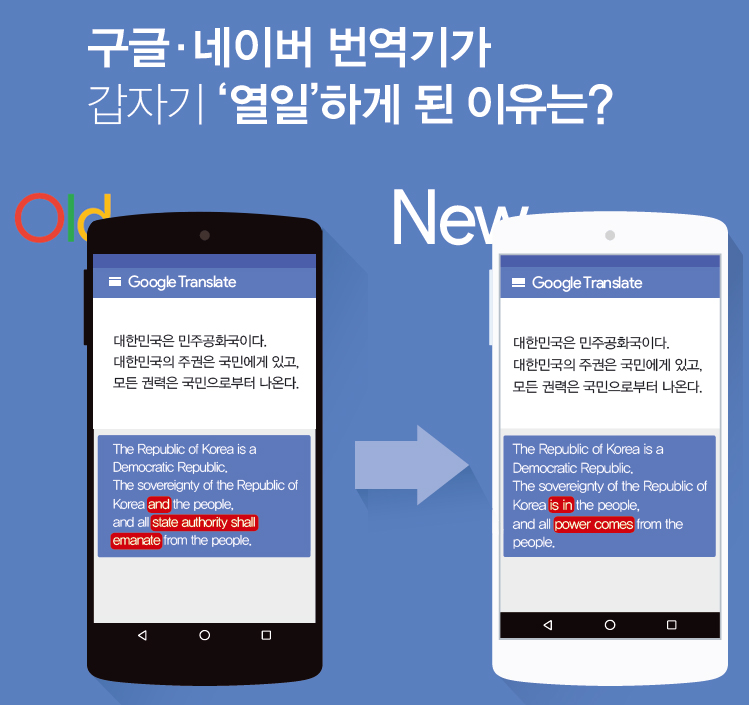

구글 번역기가 달라졌다. 소소한 ‘업그레이드’가 아니라 완전히 새로운 모습이다. 지난 11월 15일 구글은 자사의 공식 블로그를 통해 한국어, 영어, 중국어, 프랑스어, 독일어, 스페인어, 일본어, 터키어 등 8개 언어의 번역에 ‘신경망 기계번역(NMT)’을 적용한다고 밝혔다. 네이버 번역기도 마찬가지다. 가장 눈에 띄는 차이점은 ‘문장의 완결’이다. 이전에는 ‘나는 밥을 먹는다. 맛있게’와 같은식으로 문장이 중간에 뚝뚝 끊겨 ‘이렇게 번역하느니 원문을 보는 게 낫겠다’는 원성이 자자했지만, 이제는 제법 매끄러운 문장으로 번역한다.
번역 단위를 ‘문장’으로 바꾼 것이 핵심
직접 구글 번역기의 품질을 소개하고자, 이번 기사를 준비하면서 가장 많이 참고한 구글 연구진의 논문 중 일부를 발췌했다.

문장의 길이가 상당히 긴데도 불구하고, 의미를 정확하게 파악할 수 있도록 번역했다. 구글 번역기가 이렇게 긴 문장도 무리 없이 번역할 수 있는 핵심적인 이유는 번역의 단위를 ‘구문(phrase)’에서 ‘문장’으로 바꿨기 때문이다. 버락 투로프스키 구글 번역 프로덕트 매니지먼트 총괄 역시 지난 11월 29일, 구글코리아에서 열린 기자간담회에서 “이번 번역기에서 가장 혁신적인 부분은 번역의 단위를 문장으로 바꾼 것”이라고 강조했다.
기존의 ‘구문기반 기계번역(PBMT)’은 번역할 문장을 구문으로 나눈 뒤, 통계를 기반으로 번역한다(기계학습에서의 구문은 단어 3~4개의 조합을 말한다). 예를 들어 ‘사과’를 영어로 번역할 때 ‘apple’로 번역된 것이 10번, ‘apologize’로 번역된 것이 5번이라면, apple로 번역될 확률은 3분의 2다. 즉, 문장을 입력하면 각각의 단어, 혹은 구문을 기준으로, 번역될 수 있는 단어들을 나열하고 그 중 확률이 가장 높은 단어를 선택해 문장을 완성하는 방식이다.
이번에 출시한 구글 번역기는 ‘신경망 기계번역(NMT, Neural Machine Translation)’을 활용한다. 인공신경망은 사람의 뇌 구조를 모사한 학습방법으로, 중요한 기억에 대해서는 연결을 강화하는 뉴런과 시냅스의 작용을 모사한다. PBMT의 경우 문장이 길어지면 서로 멀리 떨어진 단어들을 유기적으로 연결하지 못하는 반면, NMT는 문장 전체를 입력 값으로 받기 때문에 이런 문제가 없다.
투로프스키 총괄은 “신경망 기계번역 기술로 위키피디아, 뉴스매체 등의 샘플문장의 번역 오류가 55~85% 가량 감소했다”고 밝혔다.
