인공지능 시스템의 성능은 보관되어 있는 지식의 양에 의하여 결정된다. 또한 갖고 있는 지식을 응용분야에 따라 어떤 방식으로 표현하는가가 중요한 문제이다.
인간이 지능을 갖고 있다는 것을 나타내는 가장 큰 특징적 요소는 무엇인가? 인공지능 분야에서는 인간의 지식이 바로 지능 또는 지적인 행위를 결정짓는 가장 중요한 요소라고 생각하는 것이 현 추세이다. 초기의 인공지능 연구가들에게는 문제를 해결하는 일반적인 방식 즉 어떤 보편적인 원리가 존재하여 그것이 무엇인가에 촛점을 맞추었으나 그러한 원칙은 문제를 해결하는데 효과적이거나 효율적이지 못했다.
70년대 중반부터는 가장 중요한 것은 그 문제에 관한 충분한 지식이라는 것이 널리 인식되었다. 예를 들어 우리는 조금 잘못쓰여졌거나 모호한 문장도 이해할 수가 있다. 또는 어떤 물체를 시각적으로 판단하려 할때도 먼저 관계되는 물체가 어떤 성질의 것이고 세상의 물체들에 대한 충분한 지식이 있는 경우에 보다 쉽게 판별할 수가 있다. 따라서 인간이 갖고 있는 지식을 어떻게 효율적으로 컴퓨터 내에 저장할 것인가. 어떻게 현 상황에 관련된 직접적인 지식을 검색하여 주어진 지적인 문제 해결에 사용할 것인가 하는 문제가 인공지능 분야의 가장 핵심적이면서 기초적인 분야로 등장하였다. 이러한 연구 분야가 바로 '지식 표현'이라는 분야이다.
인공지능에서는 지식 그 자체가 무엇인가를 철학적으로 다루지는 않는다. 다만 철학이나 심리학, 언어학 등의 관련 분야의 연구를 토대로 또는 자체적인 연구를 통해서 인간이 갖는 지식이라는 고도의 정보를 컴퓨터에 효과적으로 표현하고자 하는 것이다. 지식 표현 방식에는 일반적인 원리는 없으나, 표현 방식을 몇 개의 커다란 범주로 묶어서 분류하는 것이 일반적인 기술 방식이다. 본 글에서도 이와같은 방식으로 지식 표현의 여러 기법들 중에서 논리, 의미 네트웍, 프레임, 스크립트, 규칙 등의 방식들에 대해 간략하게 소개하도록 한다.
논리는 인공지능의 감초
논리는 그리스 시대부터 등장해서 19세기말에서 20세기초에 크게 발전되었다. 논리 철학자나 분석 철학자들에 의해 발전되고 개념이 형성된 논리를 지식 표현의 수단으로 컴퓨터에 사용한 것은 인공지능 연구의 초기부터이다. 지식 표현에서 사용되는 논리는 단순한 명제들이 아닌 술어들과 한정기호(quantifier)들을 포함하는 일차술어논리가 가장 널리 쓰인다. 이 논리를 이용해서 "모든 새는 날개를 갖고 있다" 라는 사실을 표현하면 아래와 같다.
∀x. Bird(x) ← HasWings(x)
이때 ∀ 기호는 '모든'의 의미를 나타낸다. 이 지식에 어떤 새 Tweety가 있다는 것을 첨가하면 위의 식에다 'Bird(Tweety)를 첨가하게 되며 두개의 논리식에서 'Has Wings(Tweety)'라는 결론을 유도할 수 있다. 이와 같은 과정을 추론이라고 한다.
즉 논리를 이용한 지식 표현 방식을 채택한 인공지능 시스템이 갖고 있는 지식은 바로 위와 같은 논리식들의 집합이 된다. 이런 시스템에 어떤 질문이나 문제 해결을 요구하는 것은 그 질문이나 주어진 문제를 역시 논리식으로 변환하여 그것이 갖고 있는 지식에서 부터 증명될 수 있는 정리인가를 증명하고 그 과정 중에서 필요한 정보를 얻거나 문제를 풀도록 하는 것이다. 예를 들어 아래의 간단한 문제를 살펴보자
"로보트가 A지점에 있고 B, C, D지점에 상자가 있을 때 이 상자들을 한 군데로 모으도록 하라"
위 문제에서 현재 상황은 아래와 같은 논리식들로 표현할 수 있다.
ATR (A)
AT(Box1, B)
AT(Box2, C)
AT(Box3, D)
주어진 목적은 다시 아래의 논리식으로 표현된다.
∃x. AT(Box, x)∧AT(Box2, x)∧AT(Box3, x)
이 식의 의미는 '모든 Box들이 어떤 장소 x에 놓여져 있는가'라는 의미로 해석 될 수 있지만 그것이 목적인 경우에는 그러한 x로 상자들을 모으라는 뜻으로 해석된다. 위의 예는 실제로 70년대 초에 미국 '스탠포드' 연구소에서 개발한 STRIPS라는 로보트 계획 수립 프로그램에서 사용한 방식이다.
