디베이스를 쓰는 이유는 원하는 데이터를 언제라도 손쉽게 꺼내보기 위해서이다. 디베이스의 핵심인 소팅과 인덱싱에 대해 알아보자.
우리들은 아는 사람들의 이름과 전화번호를 수첩에 기록해둔다. 이 수첩은 다른 사람들에게는 별 소용이 없는 것일지 모르지만, 주인에게는 매우 중요한 정보가 된다. 잘못해서 수첩을 잃어버리기라도 하면 한동안 불편을 겪는 것은 물론이고 경우에 따라서는 오랫동안 연락을 하지 못하게 될 수도 있다.
그런데 수첩에 적어둔 사람들의 수가 많아지면 원하는 전화번호를 찾아내기가 점점 어려워진다. 이런 불편을 덜기 위하여 전화번호를 적는 공간을 '가나다'순으로 나누어 기록하기도 한다.
개인적인 수첩도 일종의 데이터베이스로 볼 수 있다. 디베이스를 이용한 데이터베이스와 다른 점은 수정이 용이하지 않다는점과 순서를 바꾸기가 거의 불가능하다는 것이다. 수첩에 새로운 전화번호 몇개를 추가하기 위하여 수첩 전체를 다시 정리할 수 있겠는가?
지난호에서 살펴본 바와 같이 디베이스를 사용하면 한번 입력한 데이터라도 변경이 간단하다. 뿐만 아니라 전화번호를 찾기 편하게 하기 위하여 공간을 가나다순으로 나누는 작업도 할 필요가 없다. 언제라도 마음만 먹으면 데이터의 순서를 손쉽게 바꿀 수 있기 때문이다.
이렇게 데이터베이스에 저장된 데이터들의 순서를 일정한 기준에 의하여 바꾸는 것을 소팅(sorting)이라고 한다. 이제 디베이스에서 소팅을 하는 방법을 배워보자. 그렇지만 우리는 디베이스에서 소팅을 거의 사용하지 않을 것이다. 그 이유는 뒤에서 이야기하겠지만, 소팅을 사용하지 않더라도 그 개념을 이해하고 있어야 한다.
■소팅/데이터의 의미있는 재배치
소팅이란 무엇인가? 앞에서 설명한 대로 데이터베이스에서 데이터를 소팅한다는 것은 어떤 기준에 의해서 데이터들의 순서를 바꾸는 작업을 말한다. 좀더 구체적으로 말해서 디베이스에서의 소팅은 데이터베이스 파일이 가지고 있는 레코드들의 순서를 특정 필드의 내용에 따라 재조정하는 것이다.
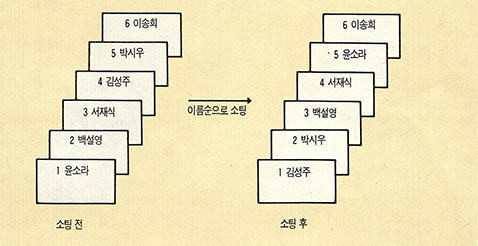
(그림1)은 지난호에서 예제로 사용한 PHONE.DBF 파일을 NAME 필드의 내용에 따라 소팅한 예이다. 원래 PHONE.DBF파일에는 6개의 레코드가 입력된 순서대로 들어있었는데, 이름을 기준으로 재배열한 것이다.
이렇게 재배열된 데이터베이스 파일은 그렇지 않은 파일보다 여러가지 면에서 유용하다. 소팅된 데이터베이스는 우리에게 정보를 준다. 사실 정보는 소팅된 데이터베이스라고 말할 수 있을정도이다. 사전, 전화번호부, 학급의 성적표, 기업의 매출순위, 연예인의 납세액 순위, 프로야구의 타격 5걸 등 소팅된 데이터베이스는 생각보다 우리의 생활과 관계가 많다.
