식물은 동물보다 많은 수의 유전자를 간직한 유전자원의 보고다. 마음대로 움직이지 못하기 때문에 그만큼 유전자를 이용해 생산한 물질에 의존하기 때문이다. 수많은 식물의 유전자에서 인간에게 유용한 금싸라기 유전자를 어떻게 발굴하는지 살펴보자.
2000년말 쌍떡잎식물을 대표하는 애기장대의 게놈프로젝트가 완료돼 약 2만5천종의 유전자가 확인됐다. 2002년 중반에는 외떡잎식물을 대표하는 벼 게놈프로젝트가 1차로 완성돼 3만5천-5만종의 유전자 존재가 밝혀졌다. 식물 유전자가 이렇게 통째로 밝혀지는 상황에서 유용유전자 발굴이 중요하다고 하면, 무슨 자다가 봉창 두드리는 소리냐고 반문할 수도 있다.
분명 식물이 간직한 유전자는 게놈프로젝트를 통해 존재가 드러나고 있다. 그러나 유전자의 존재를 확인했다고 해서 그 기능을 저절로 알지는 못한다. 예를 들어 열매를 맺게 하는 유전자는 분명 게놈프로젝트에서 분석해 내놓은 유전자들 속에 들어있다. 그러나 그 많은 유전자 중에 누가 그런 역할을 하느냐 하는 의문에 대한 해답을 게놈프로젝트는 제시해주지 않는다.
돌연변이를 이용한 유전자낚시
특히 식물은 의약품이나 산업원료로 활용할 수 있는 유용한 2차대사산물을 생산하는 경우가 많다. 이와 관련되는 유전자는 모델식물인 벼, 애기장대에 다 들어있지 않아 해당 식물체에서 발굴해야 한다. 이 때문에 자생식물은 소중한 유전자원이 되며, 이를 대상으로 엄청난 부가가치를 약속하는 유용유전자를 발굴하려는 연구가 전세계적으로 활발히 진행되고 있다.
무엇을 유용유전자라 말하는 것일까. 식물의 입장에서는 자신이 가진 수만개의 유전자가 다 중요할 것이다. 그러나 인간의 입장에서는 유용한 유전자와 쓸모없는 유전자로 뚜렷이 구분된다. 예를 들어 특정 유전자를 식물에 도입했을 때 생산량이 늘거나 효율이 증대된다면 이는 분명 유용한 유전자다. 그러나 아무런 효과가 없다면 이는 쓸모없는 유전자다. 실제 식물이 가진 상당한 유전자가 인간의 입장에서는 쓸모없다.
유용유전자 발굴을 이해하기 위해 DNA를 좀더 자세히 들여다보자. DNA는 ‘당-인산-당-인산…’이라는 뼈대에 4종류의 염기(A, T, G, C)가 당의 한쪽 어깨 위에 붙어 있는 구조다. 인간의 경우 게놈의 크기가 약 30억 염기쌍인데, 23개의 DNA 분자(염색체)로 나뉘어져 있다. 인간이 가진 유전자의 총수를 4만개로 추정하면 한개의 염색체에는 평균 1천8백여개의 유전자가 존재하는 셈이다.
사실 DNA 분자구조는 어디를 봐도 비슷비슷하게 생겼기 때문에 그 구조나 염기서열만 봐서는 어디서 어디까지가 유전자이고 어디가 유전자가 아닌 부분인지 구분할 수 없다. 예를 들어 사람 세포 하나에 들어있는 DNA를 일렬로 배열하면 약 2m 정도가 된다. 크기를 가늠하기 위해 DNA 나선의 지름을 약 4cm 정도로 뻥튀기 해보자. 그러면 인간 세포 속 DNA의 총 길이는 약 4만km. 지구둘레에 해당하는 길이가 된다. DNA 한분자의 평균길이는 약 1천km로 한반도 전체의 길이에 해당한다. DNA 한분자에 유전자는 약 6백m 간격으로 나타난다고 할 수 있으며, 실제 한개의 유전자가 차지하는 길이는 4m 정도밖에 되지 않는다. 이처럼 유전자는 전체 DNA의 극히 일부분을 차지하기 때문에 염색체 지도상에 점으로 표시된다.
유용유전자를 밝히기 위한 가장 확실한 방법은 특정 유전자가 망가진 돌연변이체를 얻는 것이다. 예를 들어 어떤 유전자가 망가져서 왜소증이 나타난다면, 그 기능은 식물의 생장발육에 있다. 그렇다면 돌연변이체는 어떻게 얻을까, 그리고 얻어진 돌연변이체에서 문제가 되는 유전자는 어떻게 찾아낼까.
