지금까지 우리가 다루었던 문제들은 각각의 자료를 개별적으로 처리하고 자료가 이미 저장되어 있는 기억장치 방(memohy cells)을 재사용하는 것이었기 때문에 소량의 기억장치 방을 사용하여 많은 양의 자료를 처리할 수가 있었다. 그러나 많은 응용프로그램에서는 기억장치에 다량의 자료를 저장하고 그것을 처리해야 하는 것이 보통이다.
이 장에서는 서로 관련성 있는 다량의 자료 집합을 저장하며 이것들을 원하는 형태로 처리할 때에 사용하는 배열(array)에 대해서 공부하기로 한다. 배열은 매우 중요한 프로그래밍기법으로서 이것의 처리방법을 익힌다면 프로그래밍 기술의 반을 터득했다고 해도 과언은 아니가.
배열(array)의 선언
배열은 두 개 이상의 서로 이웃하는 기억장치 방들(memory cells)의 모음이다. 또 각각의 기억장치 방은 배열의 원소(array elements)라고 부른다. 프로그램에서 배열을 사용하려면 먼저 배열 선언문으로써 배열명과 배열원소의 수를 정의해야 한다. 즉 선언문 DIM X(8)은 이름이 X이고 원소가 8개인 배열을 생성시키는데 이것을 그림으로 나타내면 아래와 같이 된다.

X(1)는 첫째 원소(값16), X(8)은 여덟번째 원소(값-54.6)등 ()안의 숫자는 배열내의 몇째 원소인가를 나타내는데 이것을 배열의 첨자(array subscript)라고 한다.
(보기1)
X를 (그림1)의 배열이라고 하면
S=12.5+×(4)의 결과는
S=12.5+(-2.5)=10이 된다.

(보기2) DIM C(5), F$(20)
이 선언문은 C(1)C(2)…C(5)의 5개 원소로 구성된 배열C와, F$(20)의 20개 원소로 구성된 문자열의 배열F$을 생성한다.

그럼 배열선언문에 의해서 배열이 생성되었을 때 각 원소의 맨 처음 값은 무엇일까?
배열이 생성될때는 각 원소에 자동적으로 0이 할당되거나(숫자배열인 경우), 공란(문자열 배열인 경우)이 할당된다. 그러나 READ문, 또는 INPUT문을 사용하여 0이나 원하는 값을 지정하여 초기화(initialize)를 분명히 하는 것이 좋은 방법이다.
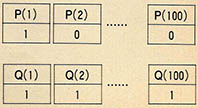
(보기3) 배열의 초기화
10 DIM P(100),Q(100)
20 FOR I=1 TO 100
30 P(1)=0
40 Q(1)=1
50 NEXT I
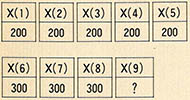
10 DIM X(9)
20 FOR I=1 TO 5
30 X(1)=200
40 NEXT I
50 FOR J=6 TO 8
60 X(J)=300
70 NEXT J
배열의 처리
G를 아래에 보인 것과 같이 10개의 원소로 구성된 배열이라고 하자.
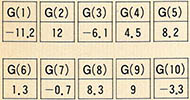
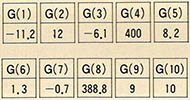
다음의 BASIC 명령문은 G의 10, 4, 8번째 원소의 값을 변경시켜서(표1 참조) 새로운 배열을 구성한다. 문번호 50에서는 세개의 원소를 사용하고 있는데 G(1), 즉 G(4)에 새로 할당된 값이 G(J), 즉 G(1)에 더해진 후 결과가 G(2*1), 즉 G(8)에 저장된다.
10 J=1
20 I=4
30 G(10)=10
40 G(I)=400
50 G(2*1)=G(I)+G(J)
(표 1) 배열 G의 처리

배열 G는 이 BASIC 명령문에 의해서 처리된 후에 다음과 같이 변경된다.
(문제 1)
5명의 친구이름과 생년월일을 차례로 읽어서 다시 인쇄하는 프로그램을 작성해 보자.
(설명)
이름과 생년월일(1965.4.6 등)을 기억시키기 위해서는 먼저2개의 문자배열을 선언한 후에 5쌍(이름과 생년월일)의 자료를 입력시키고 입력된 자료를 다시 순서대로 인쇄한다.
(그림 2) 문제1의 프로그램과 결과
110 DIM N$(5), D$(5)
120 FOR I=1 TO 5
130 READ N$(I), D$(I)
140 NEXT I
150 DATA "박기영", "1965.6.7",
"김영숙", "1966.10.6"
155 DATA "민숙희", "1966.5.4",
"정애숙", "1965.12.10"
160 DATA "정순철", "1965.11.19"
170 PRINT "성명", "생년월일"
180 FOR I=1 TO 5
190 PRINT N$(I); TAB(23) D$(I)
200 NEXTI
210 END
RUN
성 명 생년월일
박기영 1965.6.7
김영숙 1966.10.6
민숙희 1966.5.4
정애숙 1965.12.10
정순철 1965.11.19
배열을 사용하여 프로그래밍할 때 가장 잘 발생하는 오류(error)는 배열명을 미리 선언하지 않는 것과 첨자의 범위를 벗어나는 것이다.
(그림2)의 프로그램에서는 문번호 110에서 배열명과 첨자의 범위를 선언하였고 문번호 120과 180에서 첨자의 범위를 벗어나지 않았음을 알 수 있다. 이러한 점에 유의하면서 (문제2)를 읽고 프로그래밍 해 보라.
(문제2)
다음 표는 5년 동안 자라난 영철이의 키의 변화량이다. 표를 보고 4년간의 키의 신장률을 구하는 프로그램을 배열(array)을 이용하여 작성해 보자.
(그림 3)문제2의 프로그램 결과

