한 해에도 수만 권의 책이 출간되지만, 이 중 독자들의 눈길을 사로 잡는 건 고작해야 100권도 채 되지 않는다. 잘 나가는 책에는 어떤 비밀이 있는 걸까. 수려한 문장? 매력적인 캐릭터? 세밀한 상황 묘사? 최근 인공지능을 이용해 이 비밀을 푼 과학자가 있다. 이 과학자에게 우리나라의 대표 전래동화, 콩쥐팥쥐의 분석을 의뢰했다.
‘제5도살장’으로 유명한 미국의 소설가 커트 보니것은 1995년 한 강연에서 이런 말을 했다. “이야기에는 ‘모양’이 있다. 하수구에 빠졌다가 다시 나온 남자, 이성친구와 헤어졌다가 다시 만난 사람 등, 각 사건마다 인물의 감정 변화로 이야기를 분류할 수 있다.” 보니것의 이론은 많은 이들의 공감을 샀지만, 분석하는 이들마다 이야기의 모양이 제각각이라 혼선을 겪고 있었다. 서로 다른 감정선(감정의 흐름을 높낮이로 표현한 것) 모양의 수는 3개에서 많게는 30개까지 범위도 너무 넓었다.
지난해 미국 버몬트대 앤드류 레건 교수팀은 인공지능을 이용해 이야기의 감정선을 정리하고 분류하는 방식으로 인기 있는 소설의 공통점을 찾고, 이 연구결과를 ‘유럽 물리학 저널 데이터 사이언스’ 11월 4일자에 공개했다.
이야기 흐름의 비결 ‘감정선’
연구팀은 인류가 만든 자료를 모아서 전자정보 형태로 저장해 배포하는 ‘프로젝트 구텐베르크’에 올라온 이야기 중 150번 이상 다운로드된 1327개의 이야기를 선정했다. 그리고 행복도를 측정할 수 있는 도구인 ‘헤도노미터(Hedonometer)’를 적용해 이야기를 분석했다.
헤도노미터는 단어가 가지고 있는 감정을 수치화하는 측정도구다. 글을 입력하면 그 점수를 자동으로 계산해준다. 예를 들어 hell(지옥), fear(두려움), die(죽음)와 같은 단어들은 음의 값을 갖고, like(좋다), mother(엄마)와 같은 단어들은 양의 값을 갖는다. 이 총합을 더해 행복감을 계산한다. 연구팀은 1만 개의 단어마다 이야기를 잘라 단어 덩어리를 만든 뒤, 각 덩어리별 감정을 헤도노미터로 측정해 곡선을 그렸다. 마치 ‘인생의 그래프’ 같은 모습이다.
중요한 건 이제부터다. 연구팀은 1300여 개 이야기의 감정선을 분석한 뒤 6가지 유형으로 나눴다. 각각의 유형에는 ‘거지에서 부자로(상승곡선)’, ‘부자에서 거지로(하락곡선)’, ‘하수구에 빠진 남자(하락-상승)’, ‘이카루스(상승-하락)’, ‘신데렐라(상승-하락-상승)’, ‘(하락-상승-하락)’라는 이름을 붙였다. 대부분 감정선을 대표할 수 있는 신화 속 이야기거나 우화의 제목을 땄다.
1000개가 넘는 감정선 6가지로 분류해
1000개가 넘는 감정선을 단 여섯 가지 유형으로 분류하기 위해서는 인공지능의 힘이 필요하다. 연구팀은계층적 군집화(Hierarchical clustering) 알고리즘을 이용했다. 가장 유사한 두 그룹을 계속 묶어 비교하는 방식으로, 길이나 높낮이가 제각각인 이야기들을 분류했다. 특정 감정선을 입력 값으로 받아 가장 유사한 분류군을 찾는 데에는, 인공신경망을 활용하는 자기조직화 지도(SOM, Self-Organizing Map) 알고리즘을 이용했다.
소설은 이 여섯 가지 감정선이 혼합된 상태로 나타난다. 연구팀은 많이 다운로드된 이야기들의 공통점을 분석했다. 그 결과 이야기에서 가장 많이 나타나는 유형은 상승곡선, 하락곡선, 하락-상승, 상승-하락 곡선이었지만 이것이 가장 인기가 많은 것은 아니었다. 실제 인기가 많은 이야기에는 ‘상승-하락’의 곡선을 보이는 이카루스, ‘하락-상승-하락’인 오이디푸스, ‘하락-상승’인 하수구에 빠진 남자 유형이 적어도 하나는 포함돼 있었다. 레건 교수는 과학동아와의 e메일 인터뷰에서 “이번 연구 결과는 이후 소설가들에게 어떤 유형의 감정곡선이 인기가 많은지를 알려주는 좋은 지표가 될 것”이라고 말했다.
