지난 87년 많은 논란 끝에 제정된 2바이트 완성형 표준한글코드. 한글의 풍부함과 과학성을 오히려 저해하고 있다는 거센비판과 함께 표현 불가능한 글자마저 있다는데…
재영이가 컴퓨터 한글워드프로세서로 생각나는 데로 시를 쓰고 있다. '시냇물이 뾰ㄹ뾰ㄹ 흐르는데, 돌을 표º하고 던졌다.' 재영이는 속으로 '어!이상하네'라고 하면서, 무엇인가 컴퓨터에 고장이라도 생겼나 하고 생각한다. 재영이는 국민학생인데 어릴적부터 워드프로세서로 일기도 쓰고 작문도 하던 참이다. 아예 오래 전부터 어른들이 써왔던 타자기는 써본 적도 없고 종이에 연필로 쓰는 것보다는 컴퓨터쪽이 훨씬 편하다고 생각한다. 원래 재영이가 생각하던 싯구는 이러하다.
'시냇물이 뾸뾸 흐르는데, 돌을 푱하고 던졌다.'
뾸'을 치려는데 자꾸면 '뾰ㄹ'이라고 표시되고 '푱'을 치려는데 '표o'이라고 컴퓨터 화면에 나온다. 물론 시각적으로는 '뾰ㄹ'이나 '표ㅇ'이 '뾸'이나'푱'보다 그 느낌을 더해줄지는 모르지만 재영이의 생각은 그렇지 않다. 세종대왕께서는 인간이 발음할 수 있는 모든 말을 글자로 표현할 수 있도록 만드셨다고 하느데 왜 컴퓨터에서는 그것이 가능하지 않을까? 인간보다 더 나은 일을 할 수 있다고도 하는 컴퓨터가 그 글자하나 제대로 쓰지를 못할까? 재영이는 이렇게 생각을 하게 된다.
5천6백여자는 어디로?
그 이유는 알고 보면 지극히 간단하다. 컴퓨터가 알고 있는 한글의 글자수에는 한계가 있기 때문이다. 한글의 자소(字素)의 수는 자음 14자, 모음 10자, 합하여 24자로 이루어진다. 이 24자를 조합하여 발음할 수 있는 글자는 8천자를 넘는다. 그런데 컴퓨터가 알고 있는 한글 글자의 수는 2천3백50자에 불과하다. 왜 이렇게 밖에 될 수 없는가? 그 2천3백50자는 어떻게 뽑혀진 글자들인가? 나머지 5천6백여자는 어디로 갔는가? 왜 한국인이 발음할 수 있는 글자를 컴퓨터는 몰라야만 하는가? 몰라도 되는가? 교육용 컴퓨터를 국민학교에까지 보급하여 남녀노소를 막론하고 일상생활의 일부분으로서 컴퓨터를 쓰게 한다는데 이래도 되는 것인가? 신문사에서도 신문의 조판을 컴퓨터로 한다는데, 이렇게 글자수가 부족하면 컴퓨터가 모른다고 하는 글자는 어떻게 해야 하는가 하는 글자는 어떻게 해야 하는가 등등의 질문이 꼬리를 문다.
아스키(ASCⅡ)코드
컴퓨터는 글자를 어떻게 기억할까? 우리가 글을 쓸 때 원고지에 쓰듯이 컴퓨터도 정해진 규격대로 글자를 기억하고 쓴다. 글자의 기본 단위는 1바이트(byte)로부터 0부터 255까지의 숫자를 표현한다. 좀더 자세히 설명하자면 2진법 8자리로 이루어진다. 즉 2진법으로 '00000000'에서 '11111111'까지이므로 0에서 255까지가 된다. 컴퓨터는 원래 숫자 이외에는 아는 것이 없으므로, 글자도 이 숫자를 이용할 수 밖에 없다. 즉 각 글자에 일련번호를 붙여 표현한다. 영어의 예를 들면, 대문자 소문자 숫자 기호를 다 합하여 1백자 미만에 불과하므로 한개의 바이트로 모든 가능한 글자를 표현할 수 있다. 이러한 일련의 번호를 글자코드라고 부른다.
