우리나라 게놈 연구가 급물살을 타고 있다. 바로 한국인의 유전자는 우리 손으로 찾겠다는 것이다. 국내 연구 사상 초유의 거대 프로젝트로 기록되고 있는 인간 유전체 기능 연구 사업단을 중심으로 한국 게놈연구의 현주소를 살펴보자.
지난해 2월 미국을 비롯해, 영국, 프랑스, 독일, 일본, 중국 등이 참여한 인간게놈프로젝트(HGP) 국제 공동컨소시엄이 인간 게놈의 99%에 해당하는 DNA 염기서열을 발표하자 국내 연구자들 사이에서는 탄식이 흘러나왔다. 선진국은 그렇다 하더라도 우리보다 한참 뒤졌다고 생각했던 중국이 극히 일부이기는 하지만 당당히 인간게놈 염기서열 해독의 주역으로 참여했기 때문이다. 농산물, 저가 공업제품을 이어 과학에서도 중국이 우리를 앞지를지 모른다는 우려도 제기됐다. 그로부터 1년 뒤 중국은 이때의 축적된 경험과 지식을 바탕으로 세계 최초로 벼의 게놈 지도를 독자적으로 발표하게 됐다. 우려가 현실로 나타난 것이다.

3만여종 한국인 유전자 발굴
그러나 늦었다고 생각할 때가 가장 빠른 법. 국내에서도 인간 게놈 연구의 바람이 거세게 불고 있다. 바로 한국인의 유전자를 우리 손으로 찾겠다는 것이다.
한국인 게놈 연구의 핵심은 1999년 발족한 과학기술부 21세기 프론티어사업단의 하나인 인간유전체기능연구사업단(이하 유전체사업단)이다. 10년 간 매년 1백억원씩 모두 1천억원이라는 연구비가 투입되는 국내 연구 사상 초유의 거대 프로젝트로, 한국인이 잘 걸리는 위암·간암 유발유전자와 단백질을 찾아내 암 진단과 신약개발까지 달성하겠다는 목표를 갖고 있다. 지난해부터 본격적인 연구가 시작됐으며 연구 2년째를 맞고 있는 현재, 서서히 결과물들이 나오고 있다.
유전체사업단은 2년 간의 연구를 통해 위암 세포주(끊임없는 분열에 의해 계속 증식만 하도록 만든 세포)에서 2만2천여종의 유전자, 간암 세포주에서 1만2천종의 유전자를 발굴해 총 3만93종의 유전자를 확보했다고 발표했다. 현재 위암관련 유전자 발굴은 삼성의료원, 현대아산중앙병원 등을 중심으로, 간암관련 유전자 발굴은 전북대 원자력병원을 중심으로 진행되고 있다.
지난해 HGP가 인간게놈지도를 발표하면서 인간의 유전자의 개수를 3만에서 4만개 사이로 밝힌 바 있다. 그렇다면 유전체사업단은 이미 인간의 유전자를 모두 밝힌 것일까. 간단히 말한다면 유전체사업단이 발굴한 유전자는 온전한 유전자가 아니라 유전자의 일부, 즉 조각들이다.
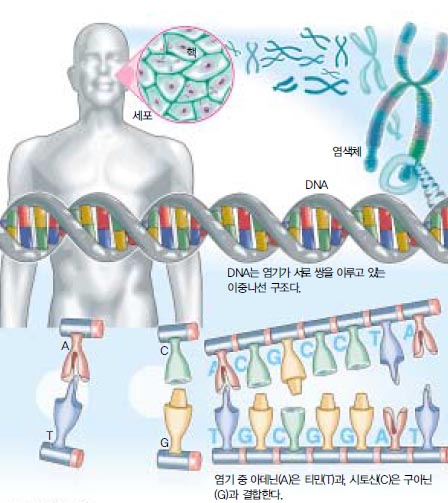
DNA는 아데닌(A), 구아닌(G), 시토신(C), 티민(T)이라는 4종류의 염기가 죽 늘어서 있는 형태다(그림 1). A는 T, G는 C하고만 결합하게 된다. DNA의 이중 나선은 이 염기들의 결합에 의해 유지된다. DNA 염기들은 3개씩 짝(코돈, codon)을 지어 단백질을 구성하는 성분인 아미노산 하나를 결정하게 된다. 유전자란 이렇게 단백질을 구성하는 아미노산들을 결정짓는 염기들이 있는 DNA 부분을 말한다. DNA의 유전정보는 핵 안에서 mRNA로 복제된 다음 다시 세포질의 리보솜에서 단백질을 합성하는데 이용된다. 그러므로 유전자를 찾을 때는 mRNA를 찾으면 된다.