100차원 벡터에 문장의 모든 것을 담는다
구글의 신경망 기계번역(GNMT)은 한 문장 전체를 입력값으로 받아 이를 ‘벡터로 치환’한다. 문장의 구조나 문장을 이루는 단어와 조사, 다른 단어들과의 연관성 등 다양한 문장의 특징을 수치로 표현해 공간의 한 점으로 표현했다는 의미다. 수학적 개념인 공간벡터는 O(0, 0, 0), A(0, 3, 1)과 같이 3차원 공간에서의 위치를 나타낸다. 하지만 구글 번역기가 사용하는 문장 벡터는 100차원 이상이다. 문장을 구성하는 단어들도 각각 단어 벡터로 표현되는데 이들 역시 100차원 이상의 벡터로 표현된다.
그도 그럴 것이 우리가 사용하는 단어는 적어도 약 10만 개다. 따라서 다른 단어들과의 관계까지 표현하려면 최소 100차원 이상의 성분을 가져야 한다는 것이 개발자들의 설명이다. 김준석 네이버 파파고 개발팀 리더는 “사실 벡터는 다 수치화된 값이기 때문에 개발자도 각각의 수치가 무엇을 의미하는지는 알 수 없다”며 “다만 학습이 끝나고 난 뒤 유사한 의미의 단어끼리 비교적 가까운 위치에 놓여있는 것을 보고, 벡터가 의미가 유사한 단어들에 대한 정보 값을 가지고 있다고 추정할 뿐”이라고 말했다.
의미적으로 유사한 단어들이 가까운 곳에 위치하면 문맥에 맞는 정확한 번역을 할 수 있다. 예를 들어 새끼 고양이를 의미하는 ‘kitten’은 고양이(cat)와 가까운 곳에 위치할 것이다. Kitten에 상응하는 한국어 정보가 없다고 하더라도 최소한 가까운 곳에 있는 고양이로는 번역이 가능하다. 구글은 논문에서 “강아지는 차보다 고양이와 연관성이 높고, 버락 오바마는 베트남보다는 힐러리 클린턴과 더 연관이 높다”는 예시를 들며 “번역 시스템은 벡터를 기반으로 가장 유사성이 높은, 번역될 확률이 높은 단어로 번역한다”고 밝혔다. 학습하면서 번역을 하는 데 중요한 요소들에 가중치를 부여해 정확도를 높이기도 한다.
기존의 ‘구문기반 기계번역(PBMT)’은 번역할 문장을 구문으로 나눈 뒤, 통계를 기반으로 번역한다(기계학습에서의 구문은 단어 3~4개의 조합을 말한다). 예를 들어 ‘사과’를 영어로 번역할 때 ‘apple’로 번역된 것이 10번, ‘apologize’로 번역된 것이 5번이라면, apple로 번역될 확률은 3분의 2다. 즉, 문장을 입력하면 각각의 단어, 혹은 구문을 기준으로, 번역될 수 있는 단어들을 나열하고 그 중 확률이 가장 높은 단어를 선택해 문장을 완성하는 방식이다.
이번에 출시한 구글 번역기는 ‘신경망 기계번역(NMT, Neural Machine Translation)’을 활용한다. 인공신경망은 사람의 뇌 구조를 모사한 학습방법으로, 중요한 기억에 대해서는 연결을 강화하는 뉴런과 시냅스의 작용을 모사한다. PBMT의 경우 문장이 길어지면 서로 멀리 떨어진 단어들을 유기적으로 연결하지 못하는 반면, NMT는 문장 전체를 입력 값으로 받기 때문에 이런 문제가 없다.
투로프스키 총괄은 “신경망 기계번역 기술로 위키피디아, 뉴스매체 등의 샘플문장의 번역 오류가 55~85% 가량 감소했다”고 밝혔다.
100차원 벡터에 문장의 모든 것을 담는다
구글의 신경망 기계번역(GNMT)은 한 문장 전체를 입력값으로 받아 이를 ‘벡터로 치환’한다. 문장의 구조나 문장을 이루는 단어와 조사, 다른 단어들과의 연관성 등 다양한 문장의 특징을 수치로 표현해 공간의 한 점으로 표현했다는 의미다. 수학적 개념인 공간벡터는 O(0, 0, 0), A(0, 3, 1)과 같이 3차원 공간에서의 위치를 나타낸다. 하지만 구글 번역기가 사용하는 문장 벡터는 100차원 이상이다. 문장을 구성하는 단어들도 각각 단어 벡터로 표현되는데 이들 역시 100차원 이상의 벡터로 표현된다.
