로터스는 스프레드시트 뿐아니라 그래픽 데이터베이스 워드프로세서 기능까지 갖춘 통합소프트웨어다.
로터스 1-2-3의 본연의 기능은 복잡한 숫자 계산을 쉽게 해주는 것이지만 그런대로 쓸만한 데이터베이스 기능도 제공한다. 이를 이용하면 수작업으로는 도저히 엄두가 나지 않던 자료관리를 할 수 있다. 자료의 수가 제한되는 것이 단점이지만 개인 업무의 자료관리로는 손색이 없다.
로터스 1-2-3은 스프레드시트(spreadsheet) 스프트웨어로 분류되지만 한편으로는 통합소프트웨어(integrated software)로 불리기도 한다. 그것은 로터스가 스프레드시트의 기능에다가 지난호에서 설명한 그래픽 기능, 이번호에서 설명할 데이터베이스 기능, 그리고 워드프로세서 기능 등 4가지 기능을 갖추고 있기 때문이다. 일반적으로 통합 소프트웨어는 여기에 통신 기능을 추가한 5대 기능을 제공한다.
한때는 여러가지 기능을 합쳐 놓은 통합소프트웨어란 것이 소프트웨어의 궁극적인 방향이라고 생각하던 시절이 있었다. 그러나 현재 우리가 사용하고 있는 개인용 컴퓨터의 하드웨어적인 여건이 커다란 소프트웨어를 수용할 수 있는 형편이 못되기 때문에 통합 소프트웨어의 모든 기능이 충실해 질 수 없었고, 이로 인해 차라리 한 기능이라도 뛰어난 소프트웨어를 사용하는 방향으로 기울어지게 되었던 것이다. 로터스는 주 기능인 스프레드시트의 기능을 충실히 하면서 몇가지 부가적인 기능들을 간단하게 갖추는 중용을 택하고 있다.
로터스가 제공하는 데이터베이스(database) 기능은 특성상 몇개로 나누어 생각할 수 있다. 가장 많이 사용하는 기능은 많은 데이터를 원하는 순서대로 정렬(sort)하는 것과 많은 데이터중에서 원하는 내용을 검색(query)하는 것이다. 이밖에도 일정한 간격으로 일련번호를 생성하는 기능과 변수의 값에 따라 달라지는 공식의 결과값을 표로 만드는 기능이 쓸 만하다. 그리고 일반인들은 쓸 일이 별로 없지만 특수 용도를 위해 회귀분석표를 만드는 기능, 행렬을 계산하는 기능 등이 있다. 이중에서 정렬기능에 대해서 살펴보기로 하자.
로터스에서 데이터베이스를
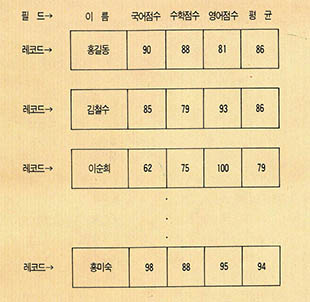
데이터베이스란 같은 구조를 가진 데이터들의 모임이다. 이 데이터베이스를 구성하는 단위 데이터를 레코드(record)라고 부른다. 한 데이터베이스에서 이들 레코드는 모두 같은 구조를 가지며, 레코드를 구성하는 단위 데이터를 필드(field)라고 한다. 이와 같은 데이터베이스의 예가 (그림 1)에 있다. 이것은 가상적인 성적 데이터베이스의 구조를 보인 것이다.
물론 로터스에서는 워크시트상에 데이터베이스가 존재한다. 그렇다면 우선 워크시트에 (그림 1)과 같은 데이터베이스를 구축하는 작업부터 살펴보기로 하자.
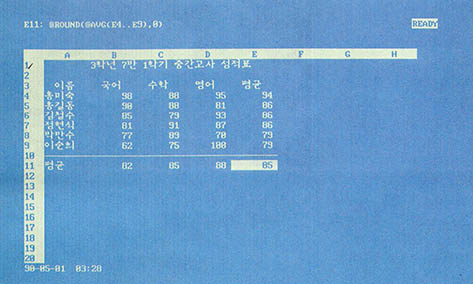
(그림 2)가 (그림 1)의 성적표를 로터스가 데이터베이스로 처리할 수 있는 형태로 입력한 화면이다. 이 화면처럼 워크시트를 만드려면 다음과 같은 과정을 거치면 된다.