논리를 사용하는 지식 표현 방식은 여러 가지의 추론 원리들이 적용되기 때문에 그 의미가 명료하고 증명이 수학적으로 가능하다. 또한 표기 방식이 널리 통일되어 있어서 이해가기가 쉽고 한번 표현된 것은 어떤 상황에서도 똑같이 사용될 수 있기 때문에 경제적이다. 그러나 논리를 사용한 방식에는 몇 가지의 약점이 있다. 첫째로 구조화 원리가 없다는 점이다. 즉 우리가 갖는 지식은 하나 하나의 어떤 덩어리로 표현되어 전체가 다루어지는 경우가 많다. 예를 들어 '개'라는 물체를 생각할 때 우리는 개에 관한 많은 정보를 한꺼번에 끌어 낼 수 있다. 그리고 그것들이 모두 개에 관한 것이라고 알고 있다. 그러나 일차 논리로는 각각의 개별 지식을 표현할 뿐이지 이들이 모두 개에 관한 지식이라는 것을 나타낼 수가 없다. 두번째의 결점은 아직은 논리식의 증명이 상당히 시간이 많이 드는 작업이라는 점이다. 세번째로는 상황이 변화됨에 따라 지식이 갖는 진리값이 수시로 변화할 수 있는데 논리는 이를 다루는데 효과적이지 못하다는 점이다.
삼단논법식(?)추론
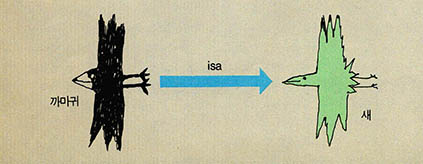
의미 네트웍은 인간 기억의 모형을 연구하는 인지 심리학자들에 의해 개발되고 발전한 방식이다. 의미 네트웍은 기본적으로 그래프라는 자료 구조와 일치한다. "모든 까마귀는 새다"라는 사실을 의미 네트윅을 써서 표현하면 아래 그림과 같다.
의미 네트윅이 갖는 가장 큰 특징은 상속 개념이다. 즉 'isa'화는 링크를 통해 상위 개념과 하위 개념과의 관계가 표현되며 상위 개념의 성질을 하위 개념에서 상속받는다. 위 그림의 의미 네트윅을 통해서 이를 살펴보자.
위의 네트윅을 보면 "새는 날개를 갖고 있으며 까마귀는 새고 그 색깔은 검정이며, 갑과 을은 까마귀이고 을의 색깔은 흰색이다."라는 사실들이 표현되어 있다. 이때 갑의 색깔은 표현되어 있지 않지만 갑이 까마귀이기 때문에 그 성질을 상속받아 검정이라고 유추할 수 있다. 또한 새가 갖는 다른 성질도 모두 갖는다.
의미 네트윅의 기능에는 상속 외에 기정치 또는 임의 가정치 들을 쉽게 나타낼 수 있는데, 위의 그림에서 까마귀의 색깔이 그 예이다. 이런 임의 가정치는 정보가 없는 경우에 그 정보를 대신한다. 그러나 특정한 정보가 있으면 그 값이 우선한다. 위의 예에서 을의 경우가 그 예이다.
인간의 지식저장과 비슷
1975년 미국 MIT대학의 '민스키'교수가 프레임 형식을 발표한 이후 프레임과 이와 유사한 형태의 복합적 구조가 지식 표현에 널리 쓰이게 되었다. 프레임이란 하나의 복잡한 구조로 어떤 개체에 대한 지식을 하나의 골격을 갖는 구조로 표현하는 것이다. 예를 들어 '코끼리'라는 객체를 표현한다면 아래와 같을 수 있다.
Generic Elephant
specialization-of : Mammal
color : (gray,white)
length-of-nose : long
residence : jungle
eat : peanut
위에서 보듯이 어떤 프레임이 나타내는 객체의 각 특성은 슬롯(Slot)과 그값의 쌍으로 표현한다.
프레임이 갖는 특징은 우리가 어떤 기대나 예상 또는 가정에 바탕을 두고 지식을 표현하고 처리할 수 있다는 점이다. 이는 인지 심리학의 원형 이론과 잘 맞는 개념이다. 이 이론은 우리가 대하는 자연물에는 어떤 정의가 없고, 우리는 가장 전형적인 모습의 원형을 갖고 있다가 어떤 특정한 물체를 보았을 때 그 원형과 얼마나 부합되는 가를 살펴서 판단한다는 것이다.
프레임을 처리하는 방식은 기본적으로 부합에 의한 방식이다. 즉 원하는 프레임을 구성하여 이 프레임과 부합되는 프레임을 찾는다. 프레임도 의미 네트웍와 마찬가지로 상속이 가능하다.
프레임은 인간의 지식 저장과 유사한 표현 방식을 갖는 장점이 있으나, 그 프레임의 의미가 뚜렷하지 않고 모든 정보가 가정적이기 때문에 어떤 정의를 표현하기가 어렵다. 그러나 자연물과 같은 객체를 나타내는 지식을 표현하는데는 아주 유용하다.
