
핵물리학자의 연구가 “헥! 헥!” 소리가 날 정도로 힘든 이유가 뭔지 아세요? 수천억 개 입자를 발사해 1초에 수천만 번씩 충돌시켜야 해서? 엄청 큰 가속기를 만들어야 해서? 다 맞는 이야기지만, 마지막 단계야말로 빠질 수 없어요. 바로 실험 후 해일처럼 닥쳐오는 데이터 속에서 원하는 정보를 찾는 과정이죠. 모래사장에서 모래알 하나를 찾는다고 생각해 보세요. 유럽입자물리연구소(CERN)에서 일하던 팀 버너스리가 ‘www’를 개발한 심정을 이해할걸요?
‘데이터 보정’이라는 힘들고 고된 일
모래사장에서 모래알 하나를 찾는 일, 2015년에 제가 하고 있었어요. 미국 상대론적 중이온 가속기(RHIC)에서 입자 충돌 실험인 PHENIX에 참여하고 있을 때였지요. 양성자를 서로 충돌시키면 나오는 ‘바텀 쿼크*’가 한 번 더 붕괴해 나오는 입자를 찾아야 했어요. 이 작은 입자는 양성자가 충돌한 지점에서 500μm*(마이크로미터) 떨어진 곳에서 발생해요. 이론적으로는 그렇죠. 진짜 발견하려면 입자의 위치와 경로를 정확히 측정해야 해요.
제가 입자를 검출하기 위해 사용했던 실리콘 검출기에는 작은 센서인 ‘픽셀’들이 모눈종이처럼 붙어 있어요. 가로와 세로가 약 100μm로 매우 작은 픽셀은 입자가 지나가면 신호를 보내요. 이 신호 정보로 입자들이 검출기를 지나며 마주친 픽셀들을 모으면 각 입자들의 경로를 알아낼 수 있지요. 그 경로를 따라 각 입자가 처음 생겼던 곳을 추적해 가는데, 만약 입자의 시작점이 양성자 충돌 지점에서 수백μm 떨어져 있다면 바텀 쿼크가 붕괴하며 나온 입자라고 추정할 수 있어요.
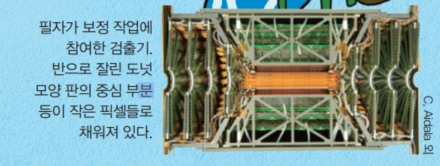
문제는 픽셀이 너무 작아 완벽하게 줄을 세우기 어렵다는 거예요. 픽셀은 여러 개가 모여 한 층을 이루고, 이 층이 여러 개 모여 검출기를 이뤄요. 검출기가 입자의 경로를 정확히 측정하려면 각 층이 서로 뒤틀리지 않고 나란히 정렬돼야 하지만, 100μm 크기의 픽셀들이 정확히 정렬돼도록 검출기를 만들기는 불가능해요. 그렇다고 해서 1mm라도 어긋나면 한 층을 지나간 입자가 다음 층에서는 엄청 멀리 떨어진 픽셀을 지나간 것처럼 측정될 거예요.
이런 한계를 극복하기 위해 물리학자들은 픽셀들이 정확히 정렬되어 있지 않다고 가정하고, 실험 후에 컴퓨터로 데이터를 보정해요. 픽셀 하나는 좌우, 위아래, 앞뒤로 이동할 뿐만 아니라 회전할 수도 있어 모든 변수를 고려해 계산하지요. 이 작업은 시간이 매우 오래 걸려 저도 2년간 보정 작업을 거친 후에야 원하는 입자를 찾을 수 있었답니다.
가속기에서 영화 10만 편에 달하는 데이터가 쏟아진다?!

여행지에서 무심코 사진을 찍으면 어느새 카메라에 저장 공간이 부족하다는 경고 메시지가 뜨지요? 사진의 해상도가 올라갈수록 용량이 커져 더 많은 저장 공간이 필요해요.