이제 배열의 처리방법에 자신이 생겼으면 다음의 (문제3)을 해결해보라. 아직 자신이 없더라도 설명을 잘 읽고 사용방법을 익히기 바란다. 이 문제는 배열의 사용 뿐 아니라 지금까지 배운 프로그래밍 기법을 종합적으로 포함하고 있는 좋은 예이다.
(문제3)
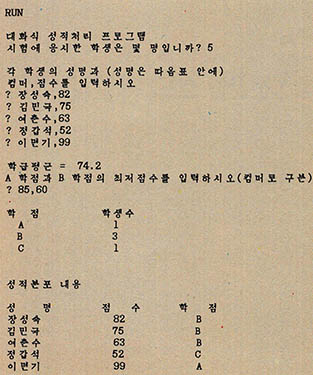
성적처리 프로그램
청운대학의 박교수님은 학생들의 영어시험 성적을 아래 조건에 맞게 컴퓨터로 처리해서 통계자료를 얻고자 한다.
(1) 먼저 학급의 학생수를 입력한다(100명 이하)
(2) 각 학생의 성명과 점수를 차례로 입력한다.
(3) 학급의 평균을 출력한다.
(4) 학급평균을 참고로 하여 A,B학점에 대한 최저점수를 각각 입력한다.
(5) A,B,C 각 학점별 학생수를 출력한다.
(6) 학생의 성명 점수 학점을 차례로 출력한다.
(7) (1)~(6)은 컴퓨터와 사용자가 대화식으로 처리할 수 있어야 한다.
(설명)
C는 학생수를 나타내며 각 학생의 성명과 점수는 배열N$와 S의 원소에 각각 저장된다. A는 학급의 평균이며 L1은 A학점의 최저점수, L2는 B학점의 최저점수이다.
L1과 L2를 알면 각 학생의 학점을 구하여 배열G$에 저장할 수가 있다.
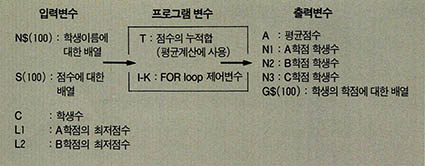
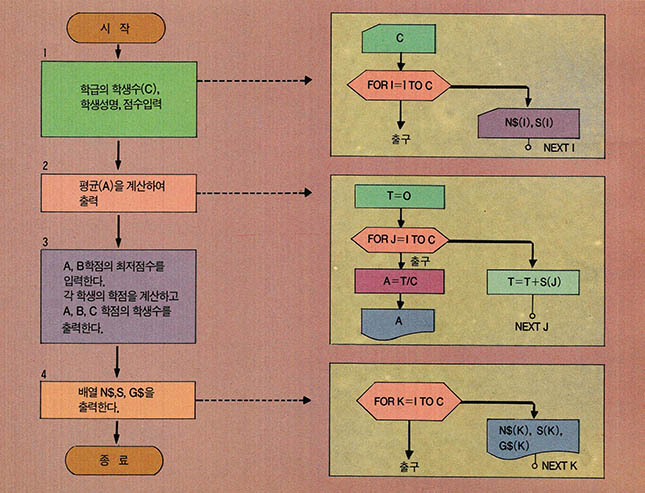
흐름도의 단계1에서는 각 학생에 대한 한쌍의 자료(학생성명, 점수)를 N$,S의 대응하는 원소에 저장하기 위해서 FOR loop문을 쓰고 있다. 단계4에서는 배열N$, S, G$ 원소 내용을 출력하기 위해 다시 FOR loop문을 사용했다. 단계2에서는 점수를 누적시킨 합을 구하기 위해서 T를 사용하고 (T=S(1)+S(2)+…+S(C)), T를 C로 나누어서 평균 A를 구한다.
단계3에서는 학점의 최저점수를 정해주고 (3.1) 학점과 A,B,C별 학생수를 계산한다(3.2). 이때 학점과 N1, N2, N3을 계산하기 위해서는 프로그램변수가 하나 더 필요한데 (그림4)에서 보는 바와 같이 P를 사용하였다. 단계4에서는 학생의 성명, 점수, 학점을 차례로 출력 해 준다.

(그림 4) 문제3의 흐름도
(그림 5) 단계3을 구체화 한 것
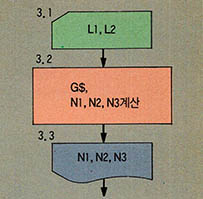
(그림 6) 단계3.2를 구체화 한 것
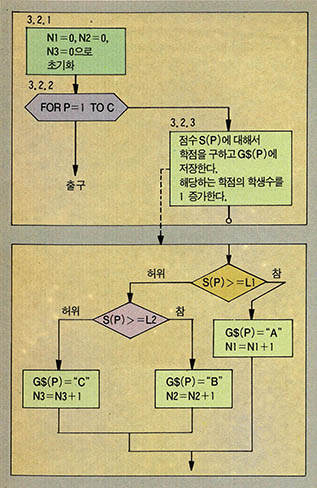
(그림 7) 문제3의 주(main)프로그램

(그림 8) 1차 서브루틴

(그림 9) 2차 서브루틴

(그림 10) 결과