌려준다. 다음은 그 예이다. 여기에서 SKIP-1 명령은 레코드 포인터를 앞으로 하나 움직하게 한다.
●go top↵
●? bof( )↵
.F.
●Skip-1↵
●? bof ( )↵
.T.
■제어구조/명령어를 통제
프로그램에서 제어구조는 매우 중요한 역할을 한다. 제어구조가 없는 프로그램은 그 안에 나열되어 있는 명령어들을 차례대로 실행할 뿐이다. 이것으로도 상당한 효과는 있지만 융통성이 별로 없게 된다. 제어구조를 사용하면 명령어들의 실행순서를 바꿀 수 있고, 조건에 따라 필요한 명령어들만 실행시킬 수도 있다.
디베이스가 제공하는 제어구조는 여러 가지이지만 주로 사용하는 것은 다음의 세가지이다.
DO WHILE 조건
명령어들
ENDDO
IF조건
명령어들
〔ELSE
명령어들〕
ENDIF
DO CASE
CASE 조건
〔명령어들〕
〔CASE 조건
명령어들〕
〔OTHERWISE
명령어들〕
ENDCASE
첫번째의 제어구조는 DO WHILE 뒤의 조건이 만족하는 동안에는 뒤에 있는 명령어들을 계속 실행해준다. 반면에 두번째의 제어구조는 IF 뒤의 조건이 만족할때만 그 뒤의 명령어들을 실행해준다. ELSE를 사용하면 IF 뒤의 조건이 만족할 때만 그 뒤의 명령어들을 실행해준다. ELSE를 사용하면 IF 뒤의 조건이 만족하지 않을 때 ELSE 뒤의 명령어들을 실행해준다 (〔〕에 있는 것은 생략할 수 있는 것임을 나타낸다). 마지막의 제어구조는 CASE 뒤에 여러 조건들을 둘 수 있어서 각 조건에 맞는 명령어들을 마련할수 있다. (리스트1) (리스트2) (리스트3)은 이들을 사용하여 작성한 프로그램의 예이다.
자주 사용되는 명령어
디베이스에는 많은 명령어들이 있지만, 그중에서 자주 사용되는 것은 그리 많지 않다. 따라서 자주 사용되는 디베이스 명령어들을 간단하게나마 소개할 필요가 있다.

■SET TALK
일반적으로 디베이스 프로그램의 서두에는 SET TALK OFF명령을 둔다. 이 명령은 명령어 파일에서 실행되는 디베이스 명령들의 메시지가 화면에 출력되지 않게 한다. 이 명령은 SET TALK ON 명령을 실행할 때까지 유효하다.
■SKIP
이 명령은 앞에서도 언급되었지만 레코드 포인터를 앞뒤로 움직일 때 사용된다. 형식은 SKIP [+/-n]이다. 여기에서 n은 레코드 포인터를 얼마나 옮길 것인가를 지정하고, +와 -는 어느방향으로 옮길 것인가를 지정한다. +는 현재의 위치에서 파일의 끝 방향으로 이동하게 한다. 숫자대신 변수를 사용해도 되며, [ ]안의 내용을 생략하면 +1 로 가정된다.
■ACCEPT와 INPUT
이 두개의 명령은 사용자로부터 키보드 입력을 받는 일을 한다. ACCEPT는 문자열을 입력받고, INPUT은 수치를 입력받는다. 사용 형식은 다음과 같다.
ACCEPT "프롬프트"TO 변수이름
INPUT "프롬프트" TO 변수이름
이 명령들을 실행하면 화면에 프롬프트의 내용이 출력되고, 키보드 입력을 기다린다. 사용자가 입력을 하고 리턴 키를 누르면 그 내용이 TO 뒤에 있는 변수이름으로 저장된다. 다음은 ACCEPT명령의 사용 예이다.
●accept "이름을 입력하십시오""
to name↵
이 명령을 실행한 다음 ?name으로 확인해 보면 된다. 다음은 INPUT 명령의 사용 예이다.
●input "나이를 입력하십시오:"
to age↵
■COUNT
이 명령은 일정한 조건에 맞는 레코드가 몇개나 있는지 알아내는 것이다. 그 형식은
COUNT FOR 조건 TO 변수이름이다. COUNT 명령의 결과는 TO 뒤에 지정된 변수이름에 저장된다. 다음은 그 예이다.
●count for fee>;55 to
manyfee↵
그 결과 FEE 필드의 값이 55보다 큰 레코드의 수를 MANYFEE변수에 저장한다.

■SUM
이 명령도 COUNT와 성격이 비슷하다. 다만 그 결과가 레코드의 수가 아니라 필드의 값을 합산한 것이라는 점이 다르다. SUM 명령의 형식은 다음과 같다.
SUM필드 리스트 [FOR 조건]TO 변수이름
여기에서 필드 리스트는 합산을 하게 될 필드들의 목록이며, 그 구분은 콤마로 하게 된다. [FOR 조건]을 두면 조건에 해당하는 레코드들만을 골라 합산을 내게 된다.
합산의 결과는 TO 뒤에 지정된 변수이름에 저장된다. 다음은 SUM 명령의 사용예이다.
●sum fee to feetotal↵
●sum fee, tax for name=
"홍길동" to feetotal,
taxtotal↵
■ⓐ, ?, ??, TEXT
이 네개의 명령은 글자를 화면에 출력할 때 사용한다. ?와 ??는 그 뒤에 지정된 내용을 화면에 출력하는데, ?는 출력을 하기전에 행을 바꾸고, ??는 그냥 출력한다는 점이 다르다. SET PRINT ON 명령을 하고 ?나 ??명령을 사용하면 출력이 화면뿐 아니라 프린터로도 나가게 된다. 다음은 그 예이다.
SET PRINT ON
? "다음은 1500*3의 계산 결과입니다."
?
? 1500*3
SET PRINT OFF
ⓐ명령도 화면 출력에 관련된 것인데, 화면의 위치를 지정할 수 있는 점이 다르다. 화면의 위치는 가로 80행, 세로 24줄로 구분되고 좌측 상단의 위치가 0, 0이고 우측 하단의 위치가 23, 79이다. ⓐ 명령의 형식은
ⓐ 행,열[SAY 출력내용] 이다. 다음의 예를 시험해 보기 바란다.
●clear
●ⓐ12,20 say "여기가 좌표(12,20)입니다."
■TEXT
TEXT 명령은 많은 양의 문자를 출력할 때 유용한 명령이다. 이것은 주로 화면의 메뉴와 같이 큰 출력을 할 때 사용된다. 형식은 다음과 같다.
TEXT
출력내용
ENDTEXT
다음이 TEXT 명령의 사용 예이다.
CLEAR
TEXT
ENDTEXT
DO MENU
이상과 같이 이번호에서는 디베이스에서 프로그램을 작성하기 위해 알아두어야 할 기초적인 사항들을 살펴 보았다. 프로그래밍 언어로 새로운 프로그램을 작성한다는 일은 매우 힘든 일이다. 따라서 처음에는 이해가 잘 안되고 과정이 귀찮더라도 계속 노력하는 자세가 필요하다. 다음 호에서는 디베이스 프로그래밍 기법에 대해서 다루는 것으로 이 강좌를 끝맺을까 한다.











