컴퓨터에 사물을 식별할 수 있는 '눈'을 달아준다면 '생각하는 컴퓨터' 인공지능연구는 한층 진일보할 것이다.
소년시절에 동화를 읽으면서 '사람과 같이 생각하고 판단하는 컴퓨터가 존재할 수는 없을가'라는 생각을 가졌던 사람들이 많을 것이다. 아직까지는 이러한 컴퓨터가 만들어지지 않았지만, 머지않은 장래에 현실화될 수 있을 것으로 예측되고 있다. 인공지능(Artificial Intelligence, AI)이라는 학문이 이와같은 역할을 담당하고 있다. 80년대 초반까지만 하더라도 인공지능은 우리에게 매우 생소한 분야였다. 그러나 요즈음 많은 분야에서 지능형 기계나 지능형 컴퓨터에 대해 이야기하는 것을 자주 듣게 되면서 우리생활에 아직까지 구체적인 실체를 나타내지는 않았지만 점점 가까이 접근해오는 것을 느끼게 된다.
정보의 80%를 시각에 의존
인공지능연구의 진전에 따라 지금까지 대부분 수치계산 및 단순처리 작업에 치중됐던 컴퓨터의 기능은 좀 더 지능화되는 작업으로 전환되고 있다. 90년대에는 이러한 변화가 더욱 가속화될 것으로 예측된다. 미국의 시장조사 기업 IRD는 1985년에 1억 5천만달러에 불과했던 인공지능 시장이 금세기말에 이르면 85억달러 규모에 달해 매년 60%이상의 성장을 보일 것으로 전망하고 있다.
1993년부터 2000년 사이의 인공지능 시장의 분포를 하드웨어 소프트웨어및 서비스로 나누어보면 다음과 같다. 하드웨어는 계속 약 30%의 비중을 차지할 것이고 소프트웨어는 29%에서 62%로 증가하며 서비스는 38%에서 9%로 감소할 것으로 예측된다는 것이다. 이에따라 소프트웨어와 하드웨어에 대한 지속적인 투자가 필요하다고 보고 선진국에서는 인공지능에 대한 대규모 연구프로젝트를 추진하고 있다. 미국에서는 군사프로젝트인 SCSP나 SDI등에서 이 분야를 최우선 개발과제로 삼고 있다. 유럽에서는 유럽공동체(EC)차원에서 Esprit나 Eureka, 일본에서는 제5세대 컴퓨터개발등의 프로젝트를 통하여 이에 대한 기술개발에 심혈을 기울리고 있다.
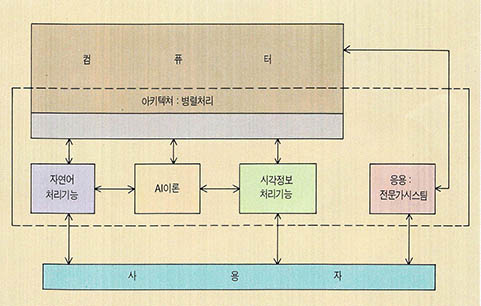
이와 같은 투자에 힘입어 생각하는 컴퓨터를 만들고자하는 인공지능의 궁극적인 목표는 차츰 성과가 드러날 것으로 생각된다. 지능형 컴퓨터의 구성에 필요한 핵심기술을 분류해 보면 ▲인공지능이론 ▲컴퓨터비전 ▲자연어이해 ▲전문가 시스팀 ▲병렬처리컴퓨터구조 등이 있다. 이들의 유기적인 결합을 살펴보면 (그림1)과 같은데 분야의 균형적인 발전에 따라 인간과 컴퓨터 사이에는 어떠한 제약도 없는 상태에서 대화가 가능해질 것이다. 이렇게 될 경우 컴퓨터의 탁월한 계산능력을 빌어 보다 정확하고 빠른 판단을 얻을 수 있으며, 때때로 조언(?)을 듣는 것도 가능해진다.
우리가 (그림1)을 보면 지능형컴퓨터에는 사람과 마찬가지로 감각기관에 해당되는 부분이 존재하는 것을 알 수가 있다. 즉 음성이나 문장을 이해할 수 있는 자연어 처리기능과 카메라를 통해 들어오는 영상정보를 분석하여 사물을 이해하거나 판별하는 시각정보처리기능 등이 있다.
인간은 외부에서 받아들이는 정보의 80%이상을 시각정보에 의존한다. 이러한 사실에 비추어 볼때 컴퓨터에 시각장치를 첨가시켜 주어진 영상을 해석하고 추론하여 이해할 수 있다면 인간과 컴퓨터가 상호간에 대화의 통로를 여는데(인터페이스기능) 획기전인 전기가 마련될 것이다. '백문이 불여일견'이라는 속담처럼 컴퓨터에 시각장치를 부여하게 되면 감정의 변화에 따른 미묘한 표정의 변화나 행동도 알아낼 수가 있게 된다. 이것이 컴퓨터비전이라는 분야이다. 컴퓨터비전은 지능형 컴퓨터를 구성하는데 필수불가결한 요소이다. 이글에서는 컴퓨터비전의 현황과 응용 등에 관하여 살펴본다.