또 영어의 위와 같은 글자코드 체계를 '아스키(ASCⅡ)'라는 표준으로 정하여 모든 컴퓨터 회사가 이를 따르도록 하였다. 실제 ASCⅡ는 0부터 127까지의 숫자만을 사용하고 나머지는 다른 목적에 쓰고 있다. 위에서 언급한 1백자 정도의 글자 외에도 컴퓨터 제어문자라는 특수목적 코드를 합하여 1백28개를 완전히 쓰고 있다.
왜 없는 글자가 생기는가
한글 자소 24자를 ASCⅡ라는 체계에 넣는다는 것은 알파벳 등이 모두 차 있으므로 정상적인 방법으로는 불가능하다. 따라서 편법으로 한글 자소가 시작하는 곳과 끝나는 곳에 특수 제어문자를 넣어서 컴퓨터로 하여금 한글의 시작과 끝을 원래의 ASCⅡ체계의 글자코드와 구별하도록 할 수 밖에 없다. 이 방법이 보편적으로 쓰여왔던 한글의 컴퓨터 내부 표현방법이다. 이 방법을 'n바이트형'이라고 부른다. 그 이유는 한개의 글자를 표현하는 자소의 수가 2개에서 6개로서 일치하지 않으므로 n개라 한 것이다. 또한 자소가 한 바이트로 표현되므로 'n바이트'라는 이름을 붙였다.
여기서 문제가 되는 것은 실제로 한글의 글자는 여러 자소가 조합하여 한 개의 글자를 이룬다는 것이다. 컴퓨터 화면에서 보는 글자도 그러하거니와 인쇄된 것도 조합된 글자이지 낱개의 자소가 아니다. 그러나 컴퓨터 내부에서는 낱개의 한글 자소와 한글의 시작과 끝을 알려주는 제어문자가 기억되어 있을 뿐이다. 따라서 컴퓨터는 한글 자소를 조합하여 그 조합된 글자를 보여주어야 한다.
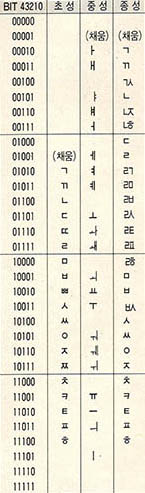
'n 바이트형'의 문제점은 한글을 기억하는데 너무 많은 자리를 차지한다는 것이다. 사람에 비유한다면 같은 글을 쓰는데도 듬성듬성 써서 종이를 많이 소비하는 것과 같다. 실제 한글의 자소를 보면 자음은 14개이고, 모음은 10자이며, 한 개의 조합글자는 초성 중성 종성으로 이루어져 있다. 초성은 자음, 중성은 모음, 종성은 자음 또는 복자음이 오거나 없을 수도 있다.
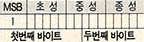
각 초성 중성 종성은 아무리 수가 많다 하더라도 30개 미만이므로 2진법으로 5자리인 11111으로 충분히 각각의 초성 중성 종성을 표현할 수 있다. 따라서 한개의 글자를 표현하기 위해서는 15자리의 2진법 숫자가 필요하다. 1바이트는 2진법 8자리이므로, 2바이트이면 16자리가 되어 15자리만 필요로 하는 한글 글자를 충분히 표현할 수 있다. 'n 바이트형'으로는 최소 2개에서 최대 6개까지의 바이트를 필요로 하던것이 위의 방법을 쓰면 2개의 바이트만 쓰면 되므로 기억용량도 크게 줄어든다. 2바이트의 16자리중 15자리만 쓰고 나머지 한 자리는 한글에 관한 코드인지 ASCⅡ인지를 식별하는 표시 역할을 할 수 있다.