디베이스에서 소팅된 데이터베이스가 주는 실제적인 장점은 원하는 레코드를 빨리 찾게 해주는 것이다. 물론 이 말은 (그림1)에서 볼 때 소팅하기 전에 박시우가 5번째 위치에 있다가 소팅한 후 2번째 위치로 옮겨 왔다는 것을 말하는 것은 아니다. 소팅된 데이터베이스의 장점은 박시우 뒤에 김씨 성을 가진 데이터가 있을 수 없다는 보장이다. 다시 말하면 소팅하기 전에는 박씨 성을 가진 데이터가 몇개나 있는가를 알려면 데이터베이스 전체를 조사해야 하지만, 소팅한 다음에는 그럴 필요가 없게 된다.
디베이스에서는 SORT 명령을 사용하여 데이터베이스 파일을 소팅한다. SORT 명령의 형식은 SORT ON <;소팅 필드>; TO <;소팅 파일>; 이다.
여기에서 <;소팅 필드>;는 소팅 작업의 기준이 될 필드의 이름이고, <;소팅 파일>;은 소팅 작업의 결과에 의해 새로 만들어진 데이터베이스 파일의 이름이다.
그렇다. 디베이스에서의 소팅이란 새로운 데이터베이스 파일을 만드는 것이다. 이것은 수첩에 적힌 전화번호들을 이름의 순으로 다시 정리하는 것과 같다. 다만 컴퓨터는 수첩을 다시 정리한다고 해서 불평을 하지 않을뿐 아니라 그 작업을 인간이 하는 것보다 매우 빨리 해준다.
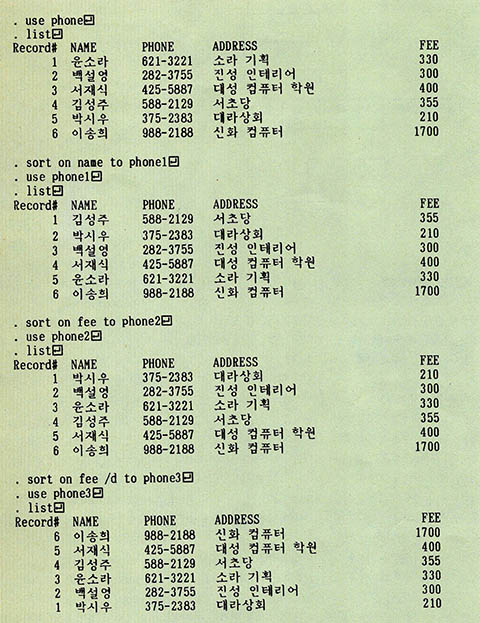
소팅의 실습을 위하여 지난호에서 만들었던 PHONE.DBF 파일을 가지고 시험해 보기로 하자. PHONE.DBF파일을 NAME 필드에 의해 소팅하려면
●sort on name to phone1↲명령을 사용한다. 같은 원리로 FEE 필드에 의한 소팅은
●sort on fee to phone2↲명령으로 가능하다.
SORT 명령은 올림 소팅(작은 것이 앞에 오고 큰 것이 뒤에 오게 하는 소팅)을 하도록 되어 있지만 /D 옵션을 사용하여 내림소팅(큰 것이 앞에 오고 작은 것이 뒤에 오게 하는 소팅)을 하도록 지정할 수도 있다. 그 방법은 <;소팅 필드>;의 뒤에
●sort on fee /d to phone3↲
과 같이 /D를 붙이는 것이다.(그림2)에 그 과정을 보였으니 참고하기 바란다.
시험삼아 소팅 명령을 몇번 하면 필요없는 데이터베이스 파일이 생기게 된다. 이 파일들을 지우고 싶으면 DELETE FILE 명령을 사용한다. 예를 들어 PNONE1.DBF 파일이 필요없다면
●delete file phone1.dbf↲
명령으로 PHONE1.DBF 파일을 지운다. 만약 소팅한 파일의 이름을 바꾸고 싶다면
●use phone3↲
●copy to phone↲
과 같이 COPY TO명령으로 복사를 하면 된다. 이때 PHONE.DBF 파일이 존재하면 디베이스는 기존의 파일이 지워진다는 경고 메시지를 보여준다.
