우리는 보통 수첩에 친구나 친척의 전화번호를 적어 두고 필요한 경우 찾아보고 있다. 수첩에 적히는 것은 전화번호 이름 주소 등의 항목이다. 그러나 다루는 전화번호가 많아 질수록 원하는 정보를 찾는데 많은 어려움이 있다. 이번달에는 전화번호부를 작성하여 실제 생활에 사용할 수 있도록 해보자.

입력 데이타의 구조

전화번호부에 기록되는 데이타로는 전화번호 이름 주소만을 다루도록 한다. 데이타를 하나의 파일(file)로 처리할 수도 있으나 개인이 사용하는 전화 번호의 수가 그렇게 많지 않기 때문에 프로그램내에서 DATA문으로 데이타 베이스(database)를 구축하기로 한다. 그리고 데이타 베이스의 맨 마지막 레코드(record)의 각 항목이 "-1","END","MARK"가 되도록 한다. 즉 (그림1)과 같은 데이타 베이스를 프로그램내에 구축하는 것이다. 메모리상에 데이타베이스가 구축되기 때문에 검색의 속도가 빨라지고 또한 각 레코드가 프로그램내에서 문장으로 처리되므로 데이타의 수정및 편집이 쉬어지는 장점도 있다. 그러나 메모리의 한계가 데이타베이스의 크기의 한계가 되는 단점도 있다.
(그림1)의 데이타 구조로 부터 BASIC 프로그램의 DATA문을 사용하여(그림2)처럼 간단하게 데이타 베이스를 구축할 수 있다.
처리하려는 데이타의 구조와 기억 방법을 정했으므로 이제 데이타베이스를 사용하는 프로그램으로 확장해가보자.

플로우차트 그리기
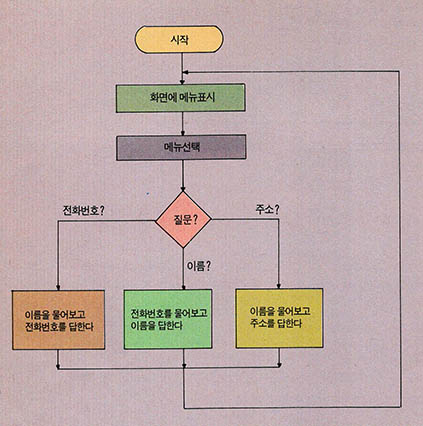
플로우차트는 작업의 흐름, 데이타처리의 흐름, 처리 방법의 논리적인 진행순서 등을 나타내기 위한 것이다. 여러가지 방법으로 전화번호부를 사용할수 있도록 프로그램을 구성할 수도 있으나 본 강좌에서는 메뉴 방식을 사용하여(그림3)과 같이 질문이 가능하도록 프로그램을 작성하여 보자.
프로그램은 처리가능한 질문에 대한 정보를 사용자에게 모두 보여 주기 위해 메뉴 화면을 사용하도록 한다. 일단 메뉴 화면이 작성되고 나면 메뉴 선택 번호에 따라 해당 서브루틴(subroutine)을 수정하도록 한다. 3가지 질문에 대한 서브루틴은 각각 200번, 300번, 400번 문부터 시작된다. (그림4)는 전화번호부 작성을 위한 시스팀 플로우차트이다.
(그림4)의 플로우차트로 부터 하향적으로(topdown approach) 설계를 해보자. 프로그램은 크게 메뉴 표시 부분과 각 질문을 처리해주는 서브루틴으로 나눠진다. 메뉴 표시 부분까지 서브루틴으로 처리하면 4개의 서브루틴이 사용된다. 주프로그램(main program)만 보더라도 프로그램의 골격을 금방 알 수 있도록(그림5)처럼 주프로그램을 구성하였다. (그림4)의 플로우차트와 골격이 같을 것이다.

(그림5)의 주프로그램에 조듬더 손질을 해야만 원하는 정보의 효율적 제공이 가능해진다. (그림6)의 40번 문장을 보자. A$=INKEY$문으로 키보드에서 손으로 누른 키의 값을 RETURN을 누르지 않더라도 프로그램에서 처리할 수 있다. 다시말하면 원터치(one touch)방식이다. 40번문에 의해 지정된 키의 값이 입력되지 않으면 프로그램의 실행은 더이상 진행하지 않는다. 40번문의 CHR$(13)은 RETURN키를 의미한다.

