생명의 암호문으로 불리는 인간DNA 염기서열 초안이 이미 공개됐다.2003년 무렵에는 완벽한 해독이 가능해질 전망이다.이제 남은 것은 유전자의 규명.최근 유전자의 개수에 대한 새로운 논쟁이 벌어지고 있다.과학자에 따라 서로 다른 숫자를 주장하는 이유는 무엇일까.
지난 6월 11일 미국 국립보건원(NIH)은 인간의 생로병사를 결정하는 청사진인 DNA 염기서열 약 30억쌍 중 27억쌍을 공개했다. 이는 1990년 출범했던 인간게놈프로젝트(Human Genome Project) 대장정의 첫 결실로서, 미국 국립보건원의 주도 아래 10여년간 전세계 3백50여 연구기관이 공동으로 참여해 30억 달러라는 막대한 연구비를 투자한 결과다. 나머지는 앞으로 3년 후인 2003년에 공개될 예정이다. 인간게놈의 완전해독은 이미 초읽기에 들어간 셈이다.
인간게놈구조가 밝혀짐에 따라 초미의 관심은 30억 염기쌍에 과연 몇개의 유전자가 존재하며, 그들이 어떻게 분포돼 있는가, 그리고 각 유전자의 기능은 무엇인가에 모아지고 있다. 유전자의 수를 정확히 알아야만 모든 유전자의 기능을 규명해 생로병사를 완전히 이해할 수 있으며, 또한 어떤 유전자가 어떤 질환의 원인이 되는가를 파악할 수 있기 때문이다.
염기 글자로 단백질 작문

우선 유전자의 개념을 이해하기 위해 게놈을 살펴보자. 인간을 구성하고 있는 가장 작은 단위체는 세포다. 각 세포의 핵에는 46개의 염색체가 존재하며 유전정보는 바로 이 염색체에 담겨 있다. 염색체는 DNA 이중나선이 히스톤과 같은 단백질에 감겨 있는 상태로 고무줄이 꼬여 있는 것처럼 모여 있는 형태다. DNA는 아데닌(A), 구아닌(G), 시토신(C), 티민(T)이라는 4가지 염기가 각각 쌍으로 연결돼 있다. 이들 염기단위체 수를 모두 합하면 30억 쌍이나 된다. 이때의 46개 염색체 또는 30억쌍의 염기서열은 하나의 단위체로서 종합적인 유전정보를 지니고 있는데, 이를 게놈(genome)이라 한다.
그렇다면 게놈의 유전정보는 어떻게 발휘되는 것일까? 유전정보의 전달은 먼저 게놈의 일정 영역의 DNA 단위(유전자)로부터 1차 산물인 RNA로 복제되며(전사 과정), 다음은 RNA로부터 2차 산물인 단백질이 합성되는 과정이다(번역 과정). 이렇게 생성된 단백질에 의해 생명현상이 발휘된다. 결국 DNA 염기서열의 유전정보는 단백질을 합성하는 암호문이라 할 수 있다. 즉 암호문은 염기라는 ‘글자’로 이루어져 있고, 글자들은 아미노산이라는 ‘단어’를 만들어 마침내 단백질이라는 ‘문장’을 이루는 것이다. 따라서 10만종의 단백질이 생산된다는 말은 게놈에 10만개의 DNA 단위 혹은 유전자가 존재함을 뜻한다.
그런데 유전자 영역은 인간 30억쌍 염기 중에서 오직 3%에 해당되기 때문에, 게놈에서 각 유전자의 위치와 구조적인 특성을 파악하기 위해서는 전체 30억쌍의 염기서열의 해독이 필수적이다. 게놈프로젝트의 목표가 바로 이것이다.
게놈프로젝트가 진행되면서 과학자들 사이에서는 과연 인간 유전자가 몇개인가에 대한 논란이 계속돼 왔다. 그 결과 지금까지 과학자에 따라 유전자 개수는 적게는 3만에서 많게는 14만까지로 추정되고 있다. 현대 과학의 최첨단을 달린다는 게놈연구에서 왜 이렇게 차이가 많이 날까.
초기에 많은 연구자들은 게놈에서 전사된 1차 산물인 RNA의 모든 종류를 모아 유전자의 종류나 유전자수를 파악해 왔다. 1차 산물인 RNA는 단일나선으로 불안정하며 또한 수명이 짧기 때문에 연구자가 시험관내에서 취급하기가 쉽지 않다. 그러나 RNA는 인위적으로 이중나선인 DNA로 전환시킬 수 있다. 이렇게 만들어진 것을 ‘cDNA’(copy 또는 complementary DNA)라고 부른다. 따라서 cDNA의 개수로부터 게놈의 유전자 개수를 알 수 있는 것이다.
물론 하나의 cDNA 자체가 바로 하나의 유전자를 의미하지는 않는다. RNA를 분리하고 cDNA로 전환하는 과정에서 RNA의 부분적인 소실이 있어 많은 경우 cDNA는 ‘조각 유전자’ 또는 EST(expressed sequence tag)라고 불린다. 즉 EST는 유전자 또는 유전자의 일부 염기서열을 의미하는 것이다.
인체조직을 대상으로 전세계에서 도출된 모든 EST에 대한 염기서열정보는 대부분 데이터베이스로 구축돼 있는데, 미국 국립보건원 산하 ‘국립생물정보센터’(NCBI)의 유전자은행(GenBank)이 바로 그곳이다. 현재까지 모아진 EST 데이터베이스(dbEST)에 등록된 총 EST 수는 약 1백60만 건에 이르고 있으며, 중복된 것을 제외하고 대표성 있는 EST를 분류하면 약 12만개에 이른다. 따라서 EST 데이터베이스를 근거로 인간 유전자 수를 약 12만개 정도로 예측하고 있다.