■인덱싱/보다 실용적인 기법
이 글의 앞 부분에서도 이야기했었지만 디베이스에서는 지금까지 배운 소팅은 거의 사용하지 않는다. 그 이유는 소팅의 처리속도가 느린 데다가 디스크 공간도 많이 잡아먹기 때문이다. 이쯤에서 독자중에는 "아니 디베이스를 사용하면 편리하고 처리속도도 빠르다고 들었는데, 속도가 느리다니?"하고 의문을 제기할분도 있을 것이다.
컴퓨터를 처음 사용할 때는 컴퓨터가 느리다는 생각을 하지 않지만, 어느 정도 컴퓨터에 익숙하게 되면 컴퓨터가 느리다는 사실(?)을 깨닫게 된다. 사람이 컴퓨터 앞에 앉아서 지루함을 느끼지 않고 기다릴 수 있는 시간은 십몇초 정도라고 한다. 데이터베이스 파일이 작을 때는 소팅의 처리 속도가 이 시간을 넘지 않지만, 데이터베이스 파일이 큰 경우에는 몇십분이 걸릴 때도 있다. 이렇게 소팅의 속도가 느린 유는 데이터베이스 파일 전체를 읽어서 소팅을 한 다음 다시 디스크에 기록하기 때문이다.
그리고 디베이스의 소팅은 같은 내용의 데이터베이스 파일을 여러 개 만드는 결과를 가져오므로 디스크 공간의 낭비를 초래한다. 필요없는 파일은 지울 수도 있지만 데이터베이스 파일의 활용도를 높이기 위해서는 여러 개의 소팅 파일이 필요하다.
소팅의 이런 단점들을 보완하기 위하여 생각해낸 것이 인덱싱(indexing)이라는 기법이다. 인덱싱은 색인으로 번역할 수 있겠다. 인덱싱 기법은 데이터베이스 파일을 소팅하는 것에 있어서는 그 원리를 같이 하고 있지만 구현 방법이 다르고, 여러가지 면에서 유리한 장점을 제공한다.
디베이스가 제공하는 SORT명령의 형식을 보면 소팅의 기준이 되는 <;소팅 필드>;를 지정하게 되어 있다. 즉 소팅은 <;소팅 필드>;의 내용에 따라 레코드들의 순서를 조정하는 것이다. 이 점에 착안하여 <;소팅 필드>;만을 소팅하여 별도의 파일로 저장하는 방식이 고안되었으며, 이것을 책의 뒤에 있는 색인과 비슷하다 하여 인덱싱이라고 부른다.
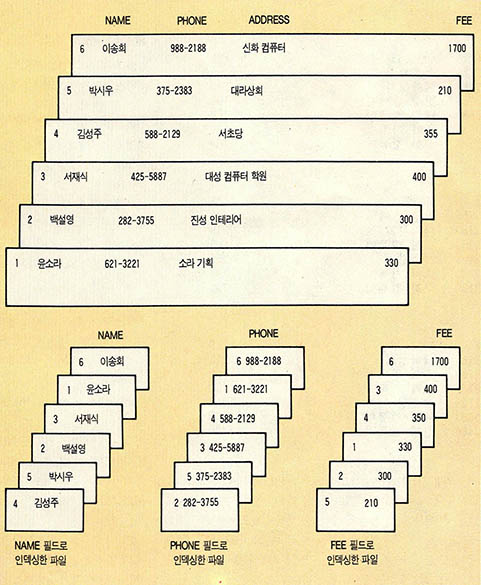
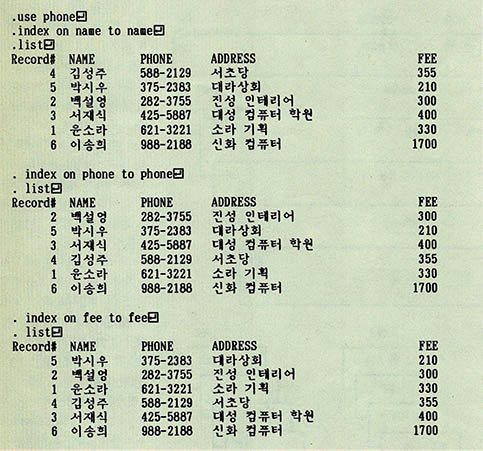
인덱싱은 데이터베이스 파일의 일부만을 소팅하여 별도의 파일로 저장하므로 소팅에 비하여 처리 속도가 빠르며, 디스크의 공간도 적게 차지한다. (그림3)에 PHONE.DBF 파일을 3가지 필드로 인덱싱한 예를 보였다. 그림에서 보듯이 데이터베이스 파일은 바뀌지 않고 그대로 있으며, 소트의 기준이 되는 필드만을 소트하여 별도의 파일로 저장한다. 이 파일들을 인덱스 파일(index file)이라고 부른다.