컴퓨터가 직접 볼 수 있다면

(그림2)와 같은 사진을 생각해보자. 사진에서 자동차나 기차를 찾으라고 한다면 누구나 실제 기차나 자동차의 위에서 본 모양을 모르더라도 별 어려움을 느끼지 않고 찾아낼 것이다. 우리가 물체를 찾아내는 과정은 우선 전체적인 사진에서 물체를 하나씩 살펴보고, 주위와의 상황을 고려하여 종합적인 판단으로 뇌에서 결정을 내리게 된다. 그런데 이와같은 사고는 우리가 어릴때부터 배움(Learning)이라는 반복적인 과정을 거쳐 순간적으로 판단이 일어나기 때문에 우리가 별로 오랫동안 인식하지 않고 답을 얻게된다. 상황이 더 복잡한 경우에도 마찬가지의 과정을 거치게 된다.
해외의 모르는 지역을 여행할때도 우리는 눈으로 들어오는 정보를 갖고 판단을 내리게 된다. 이때 그지역에 대한 지도를 갖고 있다면 좀더 쉽고 정확한 판단을 내릴 수가 있다. 그러나 컴퓨터에게 똑같은 질문을 하면 문제는 그리 간단히 풀리지가 않는다. 컴퓨터에게 지식을 가르쳐주거나 표현하는 것도 쉽지가 않거니와 정보를 어떻게 유기적으로 구성하여 정리해야 하는가라는 문제가 제기된다. 이를 위해서는 외부의 장면을 카메라를 통하여 습득하고 그것을 컴퓨터가 저장하기 쉬운 형태로 변환시켜야 한다. 즉 밝기를 크기(gray Level)로 변환하여 저장한 후 기계적인 방법에 의해 기초적인 특성을 찾게된다. 이때에 찾는 특성으로는 외곽(boundary)에 대한 정보들로서 에지를 찾거나(edge detection)또는 영역확장(region growing)등의 방법을 사용한다. 이와같은 단계를 '전(前)처리' 또는 '저급수준의 처리'이라고 한다. 대부분의 영상처리(image processing)가 이와같은 방법에 치중하고 있다.
이 단계에서 얻어진 정보는 상호간의 유기적인 관계가 미약한 독립적인 형태로 존대한다. 이들을 다시 재결합하고, 우리가 알고있는 지식을 사용하여 추론을 통해 인지하는 과정을 다시 거쳐야만 물체의 판별이나 이해가 가능해진다.
이와같은 것을 '중급및 고급처리단계'라고 하며, 우리가 문제풀이에서 요구하는 목표를 달성할수가 있는 수준이 되는 것이다. 이과정에서는 영상자체에 대한 정보보다 물체에 대한 기술이나 의미등을 내포하고 상호 관계적인 구조로 연결이 되어 있다. 또 추론이나 배합(matching)등을 거쳐 전체적인 영상에 대한 이해를 추구하게 된다. 이러한 과정을 거쳐 컴퓨터가 영상을 이해하게 되면 컴퓨터비전의 목표가 달성되었다고 말할 수 있다.
스테레오비전
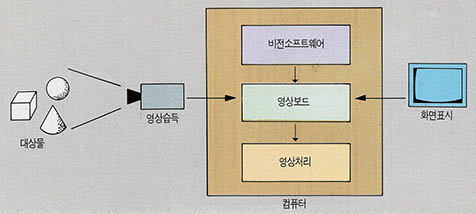
컴퓨터비전은 (그림3)과 같은 형태로 구성된다.
카메라및 화면표시장치, 영상입출력을 위한 하드웨어 등이 있으며, 처리를 수행하는 비전용 소프트웨어가 컴퓨터에 내장되어 있다. 비전용 소프트웨어의 개발에는 눈에 대한 모델화 작업과 영상의 처리로 크게 나누어지는데 영상처리에 관심을 둔 많은 연구가 진행되고 있다.
영상의 처리를 위한 소프트웨어에는 VISILOG나 SPIDER와 같이 상용화된 제품등도 있으며 연구소나 학교등에서 필요에 따라서 개발하기도 한다. 개발되는 소프트웨어의 기능을 차원적인 면에서 살펴보면 대체로 2차원적 처리와 3차원적 처리로 나눌 수 있다. 2차원 처리란 일반적으로 1대의 카메라를 통하여 정보를 습득하여 깊이에 대한 정보를 잃어버린 상태로 영상을 얻는 방식을 말한다. 현재까지의 많은 영상처리들이 2차원적인 영상을 대상으로 하여 이룩되었으며, ▲글자 및 문서인식 ▲패턴인식 ▲자동검색 등의 분야에서 좋은 결과를 보여주고 있다. (그림4)와 같이 부품을 구별해내기 위하여 에지를 찾는 경우등이 대표적인 예이다.

