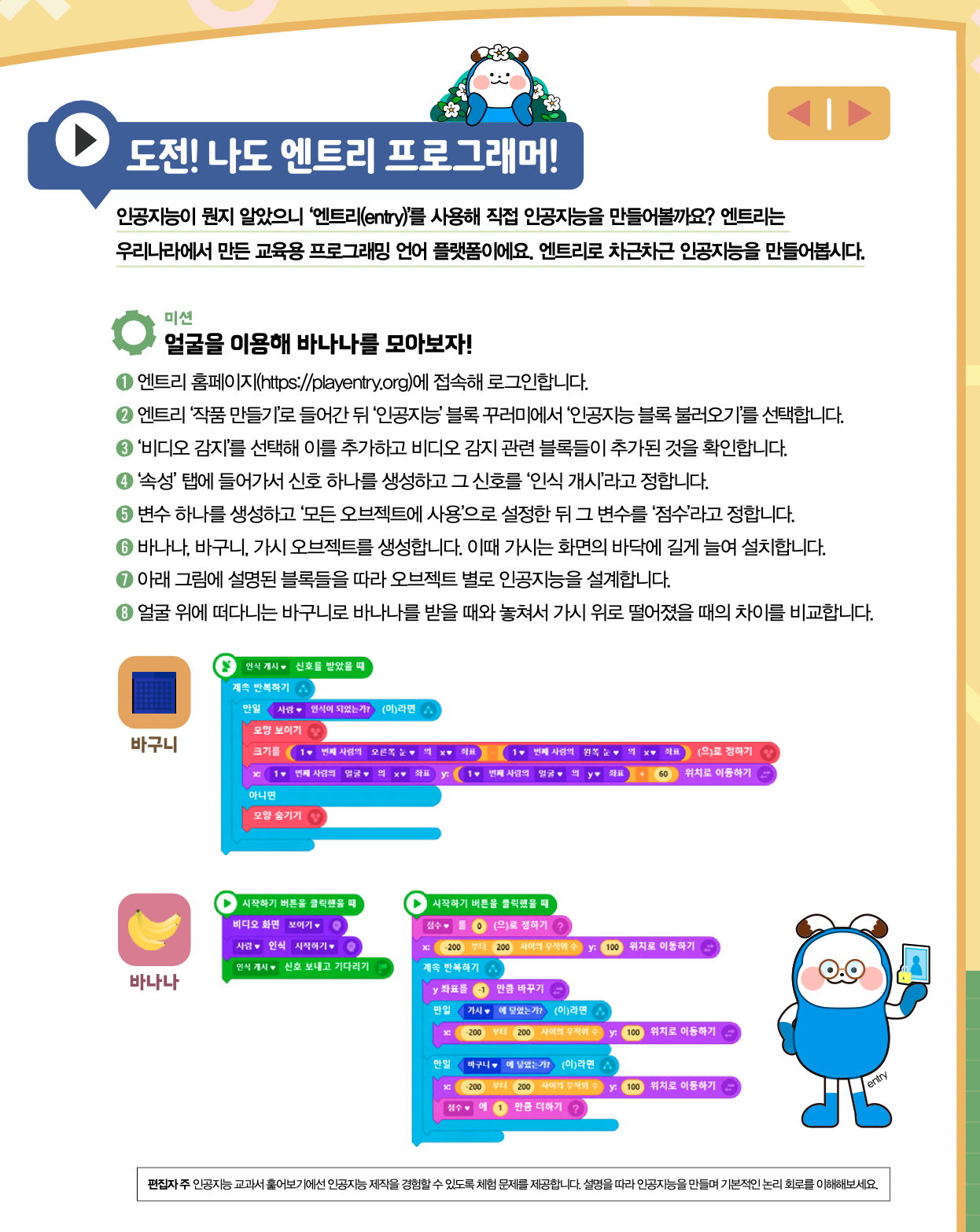
인공지능은 어떤 원리로 작동하며, 또 인공지능이 만든 결과물은 어떻게 활용할 수 있을까요? 인공지능 교과서 훑어보기 2탄에서는 인공지능이 데이터를 어떻게 다루고, 어떤 데이터를 만들 수 있을지 알아봅시다!