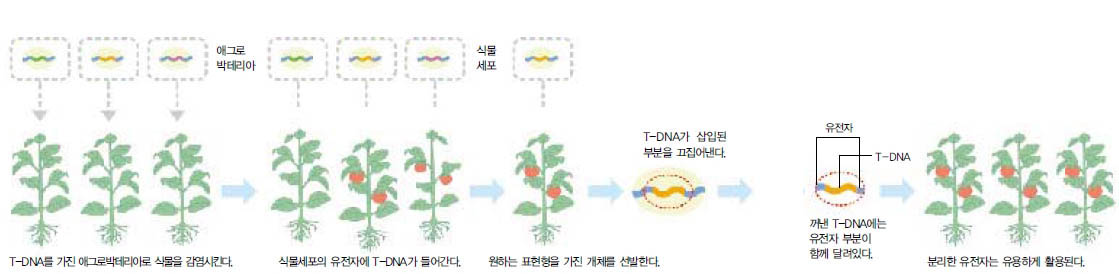
돌연변이체를 얻는 방법은 크게 물리·화학적인 방법과 생물학적인 방법으로 나눠진다. 물리·화학적 방법은 X선, 감마선 등 방사선을 식물종자에 쬐어 염색체 구조상에 변화를 일으키거나, 강력한 돌연변이유발 화학물질을 종자에 처리해 식물 DNA의 염기서열상에 변화를 일으키는 방법이다. 생물학적인 방법은 애그로박테리아라는 미생물을 식물에 감염시켜 돌연변이체를 얻는다. 애그로박테리아는 자신의 DNA 조각 일부를 식물의 염색체 속에 무작위로 삽입하는 특성을 갖고 있는데, 이때 삽입되는 DNA 조각을 T-DNA(Transfer-DNA)라 한다. 식물의 유전자 속에 T-DNA 조각이 삽입되면 식물의 유전자는 기능을 완전히 잃어버려 돌연변이체가 된다.
애그로박테리아가 가진 T-DNA는 이미 그 구조와 기능, 염기서열이 밝혀져 있다. 또한 돌연변이체의 생산에 활용할 수 있게끔 T-DNA를 적절히 변형시켜 놓았다. 변형된 T-DNA를 가진 애그로박테리아로 식물을 감염시킨 뒤 얻어진 식물체를 형질전환체라고 부른다. T-DNA는 식물 염색체 속에 무작위로 삽입되므로 각각의 형질전환체는 서로 다른 유전자가 망가진 돌연변이체가 된다. 그런데 실제로 많은 경우에 T-DNA는 유전정보가 없는 곳이나 쓸모없는 유전자에 삽입돼 표현형이 나타나지 않는다. 따라서 가장 먼저 원하는 표현형을 가진 돌연변이체를 선발해야 한다.
돌연변이체가 선발되면 해당 유전자는 그 돌연변이체가 가진 T-DNA를 이용해 끄집어낸다. T-DNA를 끄집어내면 해당 유전자가 같이 따라 오는데, 마치 낚시 바늘에 지렁이 미끼를 끼워놓으면 물고기가 같이 딸려오는 것과 같은 이치다.(그림1)
표지판 보면서 찾아간다

T-DNA는 염색체상에 무작위로 삽입되기 때문에 자신이 원하는 표현형을 가진 돌연변이체를 선발하기 위해서는 많은 수의 T-DNA 삽입 형질전환체를 생산해야 한다. 이 때문에 전세계의 많은 연구소와 필자를 비롯한 국내 연구진은 T-DNA 삽입 형질전환체를 대량으로 생산해 돌연변이체를 선발하는 작업을 진행하고 있다.
하지만 아무리 많은 T-DNA 삽입 형질전환체들을 뒤져봐도 원하는 특정 돌연변이체가 얻어지지 않는 경우가 허다하다. 이런 경우에 유용유전자를 발굴하기 위해 유전자지도에 기초한 유전자 클로닝법(map-based gene cloning)을 사용한다. 이 방법은 염색체상에 존재하는 무수히 많은 분자마커들을 이용한다.
여기서 분자마커란 무엇일까. 인간을 예로 들면 일란성쌍둥이가 아닌 한 개개인들은 염기서열의 정보가 조금씩 다르다. 평균적으로 약 1천염기쌍당 하나씩 염기서열상의 차이가 나타난다. 이런 차이가 외모, 성격, 유전적 소양의 차이를 만든다.
