컴퓨터의 키보드를 두드리는 번거로움이 없이 말(음성)로써 컴퓨터에 명령을 내리고 역시 말로써 우리가 필요로 하는 정보를 컴퓨터로부터 받을 수는 없을까?
우리들은 생활의 대부분 시간에 언어, 즉 말을 사용한다. 또 우리들 중 많은 사람들이 컴퓨터 전문가가 아니더라도 상당한 시간을 컴퓨터를 사용하면서 보낸다. 때로는 컴퓨터를 사용하는 일이 말을 사용하는 일과 중복되기도 한다. 보통 사람들이 컴퓨터 사용시에 가장 많이 쓰는 워드프로세서 같은 것이 그 예다. 퍼스널 컴퓨터의 도스(DOS ) 명령어를 키보드를 이용해 쳐 넣고 실행하는 것도 어떻게 보면 컴퓨터가 알아 들을 수 있는 언어를 우리가 사용하고 있는 셈이다.
그런데 이 경우, 우리는 평소에 우리가 사용하는 한국어나 영어와 같은 자연언어가 아닌 특수한 인공 언어를 사용하며 컴퓨터와 대화하기 위해서는 이것을 열심히 배워야만 한다. 더군다나 컴퓨터와의 대화를 능숙하게 하기 위해서는 키보드를 자유롭게 이용할 수 있는 기술도 습득해야 한다.
언어학·컴퓨터과학의 전문지식과 기술 필요
여기서 우리는 한가지 의문을 가질 수 있다. 꼭 이래야만 하는 것인가? 우리는 모두 적어도 한 가지 자연언어, 즉 한국어에 능통하다. 이 한국어를 사용해 특별한 인공언어의 습득 없이도 자유롭게 컴퓨터를 사용할 수 있지 않을까? 또 키보드를 두드리는 번거로움이 없이, 일상 생활에서 대화하듯이 말(음성)로써 컴퓨터에 명령을 내리고 우리가 필요로 하는 정보를 역시 말로써 컴퓨터로부터 받을 수 있지 않을까?
이와 같은 일이 가능하려면 컴퓨터가 자연언어를 처리해 이해하고 생산해 낼 수 있어야 한다. 다시 말해 컴퓨터로 하여금 자연언어를 처리할 수 있도록 컴퓨터와 프로그램을 사람이 만들어야만 하는 것이다. 물론 이 일은 간단한 일이 아니며, 언어학 및 컴퓨터과학의 전문적 지식 및 기술이 필요하다.
실용적인 기계번역 시스템
이렇게 컴퓨터의 자연언어 처리와 관련된 여러 가지 사항을 전문적으로 연구하는 분야가 컴퓨터언어학이다. 그 세부 분야로서 기계번역(machine translation) 음성처리 자연언어처리(natural language processing, NLP) 코퍼스(corpus, 말뭉치) 언어학 등이 있다. 이제부터 컴퓨터의 세부 분야에서 연구하는 구체적 사항에 대해 알아보도록 하자.
앞에서 사람과 컴퓨터와의 대화 문제를 예로 들었지만, 사람과 사람 사이의 의사소통에서도 비슷한 문제가 있다. 그것은 우리가 외국어를 사용할 경우다. 현재 세계 공용어는 영어라 할 수 있다. 외교 무역 학술활동 등에서 영어의 사용이 필수적인데, 대부분의 한국인들에게 영어를 읽고 쓰는 일은 우리말을 사용하는 것에 비해 훨씬 힘들다. 더군다나 10여년 동안 영어를 공부하고도 외국인과의 대화가 꺼려지는 것이 현실이 아닌가? 이러한 상황에서 필요한 것이 외국어에 능통한 번역가와 통역자이며, 실제로 이들이 우리의 언어 생활에 상당히 중요한 역할을 하고 있다.
그러나 능숙한 번역가나 통역자를 길러내는 데에는 시간적 경제적으로 많은 비용이 들며, 오늘날 쏟아져 나오는 외국 서적을 신속히 번역하기는 어려운 일이다. 이러한 맥락에서 사람이 아닌 기계, 즉 컴퓨터에 의한 자동 번역의 필요성이 인식될 수 있으며, 이와 같은 문제를 다루는 기계번역은 컴퓨터언어학에서 중요한 분야다.
기계번역에 대한 구체적 생각은 2차 세계대전 당시 일본군의 암호를 해독하는 데 성공했던 미국의 학자들에 의해 처음으로 제기됐다. 그들은 언어를 암호 체계로 파악해 두 언어는 단순히 두개의 다른 암호 체계로서, 번역은 암호 체계를 파악하는 데 필요한 도구, 즉 두 언어의 사전과 그 대응관계를 밝힘으로써 가능하다고 봤다.
