컴퓨터가 스스로 신문이나 책을 읽는다. 현재 인쇄체의 경우 95%의 인식률, 그러나 필기체는 인식수준이 떨어진다.
키보드를 두드리지 않고 컴퓨터가 한글을 이해하게 할 수는 없을까? 만약 신문을 그대로 컴퓨터에 입력시킬 수 있다면…또는 손으로 쓴 필기체 자료를 그대로 컴퓨터의 데이터 파일에 기록하게 할 수 있다면.
한글 또는 문자정보를 키보드를 통하지 않고 컴퓨터가 판독할 수 있게 하는 연구가 국내 컴퓨터과학자들에 의해 한창 진행중에 있다. 소위 '한글인식시스템'에 과한 연구가 바로 이것이다.
일반적으로 인식시스템 혹은 보다 엄밀하게 패턴인식시스템(pattern recognition system)이란 입력되는 자료의 중요한 특징들을 추출하여 확인할 수 있는 부류(class)들로 분류하는 시스템을 말한다.
이때 입력은 어떠한 형태로 나타나도 괜찮다. 따라서 한글인식시스템이라 하면 시각을 통하여 입력되는 시각자료를 대상으로 배경으로부터 글자를 구분하고 나아가 그 글자들이 한글에서 어떤 부류에 속하는가를 크기 기울기 자형(字形) 필체 등에 상관없이 분류해내는 시스템을 말한다. 이때 인식시스템에서는 분류해 낸 글자가 어떤 의미를 가지는지를 전혀 몰라도 된다.
이글에서의 관심은 어떻게 기계가 우리 사람들처럼 한글을 시각적으로 인식할 수 있느냐는 보다 공학적인 측면이 있으므로 인공적인 한글인식시스템에만 범위를 국한하겠다. 또한 시각적인 한글인식의 단위는 모음이나 자음을 호징하는 자소(字素;grapheme)를 포함하는 음절(syllagle)로 간주한다.
패턴인식의 과정
앞에서 간단히 살펴보았듯이 한글인식시스템의 주요 기능은 시각적으로 입력된 자료가 한글의 어느 음절인가를 구분해 내는 것이다. 보통 이런 결정에 도달하기까지에는 몇가지 정보처리 단계를 거친다. 전형적인 패턴인식 시스템은 (그림1)과 같이 입력기기 전처리단계 특징추출단계와 분류결정단계 등으로 구성된다.
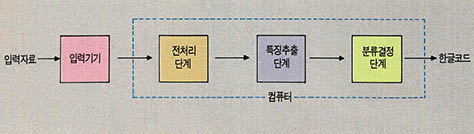
첫째로 한글인식시스템에서의 입력기기는 종이에 써있는 글자들을 광학적으로 화상(그림)으로 읽어들이는 광학스캐너(optical scanner)나 글자를 쓰는 손의 상대적인 위치를 읽어들이는 전자화판(elecrtonic panel) 마우스(mouse)등이 있다.
둘째로 전(前)처리(preprocessing)단계에서는 이미 컴퓨터 기억장치에 이차원적 배열의 형태로 입력된 화상자료를 대상으로 잡음을 제거하고 인식에 불필요한 요소들을 억제한다. 한글인식에서는 입력된 문서화상에서 글자를 구분해내거나, 세선화(細線化; thinning)시킴으로써 입력화상을 선(線)요소들로 변환시키거나, 기울어져서 입력된 자료를 돌려서 인식하기 쉽게 변환하는 등 전처리단계를 거친다. (그림2)는 입력된 글자의 예와 세선화된 글자의 예를 보여주고 있다.

셋째로 특징추출(feature extraction)단계에서는 전처리단계에서 보다 정제된 자료를 대상으로 분류에 필요한 특징요소들을 선별해낸다. 한글의 경우에는 원요소라든지 짧은 수평선요소라든지 수직선요소와 수평선요소가 직각으로 연결된 부분요소 등을 계산하는 특징추출단계를 거쳐야 한다.
마지막으로 분류결정(classifier)단계에서는 앞단계에서 추출된 요소들의 조합이 어떤 패턴부류에 속하느냐를 결정하게 된다. 한글의 경우에는 특정한 선 각 곡선들의 요소들이 특정한 자모를 결정하고, 나아가 이런 자모들의 순차적인 결합이 특정음절을 결정하는 과정이라 할 수 있다.
