컴퓨터를 사용하는 사람들이 처음 부딪히는 장벽은 컴퓨터코드이다. 코드를 이행하는 길이 컴퓨터와 대화할 수 있는 첩경이다.
코드의 사전적인 의미는 "법전·규정·규약, 신호법·전신부호"라고 정의하고 있다. 컴퓨터에서 문자코드의 의미는 이중 신호법·전신부호에 해당한다고 볼 수 있다. 좀더 정확히 말하면, 컴퓨터 문자 코드란 컴퓨터 내에서 상호 의사전달 수단의 하나로서 통용되고 있는 일종의 컴퓨터 언어체계(음절)이다. 즉 컴퓨터의 중앙처리장치(CPU, central processor unit)와 키보드, 모니터, 보조기억장치(디스크장치), 프린터장치, 통신장치 등의 여러 입출력 장치간의 대화시에 기본적으로 사용되는 하위 언어이다.
만일 이들 장치사이에 공통의 언어가 없다면 서로 정보를 교환할 수가 없다. 이는 우리나라 사람이 한글을 사용하고 외국인들은 외국어 사용할 때, 두 언어사이에 공통 부분이나 통역체계가 없다면 서로 의사 소통을 할 수 없는 거과 마찬가지 이치이다. 예를들어, 컴퓨터에서 'A'라는 문자에 65라는 고유의 번호를 지정하여 사용하면 앞서 말한 장치들 사이에 'A'라는 문자를 65라는 고유번호로서 서로 인식할 수 있다. 실제로 사용자가 자판에서 'A'를 입력하면 이는 왼쪽에서 몇번째, 위에서 몇번째와 같은 행렬로서 인식되며 이것이 내부적인 공통 언어인 65로 변환되어 시스팀 내부에 전달된다. 시스팀 내부에서는 이를 화면에 표시하기 위하여 표시 장치에서는 이를 'A'라는 문지의 형태를 만들어 표시해 준다. (그림1)은 화면에 표시되는 문자의 모습으로서 각 눈금들은 화면에서 한점을 나타낸다.

16비트 컴퓨터란
그러면 이제부터는 이를 보다 구체적으로 설명해 보기로 한다. 컴퓨터는 0과 1이라는 2진수로서 정보를 표현한다. 이를 위해 필요한 정보용량의 최소 단위는 1비트(bit, binary digit)이다. 1비트는 0과 1만을 나타낼 수 있으므로 일반적인 정보를 표현하는 데는 매우 부족하다. 따라서 보통 정보 표현의 8비트를 지정하고, 이를 1바이트(byte)라고 한다. 1바이트는 2의 8제곱이므로 256종류의 정보를 나타낼 수 있다(실제로 0에서 255까지임). 또 2바이트를 1단어(word)라고 지정하여 65536종류의(2의 16제곱, 64K)의 정보를 표현할 수 있다. 참고로 8비트 컴퓨터란 자료(data)의 단위가 8비트(1바이트)인 컴퓨터이며, 16비트 컴퓨터란 자료의 단위가 16비트(2바이트, 1워드)인 컴퓨터를 말하는 것이다. 일반적으로 가정용(home computer)및 하위 교육용 컴퓨터가 8비트 컴퓨터에 해당하고, 업무용 또는 고위 교육용 및 개인용 소형 컴퓨터(PC, personal computer)가 16비트 컴퓨터에 해당한다.
