올해 3월, 한 케이블채널의 인터넷 생방송에서 인기 보이그룹 ‘워너원’의 대화 내용이 생중계되면서 논란이 불거졌다. 방송 시작을 인지하지 못한 멤버들의 대화 내용이 방송을 탔고, 그 과정에서 단어 몇 개가 욕이나 은어처럼 들렸기 때문이다.
이 사건은 사설 감정업체인 디지털과학수사연구소가 감정 결과를 내놓으면서 일단락됐다. 디지털과학수사연구소 측은 ‘미리미리 욕해야 겠다’는 ‘미리미리 이케(이렇게) 해야 겠다’로, ‘쉬쉬’는 기계음으로 판단했다. 이정수 디지털과학수사연구소장은 “파형을 보고 음절을 하나하나 분리해 들어본 결과 ‘욕해’가 아닌 ‘이케’로 들렸다”고 설명했다.

목소리 분석 기술은 실제 범죄 수사에서도 중요한 단서가 된다. 음성이 녹음된 데이터에 시비를 가려낼 만한 중요한 정보가 담겨있거나, 보이스피싱에서 용의자가 어떤 말을 했는지 증거를 찾는 경우에도 필요하다.
박남인 국립과학수사연구원 디지털분석과 공업연구사는 “다양한 소리가 섞여 있을 때 사람의 귀는 원하는 소리만 집보여중해서 들을 수 있는데, 이를 ‘칵테일파티 효과’라고 한다”며 “반면 기계는 중요한 소리뿐 아니라 주변에서 들리는 잡다한 소리를 모두 저장한다”고 말했다. ‘너목보(너의 목소리가 보여)’의 기술은 어디까지 발전했을까.
사람마다 다른 ‘목소리 지문’ 찾는다
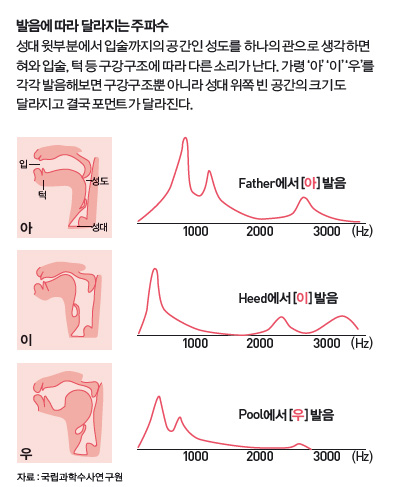
음성을 분석하기에 앞서, 먼저 누구의 목소리인지 밝혀내는 일이 중요하다. 목소리는 폐로부터 기관지를 거쳐 올라온 공기가 기도 상단에 있는 성대를 울리면서 만들어진다. 이때 성대에서 생겨난 진동이 성대 윗부분에서 입술까지의 공간(성도)을 거치면서 소리로 바뀐다. 혀와 구강구조의 형태에 따라 다양한 발음이 만들어진다.
성대는 미닫이문처럼 후두 양옆에 달려 있는 얇은 근육막이다. 숨을 쉴 때는 성대가 열리면서 공기가 지나다니고, 말을 할 때는 성대가 닫힌다. 성대의 길이와 두께, 탄력도에 따라서 공기와 부딪힐 때 생기는 진동수(1초 동안 진동하는 횟수로 단위는 헤르츠(Hz))가 사람마다 다르다. 이 진동수에 따라서 소리의 높낮이(피치)가 달라진다. 관이 두꺼운 플루트보다 얇은 피콜로가 훨씬 가늘고 높은 소리가 나는 것처럼, 일반적으로 성대가 굵은 성인 남성(85~185Hz)이 성대가 비교적 얇은 성인 여성(165~255Hz)에 비해 목소리가 낮고 굵다.