이 글에서는 인식의 단계들을 문서의 오프라인(off-line)인식의 예를 들어 설명했으나, 마우스 등을 통해 온라인인식의 경우도 그 과정이 대동소이하다. 오프라인 인식이란 이미 인쇄되었거나 쓰여진 문서를 대상으로함을 의미하고 온라인인식이라함은 사람이 글자를 쓰는 동작이 직접 입력되어 쓰는 것과 동시에 인식이 이루어지는 것을 의미한다.
95%의 높은 인식률

한글인식에 대한 연구는 대체로 1969년 인하대 이주근 교수가 '풀어쓰기 한글의 자모인식연구'를 발표하면서 시작되었다. 현재 온라인인식은 대체로 95%에서 99%까지 사이의 아주 높은 인식률을 보이고 있고, 충남대 김태균 교수 과학기술원 김진형교수 등의 연구실등에서 이론과 실용화 단계의 연구가 진척되고 있다.
보다 어렵고 강력한 계산기능을 요구하는 오프라인인식에서도 대상이 인쇄체인 경우 대체로 90%에서 99% 사이의 높은 인식률을 보이고 있다. 이런 경우 특히 95% 이상의 고도의 인식률은 지식을 기반으로 하는 후처리(post-processing) 단계를 거침으로서 높일 수 있다. 이 분야에서는 과학기술연구원 시스템공학센터의 김문현박사와 오원근박사, 광운대 남궁재찬교수, 인하대 이균하교수, 충남대 김태균교수, 과학기술원 김진형교수, 연세대 박규태교수와 필자의 연구실에서 주로 실용화연구가 이루어지고 있다.
그리고 필기체의 경우는 아직도 인식률이 상당히 저조하고 비교적 높은 경우에도 특정한 필자의 특징적인 글씨에만 가능한 것으로 알려져 있다. 이 분야에서는 김태균교수 등이 이론적인 연구를 진행하는 수준에 머물러 있다.
이들 대부분의 연구들이 아직 한글과 문장부호 숫자 등을 인식하는 데에 초점이 맞춰져 있고, 한자가 포함된 문장을 인식하는 것은 엄두도 못내는 상황이다.
또한 기존의 컴퓨터프로그램방식으로 인식이 어려운 필기체를 인간의 뇌의 구조와 기능을 흉내내는 새로운 방법론인 신경회로망(neural network) 모형을 통하여 한글을 인식하려는 노력이 김진형교수와 포항공대 방승량교수. 한국전자통신연구소 인공지능연구실의 양재우실장과 기초기술부의 김명원박사 등을 중심으로 기존의 방법론과는 보완적인 입장에서 시도되고 있다.
한편 오프라인인식에서 요구되는 막대한 계산량을 실시간대에 처리할 실용적인 전용프로세서 보드 등 하드웨어의 개발이 이루어져야 실용적인 한글인식시스템이 현실화될 것으로 보인다. 이를 위해 현재 국책과제인 '시각정보처리'를 중심주제로 위에 언급된 연구실들 중 다수가 참가하여 차세대 컴퓨터를 위한 지능입력장치와 신문인식 등을 통해 한글인식의 실용화를 실현하려는 노력을 기울이고 있다.
이와 함께 인식시스템에 있어서 거의 이상적이라고 간주하는 인간의 시각구조를 보다 잘 이해하고, 나아가 그런 지식을 인공인식시스템에 적용시키려는 연구도 최근 활기를 띠고 있다.
이러한 방법은 주로 여러 대학의 심리학과 전산과 전자공학과 등 관련학자들이 공동으로 진행시키고 있다. 이런 협조연구의 대표적인 예가 이번 한글날을 앞두고 열리는 한국인지과학회와 한국정보과학회 공동주최의 '사람과 기계와 언어; 한글 및 한국어 정보처리'란 긴 이름의 학술대외로 구체화되고 있다.
한글인식에 관한 연구는 맹인들에게도 책과 신문을 읽어 들여주는 컴퓨터시스템을 실현시키는 것을 목표로 하고 있다. 그러나 기존 활자화된 인간의 지식을 컴퓨터가 스스로 이해하는 지능형 컴퓨터가 궁극적인 목표라고 말할 수 있다.