표시장치에서는 한문자를 나타내기 위해서는 (그림1)과 같이 가로로 8점, 세로로 8점 내지는 16점이 필요하다. 그리하여 0과 1 또는 색깔로서 문자의 모양을 표시한다. 따라서 화면에 표시하기 위해서는 가로로 8점을 1바이트로 나타낼 수 있으므로 8바이트에서 16바이트까지 또는 그이상(색상을 나타내기 위해서는 화면의 한점에 대해 여러 비트가 필요함)이 필요하게 된다. 그러나 이와같이 서로 다른 장치 사이에 문자의 자형(화면의 화상 문자 정보나 프린터에 인쇄되는 문자의 모양을 font 또는 문자 pattern이라함)으로써 정보를 교환하면, 한문자를 나타내기 위해 여러개의정보단위가 필요하고, 이에따라 정보교환시에 많은 양의 자료를 주고 받음으로써 시스팀 전체의 효율이 저하되는 동시에 불필요한 과중부담을 가지게 된다. 그리하여 효율을 높이고 과중부담을 줄일 수 있는 축약된 공통의 언어가 필요하게 되고, 이것이 바로 컴퓨터 문자 코드이다.
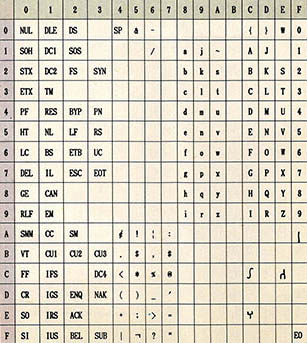
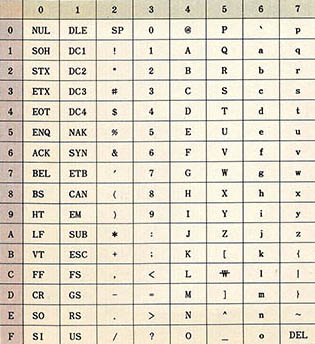
일반적으로 컴퓨터 문자 코드는 1바이트로 표시하며 256종류의 코드를 나타낼수가 있다. (대표적인 코드 체계는 ASCⅡ 코드(American Standard Code for Information Interchange, 그림2 참조)와 EBCDIC 코드(Extended Binary Code Deciml Inter-Change, 그림3참조)가 있는데 이중 EBCDIC 코드는 IBM만이 주로 사용하며, IBM-PC를 포함한 모든 PC의 대부분이 ASCⅡ 코드를 사용하고 있으므로 여기서는 ASCⅡ 코드에 대해서만 다루기로 한다. 그러나 이는 영어문화권에서 문자를 표현하는 데는 충분하나 우리나라와 같이 한글 및 한자 등을 사용하는 한자문화권에서는 매우 불충분한 용량이다. 이를 위해 여러가지의 한글 코드 체계가 고안되었다. 한글 코드 체계에 대해서는 다음절부터 다루기로 한다.
컴퓨터에서 사용하는 코드 체계에는 문자 코드 외에 화면상에서의 글자의 위치나 특성(역상문자 강조문자 밑줄긋기 깜빡이는 문자 등)을 조절하거나, 프린터의 각종 기능을 제어하고 통신시의 제어 등을 처리하기 위한 제어 코드가 있다. 이러한 제어 코드는 주로 제어 문자열이라 하여 'ESC(코드 번호 27)'로 시작하는 문자열로 구성된다. 제어 코드는 특히 프린터의 각종 기능인 역상, 밑줄, 강조, 이미지 인쇄 등을 비롯하여 가로 2배, 세로 2배, 가로 세로 2배 등의 매우 다양한 제어 기능에 활용된다.