연속적인 사건을 표현
프레임이 정적인 지식을 나타내는 표현 형식이라면 스크립트는 연속적인 사건의 상호 인과 관계 및 그들로 이루어진 상황에 대한 지식을 표현하는 수단이다. 예를 들어 아래의 문장을 살펴보자.
"철수는 어제 아리랑 식당에 갔다. 그는 갈비탕을 주문하였다. 좋은 서비스가 마음에 들어 식탁위에 천원을 놓고 음식값을 낸 뒤 식당을 나왔다." 이때 "철수가 무엇을 먹었는가?" 하는 질문에 우리는 쉽게 '갈비탕'이라고 말할 수 있다. 또는 "식탁위에 놓은 천원은 무엇인가?"하는 질문에 우리는 쉽게 '팁'이라고 대답할 수 있다.
어떻게 우리는 이러한 대답을 할 수 있는 것인가? 예일 대학의 '샹크'(Schank)교수와 그 동료들은 사람에게는 식당이 주요한 단어가 되고 식당에서 일어나는 일반적인 사건들의 연속 관계를 갖고 이를 바탕으로 추론한다는 이론을 발표하였다. 이 이론은 특히 자연어 처리와 이해에 관해 좋은 결과를 나타내었다. 아래에 '식당'에 대한 스크립트를 아주 단순하게 나타내었다.
역할 : 손님, 종업원, 요리사, 회계, 주인
장치 : 테이블, 메뉴, 음식, 계산서, 지불, 팁
입력조건 : 손님은 배가 고프다. 손님은 돈이 있다.
결과 : 손님은 돈이 줄었다. 주인은 돈을 전보다 더 갖고 있다. 손님은 배가 고프지 않다. 손님은 기분이 좋다.(경우에 따라)
장면 : 1. 손님이 식당으로 들어간다
2. 손님이 테이블에 앉는다.
3. 음식을 주문한다.
4. 음식을 먹는다.
5. 종업원을 위해 팁을 남긴다.
6. 계산을 한다.
7. 식당을 나온다.
위에서 본 예는 불완전하지만 간단한 예가 된다. 앞에서 예를 든 이야기를 이 스크립트를 바탕으로 이해를 하면 그 이야기에 나타나 있지 않은 이야기는 스크립트를 통해서 추론할 수 있다. 물론 실제 스크립트는 위의 예보다 훨씬 복잡하다. 예를 들어 각 장면은 하나가 아닌 여러 개의 다른 장면으로 이어질 수 있다.
스크립트는 사건의 인과관계 등을 바탕으로 어떤 상황의 사건에 대한 지식을 표현하는데 유용한 기법이지만 그 구조가 너무 복잡하며 또한 우리가 어떤 상황에서 가장 알맞는 스크립트를 선택하거나, 변화되는 상황에 따라 적절히 대처하는 것이 쉽지 않다.
전문가시스템에서 널리 활용
규칙이란 인공지능 시스템 특히 전문가 시스템에서 널리 쓰이는 지식 표현의 한 방법이다. 이 방식은 어떤 조건과 그 조건을 만족하였을 때 수행되어야 하는 행위 또는 판단 등을 나타내는 구조로 되어 있다(IF-THEN구조). 예를 들어 아래의 규칙을 살펴보자
규칙1 : 인화성 액체가 누출되면 소방서에 연락하라.
규칙2 : 누출된 것의 pH가 7보다 작으면 누출된 물질은 산성이다.
규칙3 : 누출 물질이 산성이고 식초 냄새가 나면 누출 물질은 초산이다.
이와같은 규칙들이 모여서 하나의 지식베이스를 형성한 것이 규칙 베이스이다. 이러한 규칙을 갖는 시스템에서는 현재 얻어진 데이타들이 어떤 규칙의 조건을 만족하게 되면 THEN이하가 실행되게 된다. 그 결과는 또 새로운 지식 첨가가 될 수도 있다.
규칙이 갖는 하나의 특성은 각 규칙의 조건이나 결과에 불확실성을 나타내는 정보가 표현될 수도 있다는 점이다. 예를 들어 "열이 나고 콧물이 나고 재치기를 하면 감기이다." 라는 규칙은 그 조건이 만족된다고 반드시 감기일 수는 없다. 다만 90%정도 감기라고 판단할 수 있는 것이다. 또한 '열이 난다'라는 사실이나 '콧물이 난다'는 사실 역시 정도의 차이가 있는 것이다. 규칙에는 이러한 불확실성을 표현하기 위한 여러 방식들이 있으며 이들이 규칙의 의미를 더욱 높여주고 있다.
규칙이 전문가 시스템에서 널리 쓰이는 이유는 불필요한 중간 과정을 생략할 수가 있으며 경험적 지식을 손쉽게 표현할 수가 있다는 점이다.
또한 손쉽게 새로운 규칙을 추가시킬 수 있는 장점이 있으나, 문제는 여러 규칙들이 상호 연관이 깊을 때 이 방식은 상당히 어려워진다.