이 인덱스 파일을 이용하면 데이터베이스 파일을 소팅하지 않고서도 소팅한 것과 같은 효과를 낼 수 있다. 소팅된 순서는 인덱스 파일에 있는 레코드 번호를 이용하는 것이다.
이제 디베이스에서 인덱싱을 하는 방법을 배워보자. 우선 인덱스 파일을 만들어야 하는데 이것은 INDEX 명령이 담당한다. INDEX 명령의 형식은 다음과 같다. INDEX ON <;인덱스 필드>; TO <;인덱스 파일>;
여기에서 <;인덱스 필드>;는 인덱싱의 기준이 될 필드의 이름이고, <;인덱스 파일>;은 인덱싱 작업의 결과에 의해 새로 만들어질 인덱스 파일의 이름이다. 디베이스는 인덱스 파일을 다른 파일과 구분하기 위하여 인덱스 파일의 확장자를 .NDX로 고정시켜 놓았다.
PHONE.DBF 파일을 가지고 인덱스 파일을 만드는 시험해 보자. NAME 필드로 인덱스 파일을 만들려면
●index on name to name↲
명령을 사용한다. 인덱스 파일의 이름은 <;인덱스 필드>;와 같게 하는 것이 편리하다. 만약 PHONE필드로 인덱스 파일을 만들고 싶다면
●index on phone to phone↲
과 같이 하면 되고, FEE 필드로 인덱스 파일을 만드는 것은
●index on fee to fee↲
로 가능하다.
INDEX 명령이 SORT 명령에 비하여 못한 점이 하나 있다. 그것은 /D 옵션을 사용할 수 없다는 것이다. 지금까지 설명한 인덱스 파일 만드는 과정은 (그림4)와 같다. 그림에서 볼 수 있듯이 인덱싱에서는 소팅과 달리 레코드의 번호는 바뀌지 않는다. 단지 레코드들의 순서가 현재 선택된 인덱스 파일에 있는대로 나타난다는 것이 다를 뿐이다.
(그림 4)에서 보는 바와 같이 INDEX 명령을 사용하여 인덱스파일을 만들면 자동으로 그 인덱스 파일이 선택되어 사용된다. 그런데 이렇게 하나의 데이터베이스 파일에 여러개의 인덱스 파일을 만들면 인덱스 파일을 교체하는 방법이 필요하다. 이를 위하여 디베이스는 SET INDEX TO명령을 제공하는데, 그 사용법은 다음과 같다.
SET INDEX TO<;인덱스 파일>;
이 명령을 사용하면 손쉽게 인덱스 파일을 바꿀 수가 있다. 그러므로 PHONE.DBF 파일을 이름순으로 보다가 전화번호순으로 보려면
●set index to phone↲
명령을 사용하면 된다.
