LISP와 PROLOG는 인공지능 언어의 양대산맥이다. LISP는 상징기호를 처리하기 쉽고 PROLOG는 규칙을 처리하기에 적절한 언어이기 때문이다.
인공지능을 여러 측면으로 정의할 수 있겠지만 "컴퓨터를 이용하여 어떤 문제를 해결하는데 있어서 어떻게 하면 경험적인 지식을 가장 잘 이용할 수 있을까 하는 방법을 연구하는 분야"라고 할 수 있다. 즉 인공지능에 있어서 가장 핵심이되는 요소는 지식을 이용한다는 점이다.
그럼으로 인공지능 프로그램이란 많은 양의 지식을 문제해결에 이용하여 주로 부호조작(symbol manipulation)으로 해결하거나 많은 양의 규칙(rule)을 이용하는 프로그램이라고 생각할 수 있다.
다양한 도구

인공지능 언어는 (그림1)에서 보는 바와 같이 LISP나 PROLOG 등이 포함된 고급언어에서 부터 KEE나 EMYCIN과 같은 전문가시스템 구축도구에 이르기까지 다양하다. 그러나 여기서 주의해야 할 점은 LISP나 PROLOG 혹은 앞에서 열거한 소프트웨어 도구를 이용하여 프로그램했다고 해서 전부 인공지능 프로그램이 되는 것은 아니다. 인공지능 프로그램은 FORTRAN 이나 COBOL, 심지어는 어셈블리어로도 개발할 수 있다. 여기서 중요한 것은 개발하는 도구가 무엇인가가 아니고 그 프로그램이 문제해결을 위하여 경험적인 지식을 이용 했느냐 아니냐 하는 점이다. 인공지능 언어는 단지 한개의 도구로서 인공지능프로그램의 생산성을 향상시키거나 그 프로그램을 효과적으로 수행하기 위하여 필요한 것일 뿐이다.
한편 인공지능 응용분야를 살펴보면 초기에는 부호조작(symbol manipulation)이 주류를 이루었기 때문에 부호조작에 적합한 LISP가 많이 사용되었다가 지식을 이용하는 방법이 달라짐에 따라 규칙(rule)을 처리하기에 용이한 PROLOG도 각광을 받고 있다.
그러나 이러한 고급언어(high levellanguage)만으로는 많은양의 지식을 처리하는 응용시스템을 개발하기에 불편하므로 EMYCIN을 시작으로 해서 KEE와 같은 소프트웨어 도구도 등장하게 되었다. 여기에서는 LISP와 PROLOG에 대해서 살펴보기로 한다.
부호처리에 적절, LISP
부호처리(symbol manipulation)에 적합한 최초의 언어는 1957년도에 '카네기멜론'(Carnegie-Mellon)대학의 Newell과 Shaw, Simon에 의해서 개발된 IPL이다. 이듬해 IPL의 List처리 방법을 이어 받은 LISP가 McCarthy에 의해서 개발되었다.
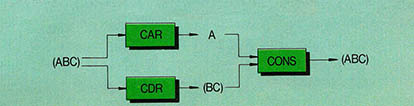
순수한 함수언어로서 LISP의 구성을 살펴보면 첫째 LISP가 처리하는 데이타 구조는 List이고 둘째 이 List를 다루는 CAR,CDR,CONS와 같은 몇개의 매우 간단한 명령어로 이루어져 있다.
예를들면 List (A.B.C)에 적용되는 3개의 명령어의 관계를 살펴보면 (그림2)와 같다.
이외에 LISP의 구성요소는 조건적으로 수행하게 었는 COND와 새로운 명령어를 정의할 수 있는 기능 등이 있고 프로그래밍하기 쉽도록 여러가지 새로운 기능이 추가되었다.
LISP가 인공지능언어로서 유명하게된 배경은 다음과 같다. 첫째 LISP는 대화식 (interactive)으로 프로그램할 수 있어 터미널에서 자유자재로 LISP 프로그램이나 데이타를 표시하거나 변경시킬 수 있다는 점이다. 둘째는 개발환경에 관한 것으로서 LISP를 이용하여 프로그램하기에 편리한 도구가 많이 개발되어 있다는 점이다. 세째는 LISP가 List Processing이라는 원어가 말해주듯이 부호처리에 적합하다는 점이다. 마지막으로 LISP는 프로그램이나 데이타나 다 같은 형식이고 데이타도 프로그램처럼 수행될 수 있다는 점이다.
이외에 다른 장점은 LISP의 명령어가 몇개 안되기 때문에 배우기가 쉽다는 점이다. 그러면서도 간간히 이 몇개의 기능을 조합하여 새로운 기능을 정의 하기도 쉽고 매우 강력한 기능을 발휘하기도 한다.