박 연구사는 “진동수뿐 아니라 사람마다 발성할 때 성도의 구조, 혀와 입술과 턱 등 조음기관의 생김새에 따라 주파수의 분포(포먼트·formant)가 달라지고 결과적으로 음색이 달라진다”며 “목소리를 시각화하면 사람마다 고유한 띠 모양 패턴인 ‘성문’이 나타난다”고 설명했다. 성문은 일종의 ‘목소리 지문’이다. 사람마다 성문이 다르기 때문에 성문으로 누구 목소리인지 판단할 수 있다.
전문가들은 피치나 포먼트 등 음성신호를 수치화한 ‘음성특징벡터’를 사용한다. 음성특징벡터는 사람의 귀가 소리를 들을 때 잡을 수 있는 특징들을 수학적으로 모델링한 값이다.
예를 들어 10명의 목소리를 녹음한 다음, 각 목소리에서 음성특징벡터를 추출한다. 이 데이터를 이용해 복잡한 확률 분포를 추정할 수 있는 ‘혼합 가우시안 모델’을 만든다. 이후 10명 중 한 사람의 목소리를 녹음해 음성특징벡터를 추출한 뒤, 혼합 가우시안 모델과 비교하면 확률적으로 가장 유사한 목소리를 찾을 수 있다.

국립과학수사연구원은 금융감독원과 함께 이 기술을 보이스피싱 용의자 수사에 활용하고 있다. 용의자의 DNA 정보를 확보해 데이터베이스를 구축해 놓으면, 사건 현장에서 찾은 혈흔이나 머리카락에서 얻은 범인의 DNA와 비교해 용의자의 신원을 밝힐 수 있다. 마찬가지로 보이스피싱 용의자의 목소리 정보를 확보해 데이터베이스를 만들어 놓으면, 이후 보이스피싱 사건이 발생했을 때 음성 데이터를 통해 신원을 확인할 수 있다.
박 연구사는 “지문이나 DNA와 마찬가지로 음성 데이터를 대량 확보한 뒤 통계적으로 가장 확률이 높은 모델을 찾는 방식”이라며 “다양한 음성 정보를 수집해 구축한다면 추후 인공지능(AI)을 활용해 훨씬 정확하게 분석할 수 있을 것”이라고 설명했다.
스펙트럼 이용해 음성 변조 확인
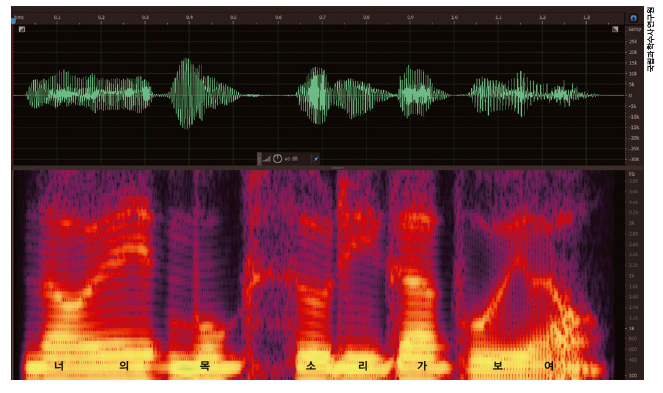
녹음한 소리의 주파수를 변환해 시각화하면 스펙트럼이 다양하게 나타난다. 대부분 불규칙한 파형으로 나타나는데, 사람 목소리는 특정 주파수 대역에서 일정한 형태의 주파수로 파형을 그린다. 불규칙한 백색소음과 달리 사람의 목소리는 주기적으로 성대가 떨려서 만들어지기 때문이다.
박 연구사는 “사람의 음성은 약 95% 이상이 8kHz 미만 대역폭에 몰려 있어 이 범위에 속한 잡음을 중점적으로 제거한다”고 말했다. 목소리가 담긴 주파수 대역의 잡음을 제거하면, 크고 작은 주파수를 가진 파형만 남는다. 전문가들은 잡음을 없앤 깨끗한 음질의 소리를 듣고 정확한 대화 내용을 확인하는 등 필요한 정보를 분석한다.