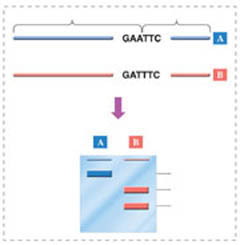
염기서열상의 차이가 공교롭게도 DNA를 자르는 제한효소의 인식부위에 발생한다면 그 부위를 제한효소로 절단했을 때 절단한 DNA 조각의 크기에 차이가 발생한다. 이를 제한효소절단부위길이차이(RFLP, Restriction Fragment Length Polymorphism)라 한다(그림 2). RFLP는 염색체상의 특정한 위치를 나타내는 표지로 이용되는 분자마커다.
이와 같은 분자마커들의 위치가 표시된 염색체 지도를 물리지도라 한다. 이들 마커들은 우리가 유용유전자들을 찾아가는데 일종의 도로 표지판과 같은 역할을 한다. 우리가 친척집을 찾아갈 때 지도를 들여다보면서 거리의 표지판을 따라서 찾아가는 것과 같은 방법이다. 염색체 중간 중간에 분자마커라는 표지판이 존재하기 때문에 자신이 찾고자 하는 유전자 부위를 이미 지나쳤는지, 아직 조금 더 가야 하는지를 판단할 수 있다.
분자마커를 이용해 유용유전자를 발굴하는 방법을 자세히 살펴보자. 멘델의 유전법칙에 따르면 둥글고 노란색인 완두콩과 주름지고 녹색인 완두콩을 교배해 잡종 제1세대를 얻으면 둥글고 노란 콩만 나온다. 그러나 제1세대의 자가수분을 통해 얻은 잡종 제2세대에서는 둥글고 노란색, 둥글고 녹색, 주름지고 노란색, 주름지고 녹색인 콩이 9:3:3:1의 비율로 나타난다. 원부모 세대에서 발견되지 않던 새로운 조합(재조합이라 함)이 일정한 비율로 나타나는 현상을 멘델의 독립의 법칙이라 하는데, 두 형질을 결정하는 유전자가 서로 다른 염색체상에 존재하기 때문이다.
그러나 두 형질을 결정하는 유전자가 같은 염색체상에 매우 가까이 존재한다면 둥근 콩은 반드시 노란색이 되고 주름진 콩은 반드시 녹색이 된다. 이를 연관이라고 한다. 실제로 같은 염색체상에 매우 인접한 두 유전자는 정자나 난자와 같은 생식세포를 만들 때 같이 따라 다닌다.
그러나 같은 염색체 상에 두 유전자가 존재하더라도 그 거리가 멀면 두 유전자는 따로 떨어질 수 있다. 이는 생식세포를 만들 때 상동염색체 간에 부분 부분의 교환이 일어나기 때문이다. 즉 멘델의 경우 둥근 형질과 노란색 형질을 결정하는 유전자가 같은 염색체상에 충분히 떨어져 있으면 소수이긴 하지만 둥글며 녹색인 완두콩이 잡종 제2세대에서 나타난다. 이러한 재조합개체가 나타날 빈도는 두 유전자 사이의 거리에 비례한다. 두 유전자가 가까우면 가까울수록 재조합개체의 수는 극히 적으며, 거리가 멀면 멀수록 재조합개체의 수는 점점 많아진다.
이 원리를 분자마커를 이용한 유용유전자 클로닝에 그대로 적용한다. 즉 돌연변이 형질과 항상 같이 따라 다니는 분자마커를 선별하면 이 마커는 연구자가 찾고자 하는 유전자와 매우 가까운 거리에 있는 것이다. 돌연변이형질과 상관없이 독립적으로 유전되는 마커는 전혀 다른 염색체 위에 있거나 같은 염색체상의 매우 먼거리에 위치한다.
일단 가까운 마커를 찾으면 그 이후에는 게놈 정보가 매우 유용하게 활용된다. 마커 근처에 존재하는 유전자들의 염기서열을 정상개체와 돌연변이개체들 간에 비교해보면 자신이 찾고 있는 유전자인지 알 수 있다. 자신이 찾는 유전자는 돌연변이체에서 염기서열상의 심각한 변화가 일어나 정상적인 단백질을 생산하는 정보가 소실돼 있다. 이렇게 찾아진 유전자는 돌연변이체에 정상적인 형태의 유전자를 도입해 돌연변이 표현형이 사라지는 것을 봄으로써 검증하는 일이 또한 가능하다.