이와 같은 일이 가속기 실험에서도 일어나요. 입자 충돌 실험에서 발생하는 입자는 검출기를 지나면서 마주치는 픽셀에 흔적을 남기는데, 이 신호를 저장하는 것이 사진을 찍는 것과 같아요. 사진처럼 검출기도 픽셀이 많아질수록 정밀해져요. 그럴수록 저장해야 할 데이터량도 많아지지요.
실리콘 검출기 중에서는 가로와 세로의 길이가 각각 3cm, 1.5cm인 칩 하나에 픽셀이 약 50만 개나 있는 것도 있어요. 이런 실험에서 저장하는 데이터는 1년에 1PB(페타바이트) 이상인데, 1PB는 요즘 컴퓨터에 사용되는 하드디스크의 용량인 1TB(테라바이트)의 약 1000배예요. 용량이 10GB(기가바이트)인 초고화질 영화 십만 편에 해당하는 어마어마한 크기죠.
방대한 데이터를 저장하고 처리하려면 컴퓨터도 많이 필요해요. RHIC의 컴퓨팅 시설에는 CPU*가 약 3만 개 있어요. CPU가 하나만 있다면 데이터를 처리하는 데 1달 정도 걸릴 것을, 3만 개를 동시에 작동시켜 몇 분만에 끝내는 거죠! 전 세계 약 천 명의 연구자들이 이 컴퓨팅 시설에 접속해 충돌 실험 데이터를 분석한답니다.
물리학자가 www를 만든 이유

유럽입자물리연구소(CERN)의 컴퓨팅 시설은 더 독특해요. 처리하는 데이터량에 비해 연구소 안에 컴퓨터가 많지 않죠. 이는 데이터가 세계 곳곳에 나뉘어 있기 때문이에요. 여러분도 크롬 같은 웹브라우저에 웹사이트 주소를 입력할 때 앞에 ‘www’가 붙는 걸 본 적이 있을 거예요. ‘www’는 URL이라는 고유한 주소를 이용하는 정보 검색 시스템이에요.
www는 CERN에서 개발됐어요. CERN은 1980년대까지 데이터를 여러 컴퓨터에 나눠 저장하는 바람에 하나의 정보를 찾으려면 수많은 컴퓨터를 뒤져야 했어요. 그러다 보면 있는 정보도 잘 찾을 수 없었죠.
이에 CERN에서 물리학을 연구하던 팀 버너스리 연구원은 1989년 3월 www를 고안했어요. 여러 컴퓨터에 나뉜 정보에 각각 주소를 지정해 쉽게 검색하도록 한 거였지요. 도서관이 각 책에 위치 코드를 달아 분류하는 것처럼요. www를 이용하면 CERN 밖에 있는 물리학자들도 정보를 빠르게 교환할 수 있어 공동 연구가 가능해졌어요. 이후 일반 사용자도 쉽게 사용할 수 있는 웹브라우저가 개발되면서 지금과 같은 인터넷 환경이 만들어졌지요.
2008년부터 CERN은 전 세계의 컴퓨터를 하나로 묶은 ‘WLCG’라는 시설을 구축해 왔어요. 전 세계 42개 국가의 170여 개 컴퓨팅 시설에 데이터를 나누어 저장하지요. WLCG에는 매년 10PB 이상의 데이터가 새로 저장돼 전 세계 약 만 명에 가까운 연구자들이 이용해요. 한국의 기초과학연구원도 WLCG에 속하는 덕에 국내 연구원도 LHC에서 이뤄지는 실험에 참여할 수 있답니다.
용어정리
*쿼크 : 더이상 쪼갤 수 없는 기본 입자 중 하나. 바텀 쿼크를 포함해 6가지 종류가 있다.
*μm(마이크로미터) : 길이 단위. 1μm는 1mm보다 1000배 짧다.
※필자소개
임상훈(부산대학교 물리학과 교수)
고에너지 핵물리학을 연구한다. 미국의 상대론적 중이온 가속기(RHIC)와 유럽의 거대 강입자 가속기(LHC)에서 각각 피닉스(PHENIX) 실험과 앨리스(ALICE) 실험에 참여한다.