이러한 단순한 생각에서 출발했던 기계번역 연구는 별 성과를 거두지 못했었다. 언어체계에서 중요한 것은 단순한 단어가 아니라 통사(또는 문법) 구조이기 때문에 통사 구조를 소홀히 하는 기계번역 연구가 큰 실효를 보지 못했던 것이다. 약 10년 간의 공백기 후에, 1970년대로 들어오면서 기계번역 연구는 새로운 도약기를 맞이했는데, 이는 언어학을 통한 언어에 대한 좀더 깊은 이해와 컴퓨터 기술상의 발전 때문이었다.
현재까지 한정된 영역에서나마 실용적인 기계번역 시스템이 쓰이고 있다. 예를 들어, 영어와 불어를 공용어로 사용하는 캐나다에서 일기예보를 영불, 불영으로 번역하는 시스템은 거의 사람의 간섭 없이 성공적으로 번역을 수행한다. 현재 유럽의 EC에는 영국 프랑스 독일 등 12개국이 가입돼 있으며 9개 언어를 공식 언어로 사용하고 있는데, 이 9개의 어느 한 언어로부터 다른 언어로의 번역이 가능한 자동번역 시스템인 EUROTRA가 개발되고 있다.
일본에서도 일찍이 일영, 영일 등 기계번역 작업이 활발히 진행돼 왔고, 한국에서는 한영, 영한 기계번역을 중심으로 현재 연구개발 중이다. 실용적인 기계번역 시스템이란 반드시 완전한 자동 번역을 의미하지는 않으며, 사람이 최소한 간여해 경제적인 번역 결과를 얻는 것이라 할 때, 이미 어느 정도 실용적인 시스템이 나와 있다고 할 수 있다.

음성의 인식과 음성의 합성
한편 기계번역의 한 특수 분야로서 음성자동통역이 있다. 예를 들어 국제 전화로 외국인과 이야기할 때, 자동적으로 기계가 번역을 해 주는 시스템이다. 이것은 문서의 기계번역과 달리 음성의 인식 및 생성이라는 문제가 개입하는 더욱 어려운 분야이며 아직 실용적인 시스템은 없다. 이제 컴퓨터의 음성처리 분야에 대해 살펴 보자.
음성처리는 컴퓨터가 사람의 말을 알아 듣고, 사람의 소리를 내는 데 필수적으로 이해돼야 할 분야다. 이의 연구 응용을 위해서는 말소리의 과학인 음성학의 지식이 기반이 된다. 음성처리는 음성의 인식과 음성의 합성이라는 두 하위 분야로 세분된다. 이 중음성의 합성은 많이 이해돼 있고 실용적인 시스템도 많이 사용되고 있다.
음성 합성의 기본 원리는 소리를 구성하고 있는 음향학적 속성들을 적절히 배합하는 것이다. 예를 들어 모음마다 에너지가 모여 있는 주파수가 다르며, 자음들은 파열음 마찰음 비음 등에 따라 그 음향학적 속성이 다른데, 이들을 컴퓨터를 통해 적절히 배합하면, 사람의 소리에 가까운 소리가 나는 것이다. 외국에서의 응용의 예를 보면, 맹인들을 위해 책을 읽어 주는 기계가 있는가 하면, 전화번호를 자동응답해 주는 시스템까지 다양하다.
반면에 음성 인식은 상대적으로 연구 진척이 뒤진 분야이며, 실용적인 응용의 예도 드물다. 음성 인식이 어려운 이유는 발음에 개인차가 있고, 같은 소리라도 그 전후에 붙는 음에 따라 그 음향적 특성이 달라지며, 같은 사람이 같은 말을 해도 그 소리의 길이가 달라지기 때문이다. 따라서 이제까지 미국 및 일본에서 실제로 개발된 음성인식 시스템들은 화자의 수, 단어의 수, 발음의 속도, 담화의 주제 등에 제약을 가지고 있으며, 이런 요소들에 제약 없이 음성을 인식하는 시스템은 아직 연구개발 중이다.
통사적 파싱과 형태적 파싱
이제 자연언어처리(NLP) 분야에 대해 알아 보자. 앞에서 우리는 문서 및 음성을 통한 기계번역에 대해 언급했다. 이 과정에서 컴퓨터가 한 언어의 문장을 다른 언어의 문장으로 번역하기 위해서는 단어의 1대1 대응 이상이 필요함을 앞에서 지적했었다. 한 언어의 문장의 의미를 제대로 이해하고 이것을 다른 언어의 문장으로 대응시켜야 하는 것이다.