한글 코드와 주변기기 및 통신
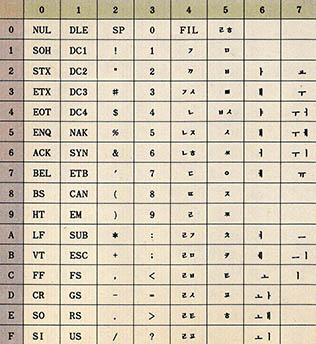
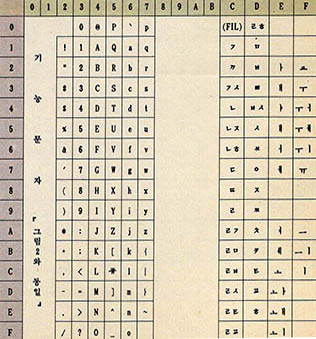
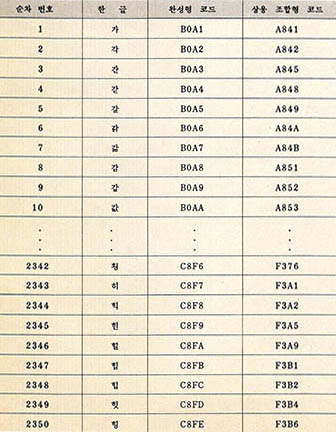
앞서 언급한 바와 같이 8비트 코드 체계로는 한글과 한자를 모두 표현할 수가 없다. 적어도 한글은 1만3천여자, 한자는 5천여자 이상의 공간이 필요하다. 그 이외에도 많이 사용되는 특수 문자, 기호, 외국문자 등을 나타내기 위한 공간도 필요하게 된다. 그리하여 기존에는 ASCⅡ 코드 체계를 확장한 코드 체계를 사용하여 왔다. 이러한 한글 코드 체계의 종류에는 크게 나누면 7비트 한글 코드(그림4 참조), 8비트 한글 코드(그림5 참조), 16비트(2바이트) 한글 코드(그림6,7,8,9 참조) 등이 있으나 그동안 국내의 컴퓨터 업체에서는 각각 약간씩의 차이를 두고 한글 코드들을 정의함으로써 그종류는 수십가지 이상이 될 정도로 다양하다.
따라서 사용자가 컴퓨터나 주변기기를 선정할 경우에 이를 잘 검토하거나 전문가와 상의한 후에 결정해야만 할 것이다. 그렇지 않으면 매우 많은 한글 코드 체계들로 인해 뜻하지 않은 불편이나 손실을 자아내게 된다. 게다가 그러한 코드 체계를 지원하는 각종 주변장치나 응용 소프트웨어가 구비되어 있는지도 역시 확인하여야 하며, 또 통신면에 있어서도 아무런 문제가 없는지, 사용상의 불편이 없는지 등도 살펴 보아야만 한다.
주변기기 중에서 가장 주의해야 할 것은 바로 프린터이다. 프린터는 문자 코드나 체계나 특히 제어 코드가 컴퓨터 또는 사용하고자 하는 응용 소프트웨어들에서 지원하는 코드 체계와 동일하여야 한다.
또 PC를 통신장치의 단말기로 사용하여 컴퓨터 정보 통신에 활용할 경우에도 주전산기(host computer)의 코드 체계와 일치하는지, 만일 일치하지 않으면 PC에 지원되는 통신용 소프트웨어 중에서 코드 변환이나 제어 코드를 지원하기 위한 전위 처리장치(frontend proces-sor 또는 preprocessor) 기능을 지니고 있는 것이 있는가 등을 사전에 알아야 한다. 이러한 전위 처리장치 등이 없거나 주전산기와 코드 체계가 동일하지 않을 경우에는 단말기로서의 PC 기능은 전혀 수행할 수가 없을 정도로, 통신상에 있어서의 코드 체계의 중요성은 매우 막중한 것임을 명심해야 한다.

그리하여 막상 값비싼 컴퓨터를 사놓고도 쓸모없는 무용지물이 되지 않도록 주의해야 한다. 특히 이는 매우 중요한 것으로서 꼭 염두에 두어야 하는 데, 보통 국가 표준 코드 체계를 지원하는 기종을 구입하면 무난할 것이다.
그리고 PC의 경우에는, 현재 어느정도 표준 코드 체계가 확립되어 있는 실정이므로, PC를 구입할 때에 큰 걱정을 하지 않아도 되는 것은 사실이다. 그래도 앞에서 말한 몇가지 사항에 대해서는 꼭 확인해보고 구입하는 것이 바람직하다.
현재 한글 코드는 16비트 코드 체계가 지배적이다. 이러한 배경에는 몇가지 이유가 있는데 지금부터는 이에 대해 살펴보기로 한다.