메뉴 화면의 설계

메뉴 화면은 사용 가능한 질문을 화면에 보여주고 사용자에게 질문의 선택권을 주는 기능을 갖추어야 한다. 메뉴를 화면에 간단 명료하게 표시하기 위해 일단 CLS(Clear Screen)라는 명령으로 화면을 지워야 한다. 그리고 난후 커서(cursor)를 원하는 위치에 보낸후 메뉴를 하나씩 표시하면 된다. 전용 메뉴 생성기(menu generator)를 사용할 수도 있으나 LOCATE 명령으로만 메뉴화면을 만들어 보겠다. (그림7)은 메뉴를 표시하는 서브루틴이며 (그림8)은 화면에 표시된 메뉴이다.

프로그램의 설명

메뉴 화면이 출력되면 원하는 작업의 번호를 선택하게 되는데 선택된 번호에 따라 해당 서브루틴이 실행된다. 서브루틴은 사용자에게 입력을 요구하며 입력된 내용에 따라 프로그램내에 들어있는 데이타베이스로 부터 원하는 결과를 출력시켜 준다. 데이타베이스가 BASIC의 DATA문으로 구성되어 있으므로 READ문에 의해 검색(search)이 실행되고 난 후, 꼭 RESTORE문으로 데이타포인터가 맨 처음의 DATA문을 가리키도록 해야 한다. RESTORE문은 메뉴선택 서브루틴의 100번문에 삽입되어 있다. 그리고 데이타 검색의 종료를 위해 데이타베이스의 맨 마지막 레코드의 항목들을 "-1", "END","MARK"로 하고있다. 따라서 서브루틴에서 READ를 한번 실행하고 난 후 첫번째 항목이 "-1"인지를 비교하여 검색이 종료를 결정할 수 있다. 이러한 레코드를 트레일러(trailer)라 부른다.
(그림10)은 (그림9)의 프로그램을 실행시켰을때 각각의 질문을 처리하는 과정을 확인하기 위해 임의의 데이타를 입력시켜 본 것이다. 데이타베이스에 기억된 문자열과 비교하기 때문에 입력을 정확하게 해야하는 단점이 있다. 즉 CHO DONG SUB을 입력하는 데 CHO DONG SUB이라고 글자 사이를 두칸씩 띄어 입력하면 원하는 결과를 찾아내지 못한다. 또한 이름의 일부분만 알고있는 상태에서는 원하는 결과를 얻어낼수 없도록 프로그램이 구성되어 있다.

효율적 사용을 위한 프로그램의 수정
(그림9)의 프로그램은 입력데이타의 제한이 있어 확실하게 데이타를 제공하지 않으면 원하는 정보를 얻을 수 없게 작성되어 있다. 그러나 BASIC언어에서는 INSTR이라는 부분문자열을 확인해주는 함수가 있으므로 불확실한 데이타로 부터 원하는 결과를 쉽게 얻어낼 수 있다. 예를들어 성만 알고 이름을 모를 때도 그 사람의 전화 번호와 주소를 알 수 있다. (그림9)의 프로그램중 다음 3개의 문장만 고치면 된다.

BASIC의 EDIT명령으로 3개의 문장을 수정한후 실행시켜보면 INSTR함수의 막강함을 느낄 수 있을 것이다. (그림11)은 수정하는 과정을 보여준다.

(그림11)에 의해 (그림9)의 프로그램은 (그림12)와 같이 수정된다. (그림12)의 프로그램을 실제적으로 사용하려면 500번이하의 DATA문을 재구성 하면 된다. 한가지 중요한 것은 제일 마지막 DATA문을 "-1","END","MARK"와 같은 양식으로 처리해주는 것이다.

(그림13)은 (그림12)의 프로그램을 실행시킨 결과이다. 전화번호를 물어보기 위해 메뉴 화면에서 1번을 선택해 들어가면 이름을 물어본다. 이름중 알고 있는 부분만 입력하더라도 전화번호를 답해준다. 메뉴 화면에서 2번을 선택하여 전화번호의 일부분 숫자만 입력하여 보면 이름을 출력해준다. 그리고 전화번호 중에서 "02"를 갖고 있는 사람들의 이름을 알고 싶을 때는 전화 번호를 입력하라는 물음에 "02"만 입력해도 된다. BASIC의 INSTR함수를 사용한 이유를 곧바로 이해할 수 있을 것이다.