그도 그럴 것이 우리가 사용하는 단어는 적어도 약 10만 개다. 따라서 다른 단어들과의 관계까지 표현하려면 최소 100차원 이상의 성분을 가져야 한다는 것이 개발자들의 설명이다. 김준석 네이버 파파고 개발팀 리더는 “사실 벡터는 다 수치화된 값이기 때문에 개발자도 각각의 수치가 무엇을 의미하는지는 알 수 없다”며 “다만 학습이 끝나고 난 뒤 유사한 의미의 단어끼리 비교적 가까운 위치에 놓여있는 것을 보고, 벡터가 의미가 유사한 단어들에 대한 정보 값을 가지고 있다고 추정할 뿐”이라고 말했다.
의미적으로 유사한 단어들이 가까운 곳에 위치하면 문맥에 맞는 정확한 번역을 할 수 있다. 예를 들어 새끼 고양이를 의미하는 ‘kitten’은 고양이(cat)와 가까운 곳에 위치할 것이다. Kitten에 상응하는 한국어 정보가 없다고 하더라도 최소한 가까운 곳에 있는 고양이로는 번역이 가능하다. 구글은 논문에서 “강아지는 차보다 고양이와 연관성이 높고, 버락 오바마는 베트남보다는 힐러리 클린턴과 더 연관이 높다”는 예시를 들며 “번역 시스템은 벡터를 기반으로 가장 유사성이 높은, 번역될 확률이 높은 단어로 번역한다”고 밝혔다. 학습하면서 번역을 하는 데 중요한 요소들에 가중치를 부여해 정확도를 높이기도 한다.
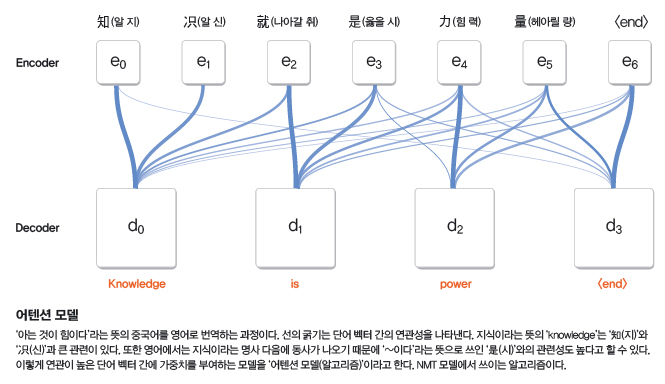
인공신경망, 인공어를 만들다?

번역의 정확성이 높아진 이유는 또 있다. 이전의 PBMT나 대부분의 NMT 모델은 ‘한국어 영어’, ‘영어 한국어’, ‘일본어 영어’ 등 언어에 따라, 또 번역 순서에 따라 각각 다른 모델을 갖는다. 하지만 구글의 신경망 기계번역, GNMT는 8개 언어 모두 하나의 모델이 번역을 소화한다. 번역이 가능한 모든 경우의 수인 56가지 모델을 단 하나의 모델로 가능하게 한 것이다. 구글은 논문에서 “기본 NMT 모델과 설계는 동일하며, 문장이 시작하는 부분에 번역 대상 언어를 지정하기 위한 표지(token)만 넣었을 뿐”이라고 밝혔다.
이런 구글의 다중언어모델은 적은 데이터로 보다 정확하게 번역할 수 있다. 연구진은 이를 구현하기 위해 여러가지 방법으로 학습을 시켰는데, 그 중 여러 언어를 동시에 하나의 언어로 번역하도록 한 학습법은 모든 언어 쌍에서 번역 성능을 향상시켰다. 같은 뜻을 가진 한국어와 일본어 문장을 한번에 입력하고 출력 값은 영어 문장 하나가 되도록 학습시킨 것이다. 김준석 리더는 “NMT는 네이버 번역기 ‘파파고’에서도 사용하고 있는 모델이고, 다른 설계들은 기존에 나와있던 논문을 참고로 한 것이지만, 이 학습법은 아주 독특하다”고 평가했다.
심지어 학습 데이터가 없는 언어 간의 번역도 가능하다. 예를 들어 ‘나는 사과를 먹는다’라는 문장과 같은 뜻의 일본어 ‘와따시와 링고 오 타베루(私はリンゴを食べる)’를 각각 영어로 번역했다고 하자. 이때 한국어에서 일본어로 번역한 학습 데이터가 없어도 ‘나는 사과를 먹는다’를 입력하면 ‘와따시와 링고 오 타베루’로 번역할 수 있다. 이를 ‘제로샷 번역(Zero-shot Translation)’이라고 한다.
구글 연구진은 이런 학습법이 효과가 있었던 것은 인공지능만의 ‘중간 언어(Interlingua)’가 존재하기 때문이라고 추정했다. 구글의 논문에 따르면 제로샷 번역은 NMT에 모든 언어를 아우르는 중간 언어가 존재한다는 것을 보여준다. 사람은 알 수 없지만 NMT가 자체적으로 만든 중간 언어가 있어, 어떤 언어가 들어오든 이 중간 언어를 거쳐 다른 언어로 번역된다는 것이다.