첫째로 기존의 7비트나 8비트 한글 코드 체계에서는 불완전한 점이 매우 많을 뿐더러 각종 응용 소프트웨어에 매우 많은 제한을 줌으로써 복잡한 문제를 야기시킨다. 구체적인 예를 들면, 7비트 한글 코드에서는 모두 영문의 코드가 배열되어 있기 때문에 한글을 표현하기 위해서는 특수한 의미를 지니는 제어문자(지시부호)가 필요하다. 그것은 다름아닌 한글 시작과 한글 끝을 나타내는 문자로서 '한'을 나타내려면 SO(Shift Out, 코드 번호 14, 영문 처리 상태를 빠져 나가는 한글 시작 코드로서 이후에 나타나기 이전까지는 모두 한글로 해석됨)+"bD"+SI(Shift In, 코드 번호 15, 한글 끝 코드)와 같이 5바이트가 소모된다. 여기에서 SO는 영문 코드 체계로부터 다른 외국의 코드 체계로 이전해 간다는 의미를 지닌 지시부호이고, SI는 다시 영문 코드 체계로 복귀한다는 의미를 지닌 지시부호이다.
한편 '가'를 나타내려면 SO+"Ab"+SI와 같이 4바이트가 필요하다. 즉 한글에 대해 실제로는 불필요한 지시부호와 함께 가변적인 길이로 표현된다. 또 '가'에 대한 코드내에서 'A'만 보고는 이것이 한글 '가'의 'ㄱ'인지 영문 'A'를 전혀 구별할 수가 없다. 한글과 영문을 구별하기 위해서는 SI나 SO를 앞에서 발견할 때까지 추적해야만 한다. 이러한 지시부호 및 코드를 이용한 한글과 영문의 구별 문제를 제거하기 위해 나타난 것이 8비트 코드 체계이나 '한'은 'ㅎ ㅏㄴ'와 같이, '가'는 'ㄱ ㅏ'와 같이 표현되므로 역시 가변길이로 인한 문제점은 극복할 수가 없다.
그러므로 화면에서 차지하는 영역에 대해 내부적으로 표현되는 코드의 길이는 전혀 예측할 수 없으므로 응용 소프트웨어에서 이를 처리하기에 매우 복잡하고, 효율의 저하를 초래하게 된다. 게다가 이 코드 체계도 영문 소프트웨어의 이식성 및 호환성을 기대하기가 매우 어렵다. 이들을 해결하기 위해 출여한 것이 16비트(2바이트) 코드 체계이다. 이는 화면에도 영문의 2배 크기로서 한글을 표시하고 내부적으로 2바이트의 고정적인 길이로서 한글 코드를 사용하기 때문에 항상 한글의 처리가 매우 간결해진다.
두번째로 16비트 한글 코드 체계에서는 한글 코드의 길이가 고정적이며 화면에서 한글이 차지하는 영역과 코드의 길이가 항상 같고 한글 및 한자 코드 영역이 매우 크므로, 많은 글자를 수용할 수 있기 때문에 각종의 응용 소프트웨어에서 한글 및 한자를 처리하기가 매우 쉬울뿐더러 유명한 외국의 소프트웨어 (영문의 경우 화면과 코드의 길이를 항상 1:1로 간주함)에 대해 한글을 사용할 수 있도록 이식시키는 작업이 매우 손쉽다.
그 이외에는 여러가지 요인이 있으나 너무 기술적인 내용들이므로 여기에서는 생략하기로 한다. 이와 같은 이유로 인해 요즘은 거의가 16비트 한글 코드 체계를 채택하고 있다. 특히 지난해에 제정된 국가 표준 한글 코드 체계(KS-5601-1987)도 16비트 코드를 위주로 고안되었고, 각 컴퓨터 업체에서도 이에 적극 호응, 채택하고 있다. 따라서 주변기기나 응용 소프트웨어도 매우 활발히 개발된 결과, 선택의 범위가 상당히 풍부해졌다.