인간 유전자 4만개도 안된다?
그런데 게놈프로젝트가 진행되면서 이와는 다른 주장이 최근에 제기됐다. 1999년 12월과 올해 5월 인간 염색체 중에서 처음으로 21번, 22번 염색체의 염기서열 해독이 완료됐다. 이들 염색체의 염기쌍 수는 각각 33.8Mb(3천3백80만 염기쌍)와 33.4Mb(3천3백40만 염기쌍)으로 둘을 합하면 인간게놈 크기의 약 2%에 해당한다. 그리고 두 염색체로부터 찾은 유전자는 7백70개에 이른다. 그렇다면 단순한 산술계산으로 인간게놈의 총 유전자수가 불과 3만8천5백개(770/0.02)라는 것을 알 수 있다. 이렇게 되자 과학자들은 EST를 통한 유전자 수의 결정에 의심을 품고 저마다 새로운 계산 방법을 고안해내기 시작했다.
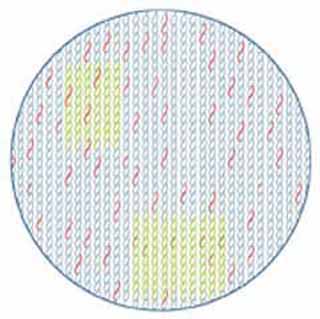
대표적으로 워싱턴 대학의 필 그린은 이미 해독이 완료된 모델생물인 선충의 유전자 수를 추산했던 방법을 사용해 매우 그럴듯한 산출 방식을 소개했다. 그는 두 세트의 유전자 종류를 이용해 유전자 수를 추산했다. <;그림1>;에서 회색 나선은 전체 유전자를 의미한다. 이중 붉은 나선으로 표시된 첫째 세트(n1)는 해독이 완료된 21번 또는 22번 염색체의 유전자나 그 외 지금까지 밝혀진 완전한 유전자 구조를 가진 ‘전장 cDNA’(full-length cDNA)들이다. 이에 반해 녹색 나선으로 표시된 두 번째 세트(n2)는 무작위로 선택된 cDNA들이다.
이때 인간게놈의 총 유전자 수를 G라 한다면 전체 유전자에서 n1 유전자가 차지하는 비율은 n1/G 로 표현된다. 또 n2 유전자 중에서 n1 유전자와 동일한 유전자를 m2라고 하면, n2 유전자 중에서 m2 유전자가 차지하는 비율은 m2/n2 로 표현된다. 그런데 많은 실험 결과 이 두 비율은 거의 같은 값을 지녔다. 즉 n1/G≒m2/n2 이므로, 전체 게놈 유전자 수 G=n1×n2/m2 로 나타낼 수 있다.
그러면 현재까지의 이용 가능한 결과를 토대로 위의 수식에 따라 유전자 수를 산출해 보자.예측 유전자 수는 염색체 22번으로부터 예측된 6백80개의 유전자(n1)와 4만3천2백78개의 EST(n2)를 대상으로 계산한 경우다. 이때 n2 중에서 n1과 일치 또는 중복되는 유전자 수는 8백48개(m2)였다. 따라서 총 유전자 수는 3만4천7백4개(G=680×43,278/848=34,704)가 된다.
또다른 경우는 전장 cDNA 7천6백62개(n1)와 선별된 4만3천2백78개의 EST(n2)를 대상으로 유전자 수를 산출한 것인데 이때 일치 또는 중복된 유전자 수는 9천8백59개(m2)였다. 같은 방법으로 총 유전자수를 산출해 보면 3만3천6백33개(G=(7,662×43,278)/9,859=33,633)다. 따라서 두 종류의 유전자를 대상으로 계산한 결과가 매우 근사하며, 앞서의 단순 산술 계산과도 비슷함을 알 수 있다.
하지만 이 방법에 문제가 없는 것은 아니다. 22번 염색체로부터 추정한 6백80개 유전자라는 수치는 이미 알려진 DNA 염기서열과 단백질 데이터베이스에서 서로 연결되는 부분을 뽑아내고, 여기에다 유전자 예측 프로그램을 가동시켜 얻은 결과 등을 합해 도출된 것이다. 그러나 현재의 데이터베이스 양과 컴퓨터 소프트웨어의 능력에는 한계가 있기 때문에 유전자 개수가 더 늘어날 가능성도 있다.
정보과학의 발전이 관건
이렇듯 새로운 유전자 수 측정 모델이 현재로서는 어느 정도 한계를 지니고 있다. 그러나 문제는 그런 한계를 감안하고서도 기존의 EST 데이터베이스에 근거한 유전자 수와는 너무나 차이가 크다는 사실이다. 그러므로 EST 유전자 수 측정 방법 역시 문제가 있다고 생각할 수 있다. 한 예로 동일한 유전자가 몇 개의 EST로 나타난다면 유전자 수는 급증할 수밖에 없다.
인간게놈의 염기서열이 거의 다 밝혀지고 공개된다는 사실은, 유전자 연구에 있어서 새로운 금맥(金脈)이 모든 과학자들에게 열린 것과 같다. 그러나 염기서열이 100% 완전 해독됐다 하더라도 전체염기서열에서 유전자를 확인하는 작업은 적지 않은 시간이 소요될 것이다. 이때 선충, 초파리, 효모 등 상당수 인간 유전자와 동일한 유전자를 갖고 있는 모델생물의 게놈정보를 활용하는 비교유전체학의 도움이 크게 필요하다. 또 기존의 데이터베이스와 유전자 예측 소프트웨어도 계속해서 발전시켜야 한다. 그래서 모두들 생명과학과 정보과학의 결합만이 생명의 암호문을 완벽하게 해독할 수 있는 지름길이라고 말하는 것이다.