그러나 RNA는 DNA와 달리 단일나선으로 불안정하며, 또한 수명이 짧기 때문에 실험실에서 다루기가 힘들다. 그래서 유전자 발굴에는 RNA를 인위적으로 이중나선의 DNA로 전환시킨다. 이것이 바로 cDNA(copy 또는 complementary DNA)다. RNA의 염기는 T가 U(우라실)로 바뀐 걸 제외하고는 DNA와 동일하다. 그러므로 예를 들어 DNA의 염기가 AGCT라면 염기의 상보적 결합에 의해 RNA로 복제될 때는 UCGA가 된다. RNA를 cDNA로 다시 전환시키면 다시 상보적 결합에 의해 원래 DNA의 염기서열과 같이 AGCT가 나타난다.
물론 cDNA 자체가 하나의 유전자를 의미하지는 않는다. RNA를 분리하고 cDNA로 전환하는 과정에서 RNA의 소실이 일어나기 때문에 대부분의 cDNA는 유전자의 조각이 된다. cDNA는 발현된 염기서열조각(EST, Expressed Sequence Tag)로도 불린다.
미 국립보건원 산하 국립생물정보센터(NCBI)의 유전자은행(GenBank)에서 운영하는 EST 데이터베이스(dbEST)에 등록된 EST의 수는 9월 27일 현재 1백개 이상의 생물종으로부터 온 1천2백87만6천4백35개이며 이 가운데 인간은 36%를 차지하는 4백71만4천3백63개이다.
그런데 유전체사업단이 밝힌 3만93종의 유전자란 고속염기서열작업을 거친 cDNA 즉, EST들 중에 동일한 염기서열을 포함하고 있는 것들을 묶음으로 분류한 ‘UniGene’이다. NCBI의 UniGene 데이터베이스에는 9월 10일 현재 인간의 3백73만9천1백55개의 EST를 10만4천2백14개의 UniGene으로 분류하고 있다. 유전체사업단이 찾아낸 UniGene 가운데 1천9백32개는 새로 밝혀진 것이다.
한국형 DNA칩 개발

유전체사업단이 확보한 UniGene 중에는 mRNA에서 복제될 때 조각나지 않은 cDNA인 전장 클론도 포함돼 있다. 지금까지 8천9백78종의 전장 클론을 확보한 상태인데, 1999년 시작된 미 국립암연구소의 포유류 유전자 데이터베이스(Mammalian Gene Collection) 사업이 10월 15일 현재 1만3천1백30종의 전장 클론을 확보한 상황임을 고려하면 괄목할 만한 성과다. 참고로 일본의 경우 도쿄대팀이 자체적으로 2만5천개 이상의 cDNA 전장 클론을 확보한 것으로 알려져 있다. 미국과 일본은 각자 수집한 cDNA 전장 클론에 대한 재해석 작업을 8월부터 시작해 12월 그 결과를 발표할 예정이다.
이렇게 찾아낸 유전자들이 질병과 어떤 연관성이 있는지를 알기 위해서는 cDNA 마이크로어레이(microarray), 유전자발현계열분석(SAGE), 발현차(DD, Differential Display) PCR 등과 같은 방법을 사용하게 된다. 그 가운데 가장 대표적인 방법은 cDNA 마이크로어레이, 즉 cDNA칩을 이용하는 방법이다.