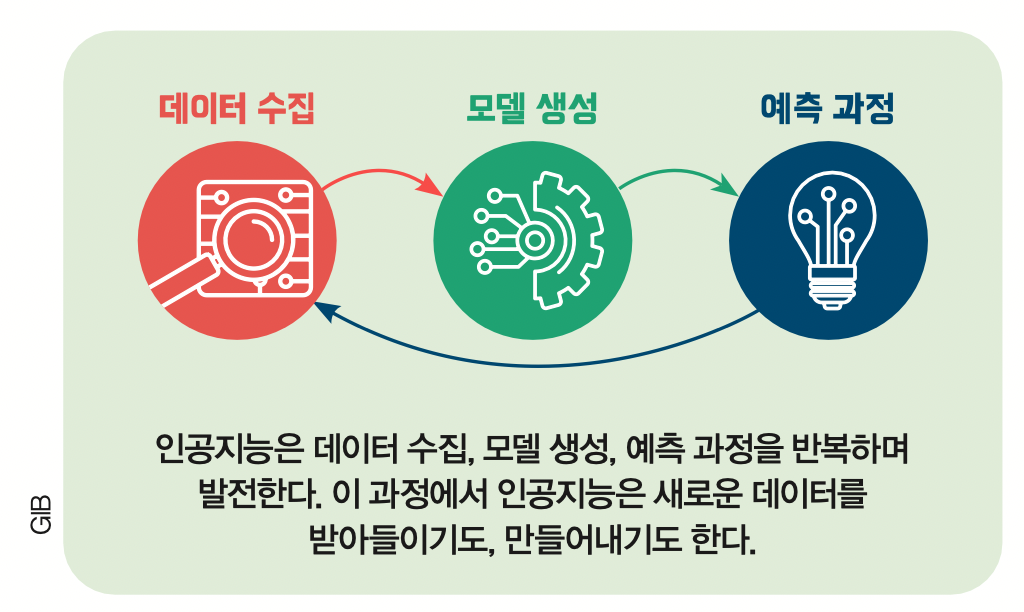
데이터란 무엇일까요? 표준국어대사전에 따르면 데이터란 ‘컴퓨터가 처리할 수 있는 문자, 숫자, 소리, 그림 등의 형태로 된 정보’입니다. 즉 인공지능에 데이터를 입력하면 인공지능은 이를 이용해 결과를 예측하는 것이죠.
이 과정을 반복하면서 인공지능이 발전합니다. 사람이 다양한 경험을 통해 배우고 진화하는 것과 비슷해요. 다시 말하면 데이터는 인공지능이 점점 똑똑해지도록 만드는 재료가 되며, 그렇기 때문에 데이터의 양과 질이 인공지능의 성능을 좌우한다고 볼 수 있죠.
인공지능이 적절하지 않은 데이터를 사용한다면, 원하지 않는 결과를 얻을 수 있습니다. 그래서 인공지능을 활용할 때, 무엇보다 데이터의 특성을 파악하는 것이 중요하죠.
데이터, 어떤 특징과 종류가 있을까?
데이터의 속성이란 다른 데이터와 구분해 어떤 데이터를 설명하는 성질로, 서로 별개이며 독립적이라는 특징이 있습니다. 이를테면 ‘성별에 따른 수명 데이터’에는 나이와 성별이라는 두 가지 속성이 있죠. 데이터의 속성은 인공지능이 사용하는 요소가 됩니다.
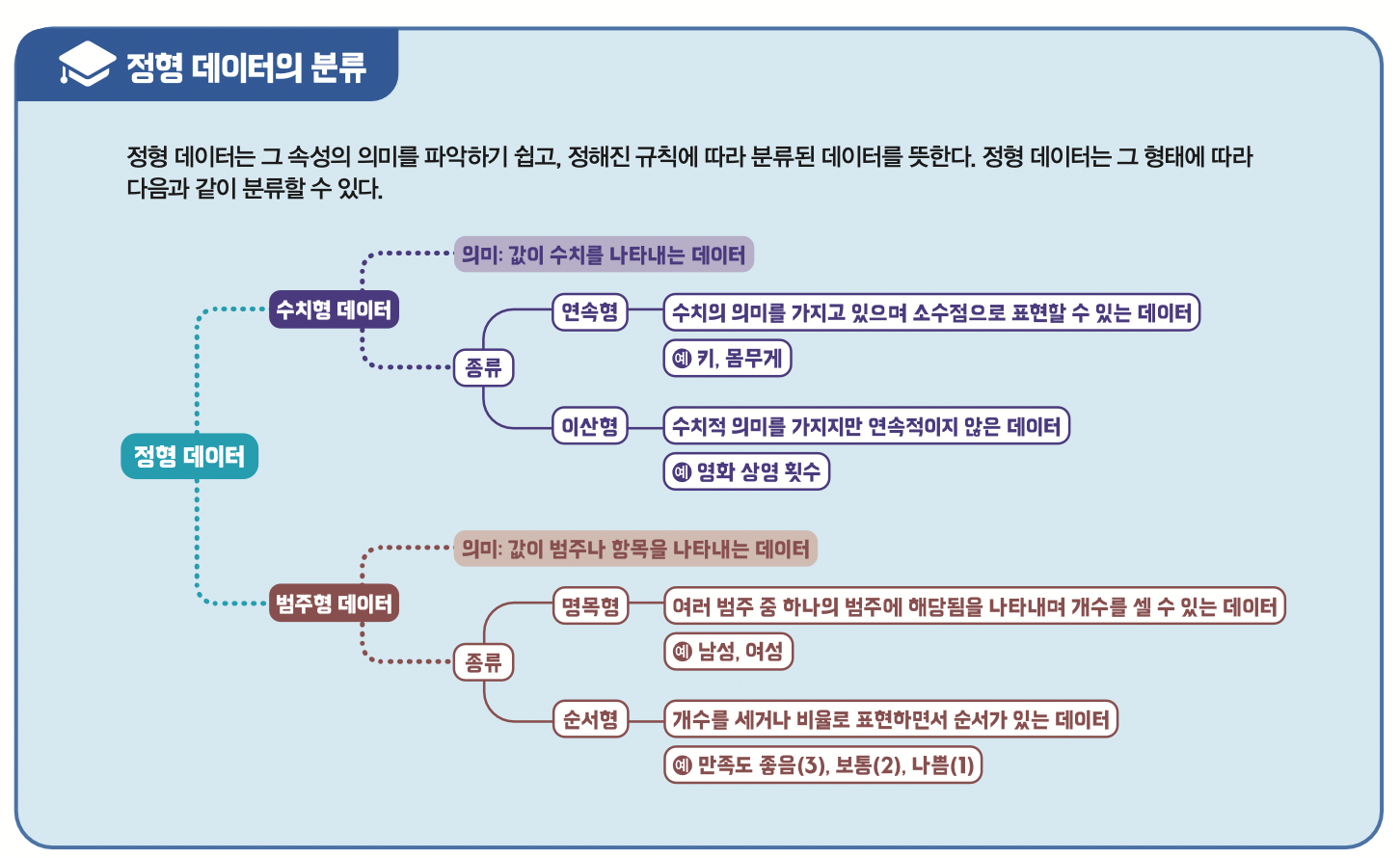
또 데이터는 특성에 따라 ‘정형 데이터’와 ‘비정형 데이터’로 구분할 수 있습니다. 정형 데이터란 의미를 파악하기 쉽도록 규칙에 따라 정리된 데이터를 말합니다. 정형 데이터의 예로는 우편번호, 전화번호, 주민등록번호와 같이 규칙에 따라 잘 정리된 자료들이 있죠. 반면, 비정형 데이터란 의미를 한눈에 파악하기가 쉽지 않고 규칙을 갖지 않는 불규칙한 데이터를 뜻합니다.
인공지능이 데이터를 분석할 때는 데이터가 잘 정리돼 있을수록 사용하기 편합니다. 그래서 인공지능은 입력 데이터로 정형 데이터를 선호합니다. 비정형 데이터는 규칙에 따라 정리돼 있지 않아 인공지능이 비정형 데이터를 사용하기 위해선 그 내용을 규칙에 따라 정리해 정형 데이터로 변환할 필요가 있죠.