현재 식물에서 보편적으로 이용되는 유전자지도에 기초한 유전자 클로닝 방법은 인간의 질병관련 유전자를 찾는데 결정적인 공헌을 했다. 그러나 물리지도가 제대로 갖추어져 있지 않는 식물의 경우에는 적용되지 못하는 단점을 갖고 있다.
마스터 유전자를 찾아라
유용유전자의 발굴을 위해 유전자발현의 차이를 이용하기도 한다. 유전자발현이란 DNA상태로 저장돼 있는 유전자 정보를 이용해 단백질을 생산하는 과정을 말한다. 특정한 단백질 하나를 생산하기 위해 하나의 유전자 속에 들어있는 유전정보를 세포가 활용하는 경우를 상상해보자. 인간을 포함한 고등동식물은 유전정보를 저장하는 핵과 그 정보를 활용해 단백질을 생산하는 세포질이 공간적으로 분리돼 있다. 그러나 유전자는 하나의 꾸러미, 즉 염색체에 같이 존재한다. 따라서 하나의 단백질을 생산하기 위해 전체 염색체를 세포질로 갖고 나오는 것은 터무니없는 짓이다.
이런 문제를 극복하기 위해 하나의 단백질을 생산할 때 세포는 해당 유전자에 대한 정보를 RNA라는 형태로 복사한다. RNA는 단 하나의 유전자에 대한 정보만을 가진 복제품이어서 쉽게 세포질로 이동할 수 있고, 단백질을 생산하는데 활용된 뒤 폐기될 수 있다. 이것이 DNA 속의 유전정보를 RNA형태로 복사해서 단백질을 생산하는 본질적인 이유다. 따라서 특정 유전자가 RNA 상태로 복사되면 이를 유전자가 발현됐다고 말할 수 있다.
예를 들어 식물에 저온저항성을 제공하는 유용유전자를 찾는다고 생각해보자. 식물을 저온에 처리하면 이에 적응하기 위해 다양한 유전자를 발현시킨다. 그러나 실제 이 과정에서 얻어진 유전자 한두개를 농작물에 도입하면 저온저항성이 거의 증가되지 않는다. 한두개의 유전자 발현만으로는 저온적응이 되지 않기 때문이다. 그러나 이 유전자들의 발현을 한꺼번에 제어하는 마스터 유전자가 분명 존재한다. 이 마스터 유전자는 농작물에 도입했을 때 저온저항성을 증가시켜 한대지역에서도 농작물이 생존할 수 있게 해준다. 이 마스터 유전자는 어떻게 발굴할 수 있을까.
저온에서 발현되는 유전자들의 프로모터 부위를 비교해보면 공통적인 염기서열을 가진 부위가 나타난다. 이 부위에 결합하는 성질을 가진 유전자가 바로 마스터 유전자다. 마스터 유전자를 찾기 위해 식물 유전자들을 대장균의 발현 벡터 속에 삽입해 마치 도서관처럼 대장균들을 모아놓은 라이브러리를 만든다. 즉 하나의 대장균에는 한개의 식물 유전자가 들어있고, 이 유전정보에 따라 식물단백질을 생산하게끔 제작하는 것이다. 이 라이브러리에 방사능동위원소로 표지한 저온발현 프로모터 조각을 넣어주면, 프로모터 조각과 결합하는 단백질을 가진 대장균을 찾을 수 있다. 이 대장균 속에는 우리가 찾는 식물의 마스터 유전자가 들어있다.
최근에는 유전자 발현패턴을 대량으로 볼 수 있는 방법이 개발됐다. DNA칩 또는 마이크로어래이라는 방법이다(과학동아 2002년 6월호 특집 참고). 이 방법을 이용하면 식물의 특정한 조직 또는 특정 생리상태에서 발현되는 유전자들을 찾을 수 있어 유용한 유전자원을 발굴해낼 수 있다.
추출물이 간직한 단서 좇기
식물이 생산하는 물질들은 항암작용, 항균작용, 항충작용 등 다양한 유용성을 가진다. 이 물질들을 생산하는 효소유전자를 발굴해낸다면 매우 유용하게 활용할 수 있다. 예를 들어 주목나무의 박피에서 추출해내는 택솔이라는 물질은 항암작용을 가진 매우 값비싼 약이다. 그러나 주목박피에서만 추출되기 때문에 생산하는데 많은 제약이 따른다. 택솔을 흔히 재배하는 배추나 무에서 생산하게 할 수는 없을까. 택솔을 생산하는 효소유전자만 발굴해낼 수 있다면 유전공학을 이용해 충분히 가능하다.
