달리는 기차 위에서 휴대폰에 입을 대고"본부"라고 소리쳐도 휴대폰은 그 말소리를 듣지 못한다.주변의 심한 소음과 섞여버리기 때문이다.하지만 최근 소음을 물리치고 원하는 소리만 듣는 기계가 등장하고 있다.
뇌과학 연구는 주로 공학과 의학 분야에 응용된다. 뇌의 주요 기능의 하나인 청각 기능도 음성을 이용해 기계와 인간의 상호작용을 꾀하는 공학적 응용, 그리고 청각 장애인을 위한 청각칩 이식에 관련된 의학적 응용의 두가지로 대별된다.
물론 공학적 응용의 경우 연구성과물이 기계에 부착되는데 비해 의학적 응용에서는 인간에게 이식된다는 차이점이 있다. 하지만 두가지 모두 인간의 청각 신호처리 메커니즘을 모방하고 반도체칩이나 소프트웨어로 구현된다는 공통점을 가지고 있다. 청각칩의 성능이 발전하면, 한때 TV 드라마에 등장한 인간보다 더욱 잘 듣는 생체전자여인(bionic woman) 소머즈가 실제로 우리 눈앞에 나타날 수 있다.
달리는 기차 위에서 휴대폰 무용지물
국내 TV 광고의 한 장면. 달리는 기차 위에서 쫓기는 한 사람이 휴대폰에 대고 “본부” 라는 말을 외치자 곧 헬리콥터가 나타나 구조하는 상황이 연출됐다. 그러나 현재 수준에서 이런 일은 실현될 수 없다. 기계의 입장에서 ‘들을 때’ 시끄러운 소음 속에서 유독 사람의 말만을 인식할 수 없기 때문이다. 즉 기계로서는 주변의 모든 소리가 무차별적으로 들린다는 의미다.
하지만 흥미롭게도 사람은 다르다. 달리는 기차 위라 하더라도 옆사람의 말을 어느 정도 들을 수 있기 때문이다.
이 차이는 어디서 발생하는 것일까. 과학자들은 그 비밀의 열쇠를 와우각(달팽이관)에서 찾고 있다.
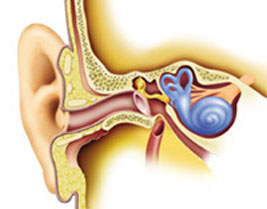
음성신호는 귓바퀴부터 시작하는 외이(外耳) 부분에서 모아져 고막에서 기계적 진동으로 변환되며, 뼈들의 복잡한 결합으로 이루어진 중이(中耳)를 통과해 내이(內耳)로 전달된다(그림 1). 외이와 중이는 음성신호를 모아 증폭하는 역할을 한다. 이에 비해 내이에서는 음파가 전기신호로 바뀐다. 이 신호가 뇌의 청각 담당 부위(청각피질)로 이동함으로써 우리가 음성을 인식하는 것이다. 와우각은 바로 내이에서 핵심적인 역할을 담당하는 부위다.
그렇다면 달리는 기차 위에서 사람이 다른 사람의 소리를 들을 수 있는 이유는 무엇일까. 즉 다른 소음에 개의치 않고 사람의 말에만 집중해서 들을 수 있도록 만드는 메커니즘은 무엇일까.
과학자들은 청각피질로부터 와우각까지 피드백(feedback) 경로가 존재한다는 점을 발견했다. 즉 청각피질에 도달한 많은 소리주파수 가운데 특정 주파수만을 선택적으로 받아들이도록 와우각에 신호를 보낸다는 의미다.
이 원리를 활용한다면 관심 있는 음성신호에만 주의를 집중하는 방법이 개발되지 않을까. 사람은 매우 시끄러운 환경에서도 관심 있는 사람의 목소리나 단어를 쉽게 찾아내지만, 현재의 음성인식 시스템은 이 일을 실현하기 어렵다. 그렇다면 주의가 집중되는 대상에 대한 데이터를 피드백에 의해 얻고, 이와 무관한 입력 음성신호는 무시하는 시스템을 만들면 문제가 해결된다. 실제로 인간의 청각 시스템을 모방해 잡음에 둔감한 음성인식시스템이 개발될 날이 멀지 않았다고 전문가들은 전망한다.