#한국 대표 전래동화 ‘콩쥐팥쥐’를 분석하다
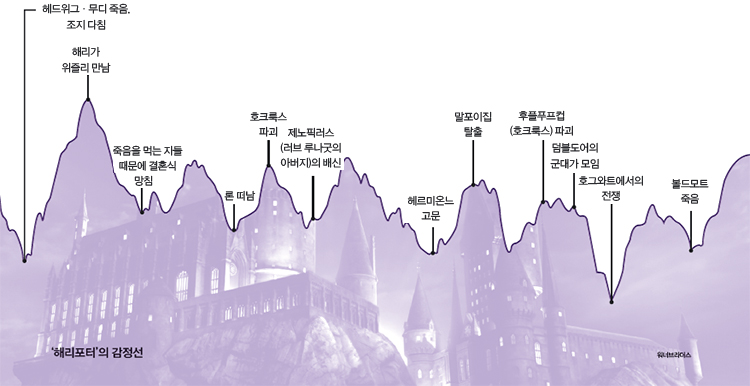
연구팀은 논문을 통해 수년간 베스트셀러 자리를 놓치지 않고 있는 영국 소설 ‘해리포터와 죽음의 성물’의 감정곡선을 분석했다.
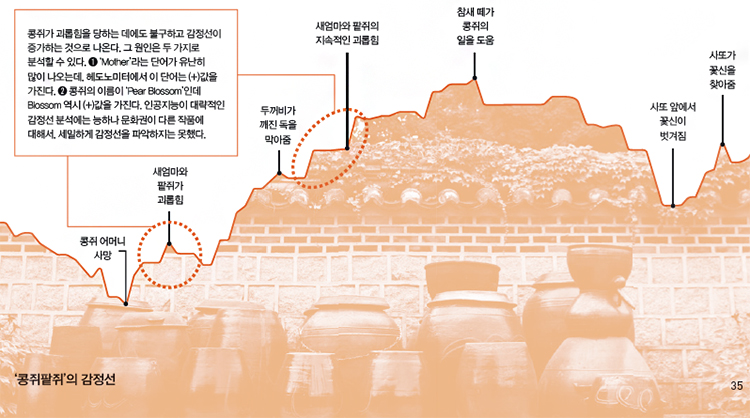
소설의 길이가 워낙 길다 보니 여러 감정선이 혼합돼 있는 것을 알 수 있었다. 과학동아는 ‘과연 우리나라의 전래동화 역시 인공지능을 이용해 감정선을 분석할 수 있을까’해서 앤드류 레건 교수팀에 영어로 번역된 ‘콩쥐팥쥐’(‘The Korean Cinderella’, Shirley Climo, 1996)의 분석을 의뢰했고, 해리포터에 비해 비교적 간단한 감정선을 확인할 수 있었다. 이야기의 평균 행복 지수는 6.4로, 해리포터의 5.45에 비해 높은 편이었으며, 하락-상승-하락의 구조를 보이며 오이디푸스 형태의 감정선을 가졌다. 가장 행복지수가 낮았을 때는 콩쥐의 어머니가 사망했을 때였고, 행복지수가 가장 높았을때는 쌀 세 섬을 찧어놓으라고 했던 새어머니의 명령을 참새 떼의 도움을 받아 끝냈을 때였다.
분석을 마친 레건 교수는 과학동아와의 e메일 인터뷰에서 “한국어와 영어의 체계가 많이 달라 미국 문화권의 이야기들보다는 정확성이 조금 떨어질 수 있다. 인공지능을 활용해 언어와 문화에 따라 감정이 어떻게 달라지는지, 이것이 문학에서는 어떻게 드러나는지에 대해 추가로 연구할 계획”이라고 말했다. 그때 한번 더 의뢰를 맡기면 더 정확한 분석을 제공하겠노라는 농담도 잊지 않았다.
연구팀은 논문을 통해 수년간 베스트셀러 자리를 놓치지 않고 있는 영국 소설 ‘해리포터와 죽음의 성물’의 감정곡선을 분석했다.
소설의 길이가 워낙 길다 보니 여러 감정선이 혼합돼 있는 것을 알 수 있었다. 과학동아는 ‘과연 우리나라의 전래동화 역시 인공지능을 이용해 감정선을 분석할 수 있을까’해서 앤드류 레건 교수팀에 영어로 번역된 ‘콩쥐팥쥐’(‘The Korean Cinderella’, Shirley Climo, 1996)의 분석을 의뢰했고, 해리포터에 비해 비교적 간단한 감정선을 확인할 수 있었다. 이야기의 평균 행복 지수는 6.4로, 해리포터의 5.45에 비해 높은 편이었으며, 하락-상승-하락의 구조를 보이며 오이디푸스 형태의 감정선을 가졌다. 가장 행복지수가 낮았을 때는 콩쥐의 어머니가 사망했을 때였고, 행복지수가 가장 높았을때는 쌀 세 섬을 찧어놓으라고 했던 새어머니의 명령을 참새 떼의 도움을 받아 끝냈을 때였다.
분석을 마친 레건 교수는 과학동아와의 e메일 인터뷰에서 “한국어와 영어의 체계가 많이 달라 미국 문화권의 이야기들보다는 정확성이 조금 떨어질 수 있다. 인공지능을 활용해 언어와 문화에 따라 감정이 어떻게 달라지는지, 이것이 문학에서는 어떻게 드러나는지에 대해 추가로 연구할 계획”이라고 말했다. 그때 한번 더 의뢰를 맡기면 더 정확한 분석을 제공하겠노라는 농담도 잊지 않았다.