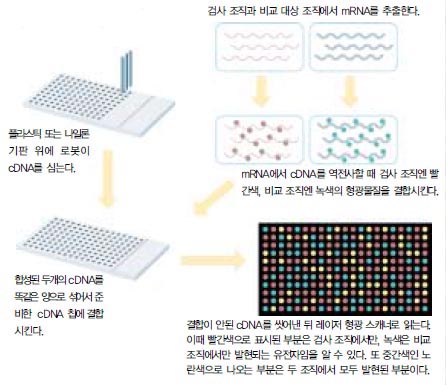
cDNA칩을 만들기 위해서는 우선 위암이나 간암 조직에서 mRNA를 분리한 다음, 이를 다시 역전사효소를 이용해 cDNA로 전환시킨다. 이렇게 만든 cDNA들을 유리나 나일론 기판 위에 심은 것이 cDNA칩이다. 한국형 cDNA칩도 이런 식으로 만들어졌다. 그 다음 환자나 정상인의 조직에서 mRNA를 추출한 다음 칩의 역전사효소로 cDNA로 전환시켜서 칩 위의 cDNA와 반응시킨다. 역전사과정에서 염기에 형광물질을 끼워 넣기 때문에 시료와 기판 위의 cDNA들이 상보적으로 결합하면 형광물질이 빛을 발한다. 이를 광학 스캐너로 읽어내면 아주 빠르게 환자의 유전자 발현현황을 분석할 수 있다(그림 2).
유전체사업단은 미국의 인사이트 지노믹스사에서 구매한 1만개의 EST가 심어져 있는 DNA칩과 함께 우선 위암관련 1만4천개의 UniGene을 담은 한국형 cDNA칩을 개발, 유전자 연구자들에게 제공했다. 이를 이용해 1차년도에 위암과 관련된 후보유전자 4백종, 간암에서 발현이 증가하거나 감소하는 유전자 2백70종을 발굴했다. 후보 유전자를 좀더 좁혀나가면 위암·간암 진단용 DNA칩을 제작할 수 있게 된다. 후보 유전자들의 기능 분석은 세포, 조직, 기관에서부터 효모, 선충, 초파리 등의 모델 생물을 이용해 이뤄진다.
한편 암 관련 유전자는 초기, 중기, 말기 등 진행상태에 따라 발현되는 정도가 차이 난다. 이제까지 위암 진행단계에 따라 변화되는 유전자 3백종과 환자의 나이와 상관관계가 높은 유전자 1백50종, 그리고 암 조직의 분화 정도에 따라 차이를 보이는 유전자 1백종 등 총 5백50종이 발견됐다. 간암의 경우에도 7백30여개 유전자로 간암의 진행단계를 구분할 수 있음이 밝혀졌다.
다양한 유전자 분석기술 동원
국내에서는 삼성과 벤처기업인 바이오니아에서 DNA칩 기술개발을 서두르고 있다. 삼성은 형광색을 분석하는 기존의 DNA칩과 달리 cDNA들 사이의 상보적 결합이 이뤄질 때 발생하는 전기화학적 신호를 분석해내는 새로운 개념의 DNA칩 판독장비를 개발중이다.
그런데 cDNA칩은 기판에 심기 위한 cDNA를 계속 증폭시켜야 하기 때문에 하루에 3백장 정도밖에 못 찍어낸다. 반면에 약 15-25개의 염기들로 이뤄진 올리고뉴클레오티드(oligonucleotide) 칩은 cDNA의 일부 염기를 인공적으로 합성해낸 것을 심기 때문에 대량 생산이 가능하다. 물론 올리고뉴클레오티드 칩으로 의미 있는 유전자 발현차를 발견했을 때는 다시 해당되는 cDNA를 다시 분석해야 된다. 국내에서는 생명공학 벤처기업인 바이오니아가 올리고뉴클레오티드 칩을 개발중이다.
한편 cDNA칩은 유전자의 발현을 정확하게 분석할 수 있고 염기서열까지 알아낸다는 장점이 있지만 고가의 분석 장비가 필요한 단점이 있다. 그래서 각 조직에서 유전자 발현 정도의 차이만을 알고자 할 때는 유전자발현계열분석(SAGE), 발현차(DD, Differential Display) PCR, 억제감산하이브리다이제이션(SSH) 등의 좀더 저렴하고 신속한 방법이 사용된다.