사람 귀가 2개인 이유
인간의 청각시스템을 모방한 또다른 음성인식시스템으로 스피커폰(speaker phone)이 있다. 잘 알다시피 사람의 귀는 2개다. 새삼스런 질문이지만 귀가 2개라서 편한 점은 무엇일까? 소리가 나는 방향을 쉽게 감지할 수 있다는 점이다.
소리가 오른쪽과 왼쪽 귀에 도달하는 시간에는 차이가 있다. 두뇌는 이 미묘한 시간차를 인식해 먼저 도달한 소리가 어느쪽 귀를 통과한 것인지 알아낸다. 만일 귀가 1개뿐이라면 어느 방향에서 나온 소리인지 인간이 감지할 수 없다. 물론 사람은 고개를 위와 아래로 움직이며 소리가 나는 방향을 보다 확실하게 파악할 수 있다.
최근 3개 이상의 마이크를 부착한 스피커폰이 개발되는 이유가 여기에 있다. 넓은 회의실에 둘러 앉아 스피커폰 한대를 통해 여러명이 상대와 통화하는 경우를 생각해보자. 만일 스피커폰에 마이크가 한대만 설치돼 있다면 마치 사람이 귀가 1개일 경우처럼 어느 위치에서 누가 얘기하는지 스피커폰이 감지하기 어려울 것이다. 3개 이상의 마이크는 각 방향에 위치한 사람의 음성 주파수를 시간의 간격을 두고 인식하기 때문에 이 문제가 해소된다.
이와 같은 공학적 응용이 훨씬 활발해진다면, 그리고 음성의 내용을 이해할 수 있는 인공지능이 개발된다면 미래 사회는 어떤 모습으로 변할까.
모든 기계에게 말로 명령하고, 키보드 없이 일상적인 언어로 문서를 작성하며 인터넷을 탐방하는 일이 가능해진다. 한 예로 VTR에 “내일 저녁 KAIST 방영을 녹화해” 라고 말하면 녹화가 이뤄진다. 의사가 일상적인 말로 처방하면 컴퓨터가 이를 인식해 실제 전문적인 처방전을 작성한다. 주가나 전화번호 등 각종 정보를 전화로 물으면, 컴퓨터 안내원이 곧바로 적절한 답을 일상 언어로 전해준다. 따라서 자동응답기의 안내문을 신경을 곤두세워 들으면서 전화기 다이알패드를 눌러야 하는 복잡함과 시간 낭비가 없어진다. 좀더 나아가서 음성인식시스템에 번역기의 원리를 통합시키면 한국어로 한 말이 자동으로 영어나 일본어로 통역돼 상대방에 전해질 수 있다.
청각칩의 효과
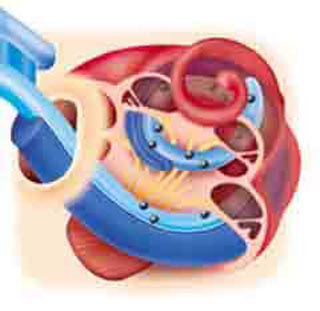
인간다운 청각시스템의 또다른 응용분야는 청각칩이다. 사실 많은 수의 청각장애인은 와우각이 제대로 기능을 발휘하지 않아 고통을 느끼고 있다. 그래서 와우각의 역할을 수행하는 청각칩을 실제 와우각 내에 이식하는 연구가 활발하게 진행되고 있다(그림 2).
청각칩은 크게 소리신호를 입력하는 외부부분, 그리고 이 신호를 뇌의 청각피질에 전달하는 내부부분으로 구성된다. 현재까지 개발된 청각칩은 3개월 정도의 적응기를 거쳐야 효과적인 음성인식이 가능하다. 물론 나이가 어릴수록 이 기간이 단축되며 최종 인식 능력도 우수하다. 최근의 연구결과에 따르면 청각칩을 통해 단음절의 경우 38%, 문장의 경우 72%를 인식할 수 있다.
인간다운 청각시스템은 인간이 기계를 보다 효율적으로 사용할 수 있게 만들고, 청각장애인에게 듣는 길을 열어 주는 등 인류 사회를 크게 발전시키고 있다. 만일 시각시스템, 추론시스템, 그리고 행동시스템과 결합하면 보다 완벽한 인간다운 시스템이 만들어 질 수 있을 것이다. 인간이 이들의 지원을 받으며 보다 윤택한 생활을 누리게 될 것은 자명하다.