그러면 이제부터는 이미 많이 보급되고 있는 16비트 코드 체계에 국한시켜 살펴 보기로 한다.
완성형과 조합형 한글 코드
먼저 16비트 한글 코드 체계에 대해 설명하면 다음과 같다.
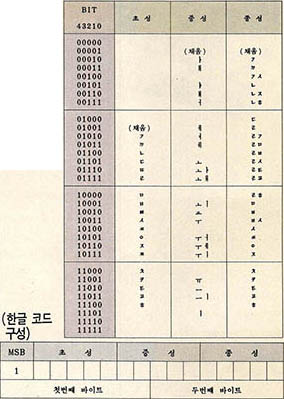
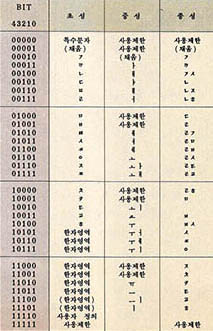
16비트 코드 체계는 8비트(1바이트)코드와 16비트 코드를 모두 사용할 수 있다. 8비트 중에서 최상위 비트(MSB, Most Significant Bit)가 0이면 이는 8비트 코드로 인식되며, 최상위 비트가 1이면 다음에 연속되는 8비트와 결합하여 16비트 코드로 인식된다. 따라서 영문, 숫자와 한글, 한자 및 특수 문자, 기호 등을 혼용하여 표시할 수가 있는 것이다. 또 한글 등은 15비트로서 코드 값이 지정된다.
16비트 한글 코드 체계에는 완성형과 조합형이 있다. 완성형은 사용빈도수가 많은 한글 음절을 골라서 각 움절에 대한 일정한 순서를 정하고 이 순서에 따라 코드 번호를 부여하는 방식이다. 반면에 조합형은 16바이트 중에서 최상위 비트를 제외한 15비트에 각각 5비트에 나누어서 각각에 초성 중성 종성의 자소를 지정하는 방법이다.
2가지 코드 체계에 대한 검토, 비교는 다음과 같다. 코드 체계를 비교할 때에는 몇가지 요인이 있는 데, 이에는 입출력시에나 문자 표현시의 효율적인 측면인 경제성이 있고, 다음으로는 국제 규격과의 연관성, 사용환경의 언어 체계 또는 문화적 특성에 대한 반영정도, 여러가지 주변기기와 응용 소프트웨어 작성시의 편리성 및 효용성, 기술력 집중을 위한 코드의 타당성 및 가능성 등을 들 수가 있다. 그 이외에도 정책적인 지원과 함께 채택한 제품에 대한 시장성 등도 고려대상이 될 수 있다.
먼저 코드 체계의 경제성 측면에서 볼 때, 2가지 코드 체계가 모두 한글에 대해 매우 압축적으로 표현한다. 예를 들면 '값'을 입력하려면 4번의 키를 눌러야 하며, 7비트 또는 8비트 코드 체계에서는 6바이트나 4바이트가 소요되는 반면, 위의 2가지 코드 체계에서는 공히 2바이트 길이의 코드 값을 갖는다. 코드 배열의 경우에 완성형은 빈도수가 높은 음절만을 골라 배열함으로써 보다 함축적인 코드 영역을 가지며, 이에 따라 모든 한글을 나타내는 조합형보다는 경제적이다.
국제 규격과의 연관성을 볼 때, 완성형이 조합형보다는 더욱 가깝게 접근하고 있다. 즉 완성형 ISO(International Standard Organization) 2022 부호 확장법을 쉽게 따를 수 있는 장점을 가지고 있다.
각각의 장단점
사용 언어 체계의 반영도 측면에서는 완성형은 한글의 모아쓰기라는 구조적인 근본 원리를 무시하고 만든 반면, 조합협은 이를 그대로 반영하여 보다 한글 고유의 특성에 충실한 코드 체계계이다. 그리하여 코드만 보고도 한글의 음소(초성 중성 종성)를 구분할 수가 있다.