한편 공장자동화에서는 기계나 로봇에 시각장치를 부착하는 제품들이 늘어나고 있다. 이를 기계비전(Machine Vision)또는 로봇비전(Robot Vision)이라고 부르는데 이러한 기계들이 작동하는데는 깊이에 대한 정보가 필수적이다.
3차원 정보 즉, 깊이에 대한 정보를 얻어내는 방식에는 크게 3가지를 생각할 수가 있다. 첫번째가 1대의 카메라에 보조광원 장치를 부착하는 형태이다. 일반적으로 (그림5)에서 보는 바와 같이 레이저를 사용하고 있다. 레이저에 투영된 줄무늬의 윤곽(Profile)을 통하여 깊이 정보를 추출해낸다. 이와같은 시스팀을 레인지 파인더(range finder)라고 부른다.
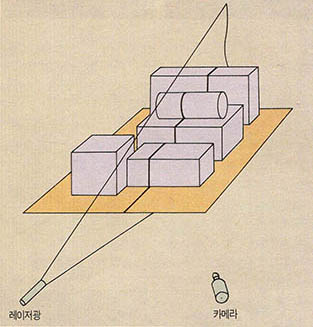
레인지 파인더에서는 종합적인 3차원 물체를 구성함에 있어서 물체를 회전시켜야 하는 단점이 있다. 이러한 단점을 해결하기 위해 일반 광원의 앞부분에 그물망을 첨가하여 물체의 깊이에 따라 모양이 달리 나타나도록 한 것이 두번째 방식이다.
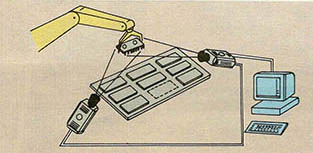
세번째로는 사람의 눈과 마찬가지로 2대의 카메라를 사용하는 방법이다(그림6). 이 방법은 삼각측량의 원리를 이용한 것으로 스테레오비전(Stereo Vision)이라고 부른다. 특히 이 방식은 우리 눈의 구조와 비슷한 특성을 갖고 있으므로 많은 연구가 이루어지고 있다. 그러나 스테레오비전은 두장의 사진에서 같은 부분을 찾아내는데에 아직까지는 무척 많은 시간이 걸려 고속의 알고리즘 개발이나 병렬처리용 컴퓨터에 대한 연구가 선행되어야 할 것으로 보인다.
병렬처리능력이 향상돼야
일반적으로 영상정보는 2차원 또는 3차원의 정보를 처리해야만 하므로 여러가지의 신호들중에서 방대한 양의 데이터 처리능력을 요구하고 있다.
그러므로 의미있는 정보를 얻기 위해서는 방대한 처리능력의 컴퓨터나 영상처리용의 특별한 시스팀이 요구된다. 이에따라 많은 제품들이 제작되어지고 있으며 많은 경우가 병렬처리 컴퓨터 구조를 갖고 있다. 그러나 현재까지의 컴퓨터는 병렬처리의 개념을 주로 저급레벨의 처리를 위한 구조에만 적합하도록 되어 있다.
비 에 관한 하드웨어들은 저급레벨에서는 병렬처리를, 중급 및 고급레벨처리에는 순차구조를 갖도록 구성되어 처리속도에 제한을 받고 있는 실정이다. 중급및 고급레벨에서의 병렬처리 컴퓨터구조에 관한 연구가 필요성을 더해가고 있다.
자동검색 시스팀

컴퓨터비전을 이용한 자동검색시스팀은 산업체에서 요구하는 자동화를 촉진시킬 수 있는 매우 중요한 분야이다.
이용가능한 예를 들어보면, 볼트나 너트와 같은 제품의 직경을 측정하여 합격 불합격을 판별해내거나, 천이나 옷감에 구멍이 뚫여있는가 또는 음료수의 용량이 적합한가를 판별하는등 매우 다양한 응용분야에 쓰여질 수 있다.
여기에서는 프랑스 그레노블시에 위치한 ITMI사에서 개발한 자동검색 시스팀 두가지를 소개한다. 먼저 실리콘 웨이퍼의 위치를 측정하는 예를 들어본다.
(그림7)의 (a)와 같이 웨이퍼가 놓이면 사진을 통하여 (b)와 같이 외곽과 웨이퍼의 중심을 찾아서 직경을 산출하고 (c)와 같이 4각형 외곽을 확정한다. 이것을 토대로하여 웨이퍼의 방향을 (d)와 같이 찾아내어 정확한 위치를 고정시켜 봉합 과정에 응용될 수 있도록 한다. 이때의 장점은 오퍼레이터가 없어도 되므로 클린룸 환경의 요구에 매우 적합하다.