그러나 LISP는 각기 서로다른 사용자들이 자기 나름대로 기능을 확장시켰기 때문에 LISP의 표준화가 이루어져 있지 않고 있다는 점이 문제이다.
또다른 LISP의 문제점은 LISP의 수행속도가 느리다는 점이다. 이것은 왜냐하면 LISP가 함수언어이므로 현재의 '폰 노이만'(Von Neumann)컴퓨터구조에는 적합하지 않기 때문이다. 이 문제를 극복하기 위하여 LISP를 매우 효과적으로 수행하기 위한 LISP전용기계로서 Symbolics나 Lambda, Explorer, Xerox 등과 같은 LISP기계가 개발되어 널리 사용되고 있다.
인공지능의 응용분야의 변천으로 PROLOG나 여러가지 소프트웨어 도구가 개발되고 있지만 현재 LISP를 이용해서 지식베이스에 추론기능을 가진 문제해결용의 PLANNER(Hewitt, 1971)나 CONIVER(Sussnan, McDermott, 1972) 등과 같은 소프트웨어 도구가 개발되고 앞으로도 인공지능의 중요한 언어로서 존속할 것이다.
PROLOG는 서술논리(predicate logic)에 기반을 둔 언어로서 Kowalski가 기본개념을 제안 하였고 1972년 Marseile 대학에서 Colmerauer와 Roussell에 의해 처음으로 제작되었다. 그후 Preira와 Warren은 DEC-10에 PROLOG 컴파일러를 개발하였으며 유럽각지에서 확장 발전되어 왔다가 최근 일본에서 제5세대컴퓨터의 핵심으로 체택되면서 각광을 받기 시작했다.
규칙처리에 편리
프로그래밍 언어로서 PROLOG는 종래의 컴퓨터 언어와는 달리 논리에 그 기반을 두고 어떤 문제를 해결하려는 시도였다.
이 사실은 PROLOG의 원어가 Programming in Logic이라는 것에서도 쉽게 발견할 수 있다. 즉 PROLOG는 문제를 나타내는 방법으로 논리(clausal form)을 채택하고 어떤 질문에 대답하기 위해서는 논리의 추론 방법을 적용하였다.
일반적으로 PROLOG프로그램은 지식베이스(프로그램), 제어전략, 그리고 추론방법 등 세가지 요소로 구성된다. 그러나 여기서 사용자는 제어전략과 추론방법에 대하여 알필요없고 단지 지식베이스인 PROLOG프로그램에만 신경쓰면 된다.
지식베이스는 크게 사실(fact)과 규칙(rule)을 정의하는 PROLOG언어로 구성되어 있다. 사실(fact)지식이라함은 주어진 대상(object)들간의 관계를 나타내는 것으로 예를들면 'Tom likes Mary'라는 사실을 다음과 같이 표현한다.
Likes(Tom,Mary)
한편 규칙(rule)은 이미 있는 사실을 이용하여 다른 사실을 정의하는것으로 '아버지의 아버지는 할아버지이다'라는 규칙을 PROLOG 언어로 표현하면 Grandfather(X,Y):-Father(X,Z),Father(Z,Y)로 나타낼 수 있다.
사용자가 지식베이스를 구축하고 난 뒤 어떤 문제에 대한 질문(question)을 할 수 있는데 그 형식은 '?'기호를 사용하여 "Tom이 Mary를 좋아하느냐?"라는 질문은
?Likes (Tom, Mary)
로 나타낸다. 그러면 PROLOG는 이 질문에 대답하기 위하여 리졸류션(resolution)에 근거를 둔 추론방법을 이용하여 지식베이스를 차례로 검색한 뒤 사용자의 질문에 답하게 된다.
PROLOG가 인공지능언어로 적합한 점은 다음과 같다. 첫째 PROLOG가 규칙(rule)을 처리하기에 편리하다는 점이다. 둘째 PROLOG는 일반 컴퓨터와는 달리 문제해결하는 방법에 대해서 프로그램 하는 것이 아니고 문제를 PROLOG 언어로 묘사하면 된다는 점이다. 셋째는 추론기능을 포함하고 있어 주어진 사실과 그들과의 관계를 이용하여 새로운 사실만 정의하면 된다는 점이다. 마지막으로 PROLOG는 지식베이스의 지식만 수정하므로 인공지능 프로그램 전체를 수정하지 않고 확장할 수 있다는 점이다.
이러한 특성때문에 PROLOG는 전문가 시스템 개발이나 자연어처리, 데이타베이스 묘사및 질의어 등에 널리 사용되고 있다. 그러나 PROLOG는 제어기능의 부족과 지식을 표현하는 능력에 문제점을 가지고 있기때문에 여러가지 방향으로 수정보완 되고 있으며 현재는 PROLOG 전용기계를 제작 하기 위한 연구도 진행중이다.