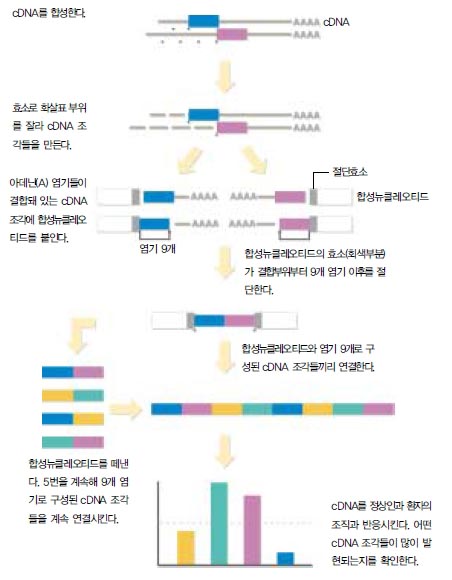
우선 SAGE는 칩에 평균 5백개 이상의 염기로 구성된 cDNA 대신 염기 9개 정도만 이용한다. 염기의 종류가 4종류이므로 9개의 염기로 가능한 조합은 ${4}^{9}$, 약 26만개가 된다. 이 정도면 거의 모든 유전자를 검사할 수 있다. 9개의 염기로 구성된 조각은 mRNA를 cDNA로 복제해낼 때 크기를 제한할 수 있는 효소 등을 함께 반응시켜 만들어낸다.
예를 들어 이렇게 만들어낸 조각 1백개를 다시 결합효소를 이용해 붙이면 cDNA 1백개를 붙여놓은 것과 같다. 그러나 전체 염기의 수는 9백개에 지나지 않으므로 염기서열분석이 훨씬 빨라진다. 이런 식으로 염기조각들의 염기서열을 비교해서 서로 다른 종류의 유전자에서 유래한 것들인지, 아니면 같은 유전자에서 유래한 것인지를 빠르게 알아낼 수 있다. 그리고 몇개 정도의 유전자가 발현되는지도 알아낼 수 있다. 나아가 정상 조직과 질병 조직을 같은 식으로 비교해 유전자, 정확히 말하면 유전자 조각의 발현율 차이도 알 수 있다.
DD-PCR은 SAGE와 마찬가지로 조직간 유전자 발현의 차이를 알아보는 것으로 각각의 유전자에 소수의 염기를 인위적으로 결합시킨 올리고뉴클레오티드 또는 DNA 조각들을 표지로 삼아 알아보는 방법이다.
SSH는 서로 다른 조직의 mRNA를 함께 반응시켜 조직간 유전자 발현 양상의 차이를 알아보는 방법이다. 예를 들어 뇌 조직의 mRNA를 간 조직보다 압도적으로 많이 넣으면 뇌 조직의 RNA는 거의 모두 이중나선으로 돼 있을 것이며 간 조직 가운데 뇌 조직과 유사한 RNA는 이중나선이지만 간 조직 고유의 RNA는 반응하지 않고 한가닥으로 남게 된다. 이런 식으로 간 조직 고유의 유전자를 찾아낼 수 있다.
몽골리안 게놈프로젝트, 한국인 SNP 지도 추진
한국인 게놈 연구는 유전체사업단 외에도 여러 곳에서 이뤄지고 있다. 그 가운데 언론의 집중조명을 받은 곳이 생명공학 벤처기업인 마크로젠(대표 서정선 서울대 의대 교수)이다.
지난해 6월 마크로젠은 한국인 고유의 게놈지도를 완성했다고 발표했다. 국제공동컨소시엄 HGP의 인간게놈지도 발표가 있은지 4개월만에 어떻게 국내 벤처기업이 한국인의 게놈지도를 완성할 수 있었을까.
정확하게 말하면 당시 마크로젠이 발표한 게놈지도는 전체 30억쌍의 염기 중 1억개를 판독한 것이다. 마크로젠은 20대 한국인 남성의 정자에서 추출한 게놈을 평균 11만개의 염기쌍으로 구성된 9만6천7백68개의 조각으로 잘라 박테리아 염색체에 삽입한 박테리아 인조염색체(BAC)를 만들었다.