효소유전자의 발굴을 위해서는 우선 유용물질의 생합성단계를 정확히 파악해야 한다. 방사능동위원소로 관련된 물질을 표시해 생합성이 어떻게 이뤄지는지 알아냈는데, 최근에는 유기화학, 생화학 분야의 비약적인 발전으로 추론을 통해 생합성단계를 밝혀내기도 한다. 일단 생합성단계를 알아내면 각 단계별로 작용하는 효소유전자의 발굴은 크게 두가지 방법으로 이뤄진다.
첫째, 식물체 추출물로부터 효소단백질을 먼저 분리하고 이로부터 효소유전자를 찾는 방법이다. 식물체 추출물 속의 단백질들을 크로마토그래피법 등을 이용해 성질에 따라 분리해 효소활성이 어디에 들어있는지 확인하는 과정을 반복한다. 단백질의 크기와 전기이온도 등 서로 다른 성질에 따라 분리하는 과정을 몇차례 반복하면 거의 순수한 효소단백질을 얻을 수 있다.
이렇게 얻은 단백질은 질량분석기로 분석해 아미노산 서열을 파악할 수 있다. 아미노산 서열을 알면 역으로 염기서열을 대략적으로 추정하는 일이 가능하다. 이 염기서열을 이용해 그 식물체의 유전자 풀에서 해당 효소유전자를 끄집어낸다. 또는 분리된 효소단백질을 쥐나 토끼에 주사해 항체를 만든 후 이 항체를 이용해 효소유전자를 찾아낼 수도 있다. 이때에는 대장균 발현벡터 라이브러리를 이용한다. 식물 단백질을 생산하도록 제작된 대장균 발현벡터 라이브러리에 항체를 넣어주면 효소단백질을 생산하는 대장균에만 항체가 결합해 쉽게 효소유전자를 가진 대장균을 찾을 수 있다.
둘째, 효소와 기질이 결합하는 효소-기질 반응을 이용해 대장균 발현벡터 라이브러리를 직접 이용하는 방법이 가능하다. 대장균 발현벡터 라이브러리에 기질을 넣어주고 반응산물을 만들어내는 대장균을 바로 찾는 방법이다. 이 경우 효소단백질을 분리하거나, 항체를 생산하는 등의 과정이 필요하지 않지만, 기술적 제약이 따르고 있어 보편적으로 이용될 수 있는 방법은 아니다.
최근에는 생합성단계를 일일이 다 규명하지 않고도 효소유전자를 찾을 수 있는 방법이 모색되고 있다. 예를 들어 택솔을 생합성하는 주목박피나, 사포닌을 생합성하는 인삼의 뿌리 등에는 이들 유용물질의 생합성에 관여하는 효소유전자들이 충분히 발현될 것으로 기대된다. 이들 조직에서 발견되는 mRNA를 이용해 cDNA 라이브러리를 제작한 후, 이 라이브러리 속의 유전자들을 대량으로 분석하는 방법을 통해서 효소유전자를 찾고 있다.
현재 많은 효소유전자들의 염기서열과 단백질 3차구조가 분석돼 데이터베이스화돼 있다. 따라서 염기서열의 분석을 통해 효소유전자를 추정할 수 있을 것으로 기대된다. 우리나라 자생식물이용기술개발사업단은 인삼, 가시오갈피 등에서 유용물질의 생산에 필요한 효소유전자를 이와 같은 방법으로 탐색하고 있다.
21세기는 유전자원을 우선적으로 확보하는 국가가 세계경제를 주도할 것으로 예측되고 있다. 현재 우리나라의 자생식물에서 인간에게 유용한 유전자를 효과적으로 발굴하기 위해서 다양한 창의적인 방법이 개발 되고 있다. 이들이 찾아낸 유전자가 만들어갈 풍요로운 미래를 기대해보자.
|상동염색체|
23쌍의 염색체를 가진 인간처럼 보통 생물은 같은 염색체를 2개 갖고 있다. 이처럼 서로 쌍이 되는 염색체를 상동염색체라 한다
|프로모터|
DNA로부터 RNA를 합성하는데 관여하는 여러 단백질들이 인식하는 유전자 부위다. 아미노산 부호화 부위의 앞쪽에 위치하며 전사가 개시되는데 중요한 역할을 한다.
|벡터|
박테리오파지나 플라스미드와 같은 DNA 절편의 운반체. DNA 절편을 특정 게놈에 삽입하기 위해서 그 DNA 절편을 삽입한 벡터를 이용한다.