두번째로는 3차원적인 처리에서 (그림8)과 같이 형태분석을 통하여 부품을 찾아 PCB(인쇄회로기판)의 위치에 부품을 삽입시키는 장치를 들 수가 있다. 이경우는 로봇의 위치제어도 할 수가 있으며 영상정보의 분석에 따라서 로봇이 스스로 판단할 수 있으므로 NC(수치제어)기계의 단점도 보완할 수가 있다.
잠재력 풍부한 국내 연구진
우리나라에서는 현재까지 컴퓨터비전 분야에 대한 연구투자가 매우 미약하였다. 현재까지 연구된 결과를 보면 시스템공학센터의 지문인식 시스팀, 과학기술원 김 진형 교수팀의 한글문서인식시스팀'실눈' 등이 대표적인 예이다.
그러나 비전분야에는 해외에서 연구를 하고 귀국한 박사의 수효가 20명을 넘고 있으므로 연구에 대한 잠재력은 상대적으로 풍부한 실정이다. 다행히 선진국에서 많은 제품들이 생산되고 최근 자동화에 대한 열기가 국내에서도 고조되고 있다. 비전시스팀은 산업체에 곧바로 응용이 가능하기 때문에 국내기업들이 관심이 증가되고 있는 추세이다.
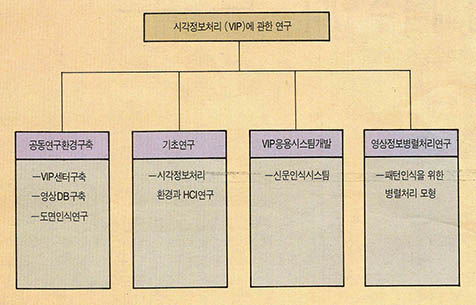
과학기술처에서도 이분야의 중요성을 인식하여 소프트웨어분야 인공지능 연구의 새로운 국책과 제로 시각정보처리(Visual Information Processing: 약칭 VIP)과제를 설정하였다. 연구의 구성형태를 보면 (그림9)와 같다. 한국과학기술원과 시스템공학센터 및 몇몇 대학들이 참여하고 있는 이과제에는 15명의 교수와 50명의 연구원이 투입되어 선진국의 노하우를 국내기술로 소화시키고자 노력하고 있다.
아직은 초보적 연구단계
이제까지 컴퓨터비전의 기술현황과 동향에 대하여 살펴보았다. 과학자들의 목표는 컴퓨터에서의 영상이해에 궁극적인 목표를 두고 있다. 그러나 아직까지는 초보적인 단계로서 어떻게 해야한다는 일반화된 방법이 제시되어 있지 않다. 다만 연구에 대한 열기를 반영하듯 미국에서는 영상이 해워크숍(Image Understanding Workshop)이 매년 개최되어 수백명 이상의 연구자가 열띤 토론의 장을 마련하고 있어 머지않은 장래에 좋은 결실을 맺을 것으로 보인다.
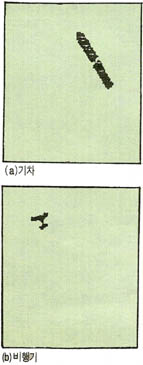
필자가 재직중인 중앙대학교 비전연구실에서도 (그림2)에서 보인 장난감 사진의 이해에 관한 연구를 수행하였다. 영상을 해석하고 추론한 결과 (그림10)에 보인 것처럼 기차와 비행기의 형태를 찾아내었다. 아직까지는 장난감을 가지고 간단한 경우에 관하여 응용을 했지만 가능성은 충분히 확인할 수가 있었다. 앞으로의 지속적인 연구에 따라서는 실제 임의의 영상이해에도 접근이 가능하리라고 본다.
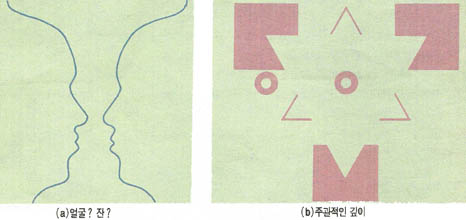
그러나 '마'(Marr)가 지적하였듯이 아무리 연구를 하여도 좀처럼 풀지 못하는 문제도 있다. (기림11)에 보인 것과 같이 사람으로도 술잔으로도 해석할 수 있는 문제와, 컴퓨터가 찾을 수 없는 주관적인 깊이의 문제등을 예로 들수가 있다. 이런 문제를 해결하기 위한 컴퓨터과학자들의 끈질기고 창의적인 도전이 계속될 것이다.