편리성과 효용성의 측면에서, 완성형이 코드 발생 및 표시방법이 훨씬 간편하고 효율이 증대되나, 경우에 따라서는 조합형이 월등히 우수한 면을 가질 때도 있다. 예를 들어 어간 및 어미이 변화나 조사의 선택시에 조합형은 코드만 가지고도 각 음소를 구분할 수 있으므로 이에 쉽게 대처 할 수 있다. 이러한 것의 응용으로는 문서편집기에서 틀린 글자나 단어 등을 검사하는 작업(spell check)에서 매우 유용하게 활용될 뿐 아니라 자연 언어의 처리에서도 우수한 특성을 지니고 있다. 편리성 측면에서는 2가지 코드 체계가 서로 엇비슷하다. 또 고정길이의 코드 지정으로 인해 응용 소프트웨어 등의 작성시나 영문 소프트웨어를 이식할 때 모두 간편하게 처리할 수 있다.
코드의 타당성과 기능성을 위주로 살펴 볼 때에는 2가지 코드 체계 사이에 서로 약간의 장단점이 있기 때문에 어느 것이 우수하다고는 말할 수가 없다. 예를 들어 문자 자형의 크기는 조합형이 각 음소별로 몇벌씩의 자형만 갖추고 있으면 되지만 완성형의 경우에는 모든 문재의 자형을 가지고 있어야 하므로 매우 많은 양의 메모리(보통 ROM에 저장함)가 필요하다. 실제로 완성형이 조합형에 비해 5배에서 7배 가량 더 많은 메모리가 요구된다. 그렇지만 문자를 화면에 표시할 경우에는 완성형은 문자의 자형을 직접 가지고 와서 표시하면 되는 반면, 조합형은 매번 모아쓰기 과정을 거쳐야 하므로 속도면에서는 완성형이 우수하다. 그 이외에 통신상에 있어서나 문자열에서의 한글의 구분 및 고정 길이의 코드 값 등을 포함한 기능적인 면에서는 2가지 코드 체계가 동일하다. 그러나 기존의 코드 체계에 비해서는 2가지 코드 체계가 월등히 뛰어난 것은 사실이다.
마지막으로 각 코드 체계에 대한 시장에서의 전개상황을 보면, 조합형은 각 업체에서 어느 정도 표준으로 자리 잡고 있었으나 완성형이 국가 표준 코드 체계로 제정됨에 따라 조합형은, 기존의 소프트웨어나 주변기기 및 사용자가 작성하여 누적된 자료 등에 대한 사후 지원, 보수 등의 형태로 변모해 가고 있으며 신제품은 개발되지 않고 있다. 반면에 완성형은 정부의 적극적인 정책 지원과 더불어 시장 규모의 급성장을 예고하고 있기 때문에 각 업계에서는 이를 주축으로 모든 기술력을 집중시키고 있다. 따라서 가장 중요한 요인으로서 무시할 수 없는 시장 전개 상황 및 추세가 이미 완성형으로 기울어져 있다. 그러므로 향후보다 풍부한 응용 소프트웨어와 함께 다양한 주변기기들을 사용할 수 있고, 사용자에게는 코드의 차이로 인한 혼란을 방지할 수 있으며 제품 선택의 폭이 매우 넓어지게 된다. 그리고 각 업체에서는 시장 기반의 안정성과 더불어 규모의 확대 촉진 등에 힘입어 기술력을 집중할 수 있고, 보다 다양한 제품들에 대해 위험부담없이 개발, 보급할 수가 있다.
앞으로 사용자는 컴퓨터나 주변기기 및 응용 소프트웨어 등을 구입할 경우에 KS 완성형 한글 코드 체계를 지원하는지를 확인하여야 한다. 그래야만 앞서 말한 주변기기나 통신상에 있어서의 코드 차이로 인한 손실과 불편을 해소할 수 있는 것이다.