우선 B1셀에 데이터베이스의 제목을 입력한다. 다음 3행에 레코드를 구성할 필드의 이름을 입력한다. A3에서 E3셀까지 이름 국어 수학 영어 평균을 입력하되 먼저 ^키를 눌러 필드의 이름이 셀의 중앙에 표시되도록 만든다. 이제는 데이터베이스를 구성하는 레코드데이터들을 4행부터 입력한다. 레코드는 필요한 만큼 입력할 수 있다(사실은 제한이 있다. 행의 최대번호인 8192를 넘길 수 없고, 그 전에 메모리가 부족하게 될 것이다). 단 필드의 이름이 기록되어 있는 행의 바로 밑에 붙여서 레코드들을 입력해야 한다.
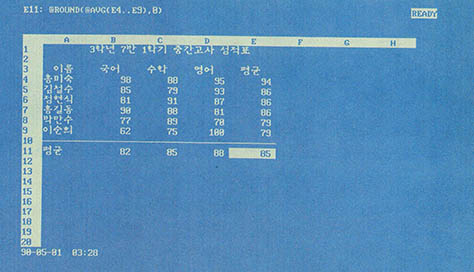
레코드중에서 평균은 공식을 사용하는 것이 당연하다. 커서를 E4 셀에 위치시킨 다음 공식 @ ROUND(@ AVG(B4..D4),0)를 입력한다. 이 공식에는 두 개의 함수가 사용되었다. @ AVG 함수는 지정된 영역에 있는 숫자들의 평균을 구해주며, @ ROUND 함수는 주어진 숫자를 지정한 소숫점 자리에서 반올림한 값을 구해준다. 따라서 입력한 공식은 홍길동 학생의 평균 점수를 소숫점 첫째자리에서 반올림한 값을 구해준다. 만일 소숫점 둘째자리에서 반올림 하고 싶다면 @ ROUND(@ AVG(B4..D4),1)를 입력한다. 일단 공식을 입력했으면 그 밑에는 복사를 하면 간편하다.
10행에는 구분을 하기 위해 선을 그려준다. A10 셀에\-을 입력한 다음 이것을 B10..E10 영역에 복사하면 된다. 다음은 11행에 각 과목의 평균을 구하는 공식을 입력한다. B11 셀에서 @ ROUND(@ AVG(B4..B9),0)를 입력한 뒤 이것은 C11..E11 영역에 복사하면 완성된다.
(그림 2)와 같은 데이터베이스를 실제로 구축할 때는 보다 많은 레코드들을 입력하게 된다. 레코드를 더 입력할 공간을 만들려면 커서를 9행에 위치시키고 /W(orksheet) I(nsert) R(ow)키를 차례대로 누른 다음 새로 입력할 레코드의 수만큼 빈 행을 삽입해주면 된다. 필요없는 레코드가 생긴다면 그 행으로 커서를 옮긴 다음 /W(orksheet) D(elete) R(ow) 키를 누르고 삭제할 레코드의 수만큼 행을 지운다.

순서대로 정렬한다
모든 데이터베이스는 단순히 레코드만을 나열하면 되는 것이 아니라 특정한 순서대로 정렬되어야 의미가 있다. (그림 2)의 경우 각 레코드는 학생들의 성적을 보관하고 있는데, 특정 학생의 성적을 찾기 편하게 하기 위해서는 학생들의 이름순으로 정렬되어야 한다. 또는 석차를 구하려면 평균의 순서대로 정렬되어야 한다. 이 데이터베이스가 종이 위에 구축되어 있다면 사람이 일일이 정렬 작업을 해야하지만 로터스의 워크시트에 구축된 데이터베이스에서는 몇개의 키만 눌러주면 간단히 처리된다.
우선 (그림 2)의 성적표를 학생들의 이름순으로 정렬시켜 보자. /키를 눌러 주 메뉴를 부른 다음 D(ata) 키를 눌러 데이터베이스 메뉴를 불러낸다. 데이터베이스를 정렬하려는 것이므로 S(ort)키를 누른다. 이때 화면 상단에는 Data- Range, Primary-Key, Secondary-Key, Reset, Go, Quit의 6개 메뉴가 나타난다.
Data-Range는 데이터베이스가 저장되어 있는 영역을 지정하는 기능이다. 데이터베이스에 관련된 작업을 하려면 먼저 이 기능을 선택하여 데이터베이스 영역을 확실하게 지정해 주어야 한다. (그림 2)의 경우에는 필드의 이름이 있는 행의 밑에서부터 마지막 레코드까지 A4..E9 영역을 지정하면 된다.
데이터베이스를 정렬하려면 정렬의 기준이 되는 필드를 결정해 주어야 한다. 이런 필드를 키 필드(key field)라고 한다. 로터스는 정렬의 기준이 되는 키필드를 두개까지만 지정할 수 있도록 허용해준다. 두개의 키 필드중 우선권이 있는 것을 Primary-Key라고 하고 이 필드의 내용이 동일한 경우 참조하는 필드를 Secondary-Key라고 한다.