음성 변조 여부도 스펙트럼으로 확인할 수 있다. 변조된 구간은 스펙트럼의 분포 범위나 형태가 다르다. 음성 변조 과정을 역으로 실행하면 원래 음성에 가깝게 복원할 수 있다는 뜻이다.
음악 파일처럼 고음질 음원을 녹음할 때는 샘플링 레이트(아날로그 신호를 디지털로 변환할 때 초당 저장되는 데이터 비율)가 44.1kHz 이상이고, 목소리 파일은 대부분 약 8kHz다. 박 연구사는 “만약 8kHz로 녹음한 음성 파일을 2배인 16kHz로 재생하면, 전체 재생시간은 절반으로 단축되고 초당 재생해야 할 음성데이터는 2배로 증가해 목소리 톤이 높아지는 식으로 변조된다”고 설명했다. 이런 원리를 역으로 적용하면 톤이 원래보다 높은 파일에서 주파수를 낮추는 방식으로 원래와 가까운 상태로 복구할 수 있다.
인공지능(AI)으로 단어 인식
조만간 음성분석 AI가 과학수사에 활용될 수도 있다. 이미 다른 분야에서는 사람의 말을 알아듣고 음악을 틀거나, 날씨를 알려주며, 심지어 통역까지 가능한 AI 스피커가 개발됐다.
AI 스피커가 말을 알아듣는 원리는 과학수사에서 ‘목소리 주인’을 찾을 때와 비슷하다. 단어별로 다양한 목소리 데이터를 학습한 뒤, 단어를 들었을 때 확률적으로 이와 가장 비슷한 데이터를 찾아 단어를 인식한다.
AI가 언어 데이터를 학습할 때 단어마다 고유한 특징값을 추출한다. 음소나 단어뿐 아니라 어휘와 문법, 주제 등으로 분류해 추출하기도 한다. 이후 새로운 음성이 입력되면 여기서 추출한 값과 원래 저장돼 있던 값들을 비교해 가장 비슷한 패턴을 찾아 음성의 내용을 판단하고 명령을 실행한다.
AI 스피커의 성능은 학습 데이터가 많을수록 좋아진다. 딥러닝 기술을 적용해 스스로 학습하면서 음성과 뜻 사이의 연결고리를 찾는다면, 사람마다 발음과 억양이 조금씩 달라 오차가 생겨도 정확한 답을 찾아낼 확률이 높다.

지난해 4월 김상훈 한국전자통신연구원(ETRI) 음성지능연구그룹 책임연구원팀은 사람의 음성을 실시간으로 문자로 바꾸는 ‘9개 언어 음성인식기술’을 개발했다. 이는 2012년 개발한 ‘지니톡’ 기술을 업그레이드시킨 것이다. 지니톡은 영어, 중국어, 일본어, 프랑스어, 스페인어 등 5개국 언어를 한국어로 통역하는 AI로, 정확도는 95% 정도다.
김 책임연구원은 “9개 언어 음성인식기술은 독일어, 러시아어, 아랍어 등 3개국 언어를 추가해 8개국 언어를 통역할 수 있다”며 “1개 언어 당 단어 약 100만 개를 인식할 수 있다”고 말했다. 9개 언어 음성인식기술은 현재 ‘말랑말랑지니톡’ 앱으로 상용화됐다.
이 기술의 핵심은 사람의 신경망을 모방해 스스로 언어를 학습하는 인공신경망이다. 김 책임연구원은 “이 AI가 새로운 언어를 학습하는 데 걸리는 시간은 2~3일 정도”라고 말했다.
말랑말랑지니톡 앱은 자동통역 기술도 탑재했다. 올해 2월 평창 동계올림픽이 열린 강릉과 평창에서는 자원봉사자와 식당 주인, 택시 기사, 외국인 등이 이 앱을 사용했다. 김 책임연구원은 “앞으로 AI가 학습을 거쳐 지금보다 훨씬 똑똑해질 전망”이라면서 “조만간 20개국 언어를 통역하도록 개발을 진행하고 있다”고 밝혔다.