데이터, 어떻게 모으고 쓸 수 있을까?
인공지능은 문제를 해결하기 위해 방대한 양의 데이터를 이용합니다. 그렇다면 인공지능은 데이터를 어디서 수집하는 것일까요?
데이터를 수집하는 경로는 크게 ‘공공 데이터 검색’, ‘민간 데이터 검색’, ‘직접 수집’의 방법으로 나뉩니다. 공공 데이터는 정부나 지방자치단체 등의 공공기관이 만들고 관리하는 데이터로 무료로 사용할 수 있다는 장점이 있습니다. 민간 데이터는 기업이 만들고 관리하는 데이터로 다양한 주제의 데이터를 사용할 수 있다는 장점이 있죠. 직접 데이터를 수집하는 것은 설문 조사 등을 통해 데이터를 얻는 방법으로 사람과 인공지능이 딱 필요로 하는 데이터를 얻을 수 있다는 장점이 있습니다.
인공지능이 수집한 데이터에는 학습에 방해가 되는 등 문제 해결에 필요한 데이터만 있지는 않습니다. 또 인공지능에게 주어진 데이터만으로는 양이 적어 학습이 어려운 경우도 있죠. 그래서 수집한 데이터를 인공지능이 필요로 하는 데이터로 만들 필요가 있습니다. 이를 ‘데이터의 가공’이라 합니다. 인공지능이 입력된 데이터의 개수를 세거나 데이터의 평균과 같은 통계적 수치를 사용해야 할 때는 데이터를 가공해 새로운 데이터를 만들어야 합니다.
좋은 데이터, 많으면 많을수록 좋지!
빅데이터란 사람이 기존에 지니고 있던 도구의 관리 및 분석 능력을 넘어서는 방대한 양의 데이터와 이 방대한 양의 데이터로부터 가치있는 결과를 분석하는 기술을 뜻합니다. 빅데이터는 인공지능의 학습성능을 높여 줍니다. 이것은 마치 학생이 학습량을 늘렸을 때 시험에서 높은 성적을 거두는 것과 같죠. 또 효율적인 알고리듬을 사용하는 인공지능이 빅데이터를 이용하면 높은 완성도로 문제를 해결할 수 있습니다. 예를 들어 넷플릭스는 사용자가 시청한 특정 영화나 드라마와 비슷한 장르의 콘텐츠를 추천해줍니다. 이는 빅데이터를 이용해 만든 알고리듬 때문에 가능합니다. 따라서 빅데이터와 인공지능의 발전은 함께 이뤄진다고 볼 수 있습니다.