■인덱스 파일의 관리
SET INDEX TO 명령에 의해 인덱스 파일이 열려 있는 상태에서는 레코드의 삽입이나 삭제에 따라 인덱스 파일이 자동으로 재조정된다. 사용자는 인덱스 파일에 대해서는 신경을 쓸 필요가 없다. 그러므로 데이터베이스 파일을 사용할 때 그 데이터베이스 파일에 관련된 인덱스 파일은 모두 열어 놓는 것이 바람직하다.
이를 위하여 SET INDEX TO명령의 뒤에는 7개까지의 인덱스 파일의 이름을 놓을 수 있다. 그러나 현재의 레코드 순서에 영향을 끼칠 수 있는 것은 이들중 첫번째 인덱스 파일이다. 즉 우리의 예에서
● set index to name, phone, fee↲
명령은 인덱스 파일 NAME.NDX, PHONE.NDX, FEE.NDX을 모두 열어 놓되, 첫번째인 NAME.NDX에 의해 레코드의 순서를 결정하게 된다.
그러나 인덱스 파일을 열어 놓지 못한 상태에서 데이터베이스 파일을 변경하였거나 인덱스 파일이 손상된 경우에는 REINDEX 명령을 내리면 SET INDEX TO. 명령으로 열려 있는 모든 인덱스파일들을 다시 만들어준다.
경우에 따라서는 인덱스 파일을 열어 놓는 것이 바람직하지 않을 때도 있다. 그럴 때는 CLOSE INDEX 명령을 사용하여 인덱스파일들을 닫아주면 된다.
■인덱스 파일을 이용한 검색
지난호에서 우리는 LOCATE명령을 이용하여 레코드를 검색해 보았다. 그러나 이 방법은 좀 느리다. 그 이유는 현재의 레코드부터 마지막 레코드까지 레코드 하나 하나를 조건에 맞는 것인지 아닌지 검사해야 하기 때문이다. 그런데 인덱스 파일이 열려 있는 상태에서는 인덱스 필드에 의해 레코드들이 소트되어 있으므로 이를 이용하면 빠른 속도로 검색이 가능하다. 단 검색의 대상은 인덱스 필드에 한정된다는 것에 유념해야 한다.
인덱스 파일을 이용한 검색 명령에는 FIND와 SEEK가 있다. 두 명령의 사용법은 다음과 같다.
FIND <;문자열>;
SEEK <;식>;
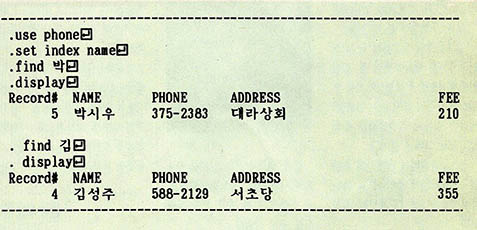
여기에서 <;문자열>;은 따옴표를 두르지 않는 문자열이고, <;식>;은 숫자나 문자열 (이 문자열은 따옴표로 둘러 싸아야 한다) 혹은 변수를 포함할 수 있다. SEEK 명령에 대해서는 다음 기회에 다루기로 하고 여기서는 FIND 명령의 사용 예를(그림 5)에 보였다.
FIND 명령은 인덱스 필드의 내용이 주어진 문자열을 포함하고 있는 첫번째 레코드를 찾아준다. 찾아낸 레코드의 내용을 보여주는 것은 아니므로 확인을 하기 위해서는 DISPLAY와 같은 명령을 이용한다. 만약 그런 레코드가 없다면 "No find." 메시지를 출력한다.
이번 호에서 다룬 인덱싱 기법은 디베이스의 핵심적인 부분이다. 디베이스가 큰 데이터베이스 파일들을 별 무리없이 다룰 수 있는 것도 인덱싱 기법의 덕이라고 해도 과언은 아닐 것이다. 이제 디베이스에 대해서 기본적인 사항들은 어느 정도 익힌 셈이므로, 다음 호부터는 '디베이스의 꽃'이라고 불리우는 프로그래밍 방법에 대해서 다루고자 한다.