단어를 쪼개 번역 품질 높여
인공신경망이라고 다 좋은 점만 있는 것은 아니다. 사용빈도가 낮은 단어는 잘 번역하지 못한다. 김리더는 “NMT는 사용 단어가 10만 개 이상이 되면 품질이 급격히 떨어진다”며 “학습 데이터의 단어 벡터가 10만 개 이상이 되면 그 중 사용 빈도수가 낮은 단어들은 따로 분류해 모두 동일한 벡터 값을 가지게 한다”고 말했다. 평소에 쓰지 않는 학술용어가 소리 나는 대로 번역되거나, 번역되지 않고 그 단어 그대로 나오는 경우가 이에 해당한다. 이런 단어가 많을수록 번역 품질은 낮아진다.
구글은 단어 벡터의 단위를 하나의 단어가 아닌 자주 쓰이는 알파벳의 조합(sub-word unit)으로 설정했다. 예를 들어 ‘teacher’이 하나의 단어 벡터가 아니고 ‘teach’와 ‘er’이 각각 단어 벡터가 된다. 김 리더는 “이렇게 벡터 단위를 줄여 번역 가능한 단어 조합의 수를 늘리는 것도 좋은 아이디어”라며 “파파고도 최적화된 단어 벡터의 단위를 계속 연구하고 있다”고 말했다.
이런 구글의 다중언어모델은 적은 데이터로 보다 정확하게 번역할 수 있다. 연구진은 이를 구현하기 위해 여러가지 방법으로 학습을 시켰는데, 그 중 여러 언어를 동시에 하나의 언어로 번역하도록 한 학습법은 모든 언어 쌍에서 번역 성능을 향상시켰다. 같은 뜻을 가진 한국어와 일본어 문장을 한번에 입력하고 출력 값은 영어 문장 하나가 되도록 학습시킨 것이다. 김준석 리더는 “NMT는 네이버 번역기 ‘파파고’에서도 사용하고 있는 모델이고, 다른 설계들은 기존에 나와있던 논문을 참고로 한 것이지만, 이 학습법은 아주 독특하다”고 평가했다.
심지어 학습 데이터가 없는 언어 간의 번역도 가능하다. 예를 들어 ‘나는 사과를 먹는다’라는 문장과 같은 뜻의 일본어 ‘와따시와 링고 오 타베루(私はリンゴを食べる)’를 각각 영어로 번역했다고 하자. 이때 한국어에서 일본어로 번역한 학습 데이터가 없어도 ‘나는 사과를 먹는다’를 입력하면 ‘와따시와 링고 오 타베루’로 번역할 수 있다. 이를 ‘제로샷 번역(Zero-shot Translation)’이라고 한다.
구글 연구진은 이런 학습법이 효과가 있었던 것은 인공지능만의 ‘중간 언어(Interlingua)’가 존재하기 때문이라고 추정했다. 구글의 논문에 따르면 제로샷 번역은 NMT에 모든 언어를 아우르는 중간 언어가 존재한다는 것을 보여준다. 사람은 알 수 없지만 NMT가 자체적으로 만든 중간 언어가 있어, 어떤 언어가 들어오든 이 중간 언어를 거쳐 다른 언어로 번역된다는 것이다.
단어를 쪼개 번역 품질 높여
인공신경망이라고 다 좋은 점만 있는 것은 아니다. 사용빈도가 낮은 단어는 잘 번역하지 못한다. 김리더는 “NMT는 사용 단어가 10만 개 이상이 되면 품질이 급격히 떨어진다”며 “학습 데이터의 단어 벡터가 10만 개 이상이 되면 그 중 사용 빈도수가 낮은 단어들은 따로 분류해 모두 동일한 벡터 값을 가지게 한다”고 말했다. 평소에 쓰지 않는 학술용어가 소리 나는 대로 번역되거나, 번역되지 않고 그 단어 그대로 나오는 경우가 이에 해당한다. 이런 단어가 많을수록 번역 품질은 낮아진다.
구글은 단어 벡터의 단위를 하나의 단어가 아닌 자주 쓰이는 알파벳의 조합(sub-word unit)으로 설정했다. 예를 들어 ‘teacher’이 하나의 단어 벡터가 아니고 ‘teach’와 ‘er’이 각각 단어 벡터가 된다. 김 리더는 “이렇게 벡터 단위를 줄여 번역 가능한 단어 조합의 수를 늘리는 것도 좋은 아이디어”라며 “파파고도 최적화된 단어 벡터의 단위를 계속 연구하고 있다”고 말했다.