(그림 2)의 데이터베이스를 학생들의 이름순으로 정렬하려면 Primary-Key만 A열로 지정하면 된다. Primary-Key를 선택한 다음 커서를 A열로 옮긴 다음 엔터 키를 누르면 이번에는 다음과 같은 메시지가 나타난다.
Sort order(A or D)
이것은 지정된 키 필드로 정렬을 하되 올림차순(Ascending order)과 내림차순(Descending order) 중 어느 방식을 선택할 것인지 결정하라는 뜻이다. 올림차순은 키 필드의 값이 작은 레코드가 앞에 놓이게 정렬하는 것이고(작은 수에서 큰 수, ㄱ에서 ㅎ, A에서 Z), 내림차순은 그 반대다. 이름순으로 배열하기 위해서는 A키를 눌러 올림차순을 선택한다.
데이터베이스의 영역과 키 필드를 지정한 뒤에는 Go를 선택하면 원하는 정렬이 순식간에 일어난다. 반면에 Reset을 선택하면 앞에서 지정한 사항들이 모두 취소된다.
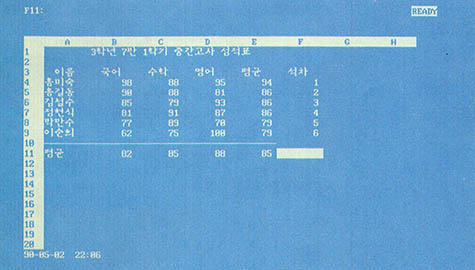
이번에는 (그림 2)의 성적 데이터베이스를 정렬하여 석차를 구해보자. 데이터베이스 영역에는 변함이 없고, Primary-Key만 E열로 재지정하면 된다. 단 석차를 구하는 것이므로 내림차순 방식을 이용해야 한다. 다음에는 역시 Go를 선택하여 정렬의 결과를 확인한다. 그 결과는 (그림 3)과 같다. 평균이 제일 높은 학생이 앞으로, 평균이 낮은 학생은 뒤로 이동하는 것을 볼 수 있다.
그런데 (그림 3)을 자세히 보면 평균이 같은 경우가 있는 것을 볼 수 있다. 이런 경우 석차를 동일하게 매기기도 하지만 특정과목의 점수로 석차를 가르기도 한다. 평균이 같은 경우 국어 성적으로 석차를 구한다고 생각해보자. 어떻게 하면 좋을까. Secondary- Key를 이용하면 된다., 이것을 B열로 지정한 뒤 Go를 다시 선택해보자. 제대로 되었다면(그림 4)와 같은 화면을 볼 수 있을 것이다. 이번에는 평균이 같은 경우 국어 성적에 의해 순서가 결정되어 있음을 알 수 있다.
석차를 매겨보자
(그림 4)까지 성적 데이터베이스를 정렬하여 석차순으로 배열하는 작업을 해보았다. 이 워크시트에 석차 번호를 넣으면 프린터로 출력할 수 있는 완성품이 만들어진다. 석차 번호는 직접 입력해도 되지만 학생의 수가 많아지면 상당히 귀찮은 작업이다.
석차 번호의 입력은 /Data Fill 기능으로 간단하게 처리가 된다. 이 기능은 일련번호를 입력할 영역, 시작 번호, 증가치, 끝 번호를 지정해주면 해당 영역의 첫번째 셀에 시작 번호를 넣고 그 다음 셀에 증가치만큼 더한 값을 넣고… 이런 식으로 지정된 영역의 모든 셀들을 채워준다. 증가치에 음수를 넣어주면 감소하는 일련의 숫자도 발생시킬 수 있다. 일반적으로 지정한 영역의 모든 셀에 숫자를 채우려고 한다면 끝 번호는 입력하지 않아도 된다.
Fill Range로 F4..F9, Start로 1, Step으로 1, Stop으로는 그냥 엔터 키를 입력하면(그림 5)와 같은 결과를 화면에서 볼 수 있다.
로터스가 제공하는 다른 데이터베이스 기능들도 있지만 가장 중요한 것은 데이터베이스를 워크시트에 입력하는 방법과 이를 원하는 순서대로 정렬해 보는 것이다. 다른 기능들도 그렇게 어렵지 않으니 관심 있는 독자는 한번 시도해보기 바란다.
그런데 우리가 예제로 다룬 성적 데이터베이스에서 평균과 국어 성적이 모두 같은 레코드가 있다면 어떻게 해야 할까. 이런 상황은 로터스가 기본적으로 제공하는 기능으로는 처리할 수 가 없다. 로터스는 이런 경우를 대비하여 매크로(macro)라고 하는 간이 프로그래밍 언어를 갖추고 있다. 이를 이용하면 매우 재미있는 여러가지 일들을 할 수 있는데, 이에 대해서는 다음호에서 다루어 본다.