이들 조각들의 양쪽에 있는 5백개의 염기를 해독해 HGP의 게놈지도와 비교하는 방식으로 이 인조염색체들이 게놈의 어디에 위치하는지를 알아냈다. 그러므로 약 10만개 게놈 조각의 양쪽 5백개씩, 모두 1천개를 해독했으므로 모두 1억개의 염기를 해독한 셈이다.
마크로젠은 한국인 BAC클론 지도를 토대로 한국인이 잘 걸리는 암과 고혈압, 당뇨병, 천식, 골다공증, 관절염, 면역질환 등 7대 질환에 대한 유전자 분석과 개인별 염기 차이(SNP) 데이터베이스 구축에 나서고 있다. 서정선 교수는 “현재 한국인 20명을 대상으로 1천5백개 유전자를 골라 SNP 분석을 실시하고 있으며 이 가운데 1백개 유전자의 SNP 분석은 이미 완결했다”고 밝혔다.
한편 마크로젠은 서울대 의대와 함께 우리나라와 몽골의 연구자들이 두나라 사람에게만 나타나는 독특한 질병 유전자를 찾는 이른바 몽골리안 게놈프로젝트도 시작했다. 서울대 의대는 올 3월 25일 몽골 국립의대와 함께 포괄적 학술연구 교류 협약식을 가졌다. 이 협약은 지난해 11월 서 교수가 소장으로 있는 서울대 의대 유전자이식연구소가 몽골 국립의대 의과학연구센터와 맺은 한·몽 유전체 연구협력사업 협약을 발전시킨 것이다. 마크로젠은 몽골인 1백명을 대상으로 우선 1만6천5백 염기쌍으로 구성된 미토콘드리아 유전자를 분석할 예정이다. 미토콘드리아 유전자는 모계로만 전달되기 때문에 인류의 기원, 즉 이브를 찾는 연구에 주로 이용됐다. 그러므로 몽골인과 한국인의 미토콘드리아 유전자를 분석하면 두 민족 간 차이와 기원에 대한 정보도 알 수 있게 된다.
이밖에 국립보건원 유전체연구소는 한국인에게 흔한 12개 질환별 연구센터를 중심으로 한국인에게 특이하게 나타나는 유전형을 찾기 위한 지도 작성에 나섰다(특집 2부 박스 기사 참고). 유전체연구소는 최고 10만명을 목표로 유전자 가운데 하나의 염기가 달라진 SNP들의 집합체를 분석할 계획이다. 특히 분석 결과를 각 연구센터가 확보한 임상기록과 대조하면 유전형이 환경요인과 어떤 상관관계가 있는지도 알아낼 수 있게 된다. 앞으로 유전체사업단과 유전체연구소의 연구결과가 서로 교류되면 한국인 게놈연구가 한단계 도약할 것으로 보인다.
게놈연구에 필수적인 것이 생명정보학을 이용한 게놈 데이터베이스와 가공기술이다. 최근 우리 고유의 유전체 데이터베이스도 구축되고 있어 한국인 게놈연구에 큰 도움이 될 것으로 보인다. 과학기술부 지정 국가유전체정보센터(www.ncgi.re.kr)는 10월말 출범 1주년을 맞이하면서 본격적인 생명정보학 서비스를 준비하고 있다. 유전체정보센터는 현재 인간유전체기능연구사업단, 자생식물이용개발사업단, 유용미생물유전체활용기술개발사업단 등 프런티어사업단들에서 생성된 유전정보에 대한 데이터베이스와 가공 서비스를 제공하고 있다.
유전체정보센터는 현재 미 NCBI가 보유한 인간을 비롯한 여러 생물의 총 1천2백만여건의 유전정보를 재가공해, 이 가운데 2백만-3백만건을 국내 연구자들에게 제공할 수 있는 단계에 와있다. 센터는 또 게놈 연구에 필요한 생명정보학 인력을 양성하기 위한 프로그램도 운영할 계획이다.