그러나 이 방법만으로는 완벽하게 한글 글자와 ASCⅡ를 식별하는 데는 어려움이 따른다. 현재 보고 있는 바이트가 알파벳인지 한글 글자인지를 위해서 언급한 나머지 한 자리를 이용하여 구별한다고 하였으나, 한글 글자의 2바이트 중, 그 식별을 위한 자리는 어느 한 바이트에 자리잡고 있을 터이므로, 나머지 한 바이트만을 보고서는 식별이 되지 않고 그 앞뒤를 보아야 할 필요가 있다. 그러나 그러한 어려움은 충분히 극복할 수 있다. 이러한 코드체계를 2바이트 안에 조합을 위한 초성 중성 종성이 구별되어 자리잡고 있다고 하여 '2바이트 조합형'코드라고 부른다. 이 코드체계의 문제점은 통신용 국제규격에 맞지 않는다는 점이다. 이와 같은 배경하에 표준한글코드는 다음과 같은 코드체계를 따르게 된다.
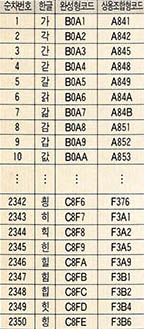
우선 조합된 한글 글자의 빈도조사를 하여 빈도가 높은 2천3백50여자를 선택하여, 각각의 조합된 글자에 일련번호를 붙인다. 이 방법은 한자에 코드를 부여할 때 쓰는 방법이다. 물론 이 일련번호는 그 일련번호만 보고서는 그 한글 글자가 어느 자소로 만들어졌는지를 알 수가 없다. 이 코드 체계의 이름을 조합하여 완성된 글자에 일련번호를 붙였다 하여 '2바이트 완성형'이라고 부른다. 이 코드체계의 문제접은 '푱'과 같은 글자는 없으므로, 꼭 그 글자를 쓰고자 할 경우에는 쓰고자 하는 사람이 스스로 그 글자 모양을 만들어 그 '푱'에 대한 일련의 번호를 표준으로 정해진 일련번호 다음의 어딘가에 붙여야 한다. 만일 그렇게 만들어진 글을 디스켓으로 담아 다른 컴퓨터에서 쓸 경우 다른 글자로 해석될 수 밖에 없다.
3바이트를 채택해서라도
'2바이트 완성형 ' 한글코드가 지난 87년 KS표준코드로 제정된 이유로는 국제표준통신코드 규격에 적합하여 ASCⅡ와의 식별이 간단하다는 극히 기계적인 측면만이 강조되어 있다. 또 빈도조사에 따라 현대인이 쓰는 모든 글자를 포함한다고 하였으나 그것은 공문서를 쓸 때도 그 용도를 제한한 것이지 모든 용도에 맞는다는 것은 아니다. 과연 빈도가 높다는 것은 무엇인가? 일반적인 현대문에서 빈도조사를 하여 빈도가 높은 순서대로 일련번호를 붙여 2천3백50자만을 끊어 쓰고 나머지 남은 공간은 한자를 위하여 부여했다고 하지만 빈도는 공공성도 있는 반면 개인적인 것이기도 하다. 재영이는 시를 쓸 때에 '푱'이라는 글자를 자주 썼지만, 어느 회사의 이름이 '푱푱'이 될 수도 있다. 모든 발음을 표현할 수 있도록 만들어진 한글이 극복할 수 있는 컴퓨터의 제약점 때문에 앞으로 한국인의 발음이 제한당할 수 밖에 없다는 사실은 다시 생각하지 않으면 안된다. 물론 표준화된 한글 코드가 없던 때보다는 현재가 훨씬 나은 상태이다. 어느 컴퓨터끼리도 통신으로 서로의 데이터를 주고 받을 수가 있기 때문이다. 그러나 영원한 문화창달을 위한 밑바탕으로서의 글자인 한글을 생각할 때 컴퓨터가 한글문화의 풍부함을 제한해서는 안된다. 2바이트에서 문제가 있다면 3바이트를 써서라도 한글의 품위를 손상하지 않도록 다시 표준을 정해야 할 것이다.