문장의 이해를 위해 필요한 첫번째 과정은 문장의 구조를 밝혀 내는 것이다. 예를 들어 영어의 'John likes Mary와 Mary likes John'의 두 문장에는 똑같은 단어들이 쓰였지만, 그 구조가 다름으로써 의미가 서로 다르다. 이와 같이 구조가 드러나 있지 않은 문자열(또는 단어의 연속체)에서 통사적(문법적) 구조를 찾아 내는 과정을 파싱(parsing)이라고 하며, 이것이 자연언어처리의 중요한 하위 분야다.
파싱은 기본적으로 단어가 등재돼 있는 사전과 문장의 구조에 관한 통사(문법) 규칙을 기반으로 수행된다. 파싱에는 위의 영어 예에서와 같이 단어들이 명확히 인식됐음을 전제로 문장의 통사 구조를 찾아내는 통사적 파싱이 있는가 하면, 단어 내의 더 작은 의미 단위인 형태소를 구분해 궁극적으로 단어의 구조를 밝혀 내는 형태적 파싱도 있다.
형태적 파싱은 영어와 같이 상대적으로 단어의 형태 변화가 단순한 언어에 비해 우리말과 같이 형태소가 발달된 언어의 파싱에 필수적인 단계다. 예를 들어 영어의 동사 walk가 실제 영어의 문장에서 쓰일 때에는 walk walking walked walks 등의 형태로만 쓰이므로 이것들 모두를 사전에 올릴 수 있고, 따라서 단어의 인식은 사전에 있는 형태와의 일치라는 단순한 작업이다.
그러나 우리말의 '걷다'에는 수많은 어미가 붙어 쓰일 수 있어(걸어 걷게 걷고 걷지 걸으니 걷니 걷다가 걸으면서 걷사오니 걸으십시오 걸어요 걸어라 걷자…) 이것들 모두를 사전에 올릴 수는 없다. 따라서 사전에는 기본형과 형태소만을 등재하고, 형태적 파싱을 통해 단어를 인식할 수 밖에 없다.
자연언어처리 분야에는 주어진 의미 표현에 대해 적절한 자연언어의 문장을 생성해내는 언어 생성의 하위 분야를 첨가하기도 하는데, 이것은 기계번역이나 이제 언급할 자연언어 이해와 함께 다루기도 한다.
자연언어이해(natural language understanding) 시스템을 알아보기 위해 다음과 같은 가상적 상황을 생각해 보자. 우선 컴퓨터에게 다음과 같은 사실을 말해 준다. (1) '철수는 소년이다' (2) '영희는 소녀다' (3) '모든 소년들이 로봇을 좋아한다' (4) '모든 소녀들이 로봇을 좋아하지 않는다'.
다음에 컴퓨터에게 다음과 같은 질문을 던진다. '철수와 영희중 누가 로봇을 좋아하는가?' 이때 우리가 기대하는 응답은 '철수가 로봇을 좋아한다'다. 이러한 상황이 가능하기 위해서 컴퓨터는 물론 주어진 문장들을 정확히 분석해 그 의미를 이해해야 하고, 또 주어진 사실을 토대로 새로운 사실을 추론할 수 있어야 하며, 그래야만 비로소 컴퓨터가 자연언어를 '이해'했다고 할 수 있다.
이것이 가능하기 위해서는 앞의 파싱 이외에도 의미를 어떻게 해석할 것인가, 지식을 어떻게 표시할 것인가, 또 주어진 지식으로부터 어떻게 새로운 사실을 추론해 낼 수 있는가 하는 점들의 연구가 필요하다. 이러한 것들은 인공지능(artificial intelligence)이라는 컴퓨터과학의 이름 하에 많은 연구가 이루어지는 분야다. 물론 앞의 가상적인 상황은 아주 간단한 예이지만 의학 공학 등의 전문적 지식에 관한 문답을 수행할 수 있는 실용적인 전문가 시스템도 동일한 원리에 기반을 두고 있다.
이제까지 언급했던 자연언어처리의 과정을 그림으로 표시하면 (그림1)과 같다.
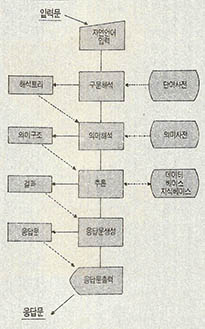
말뭉치를 이용한 텍스트 분석
한편, 지금까지 언급했던 컴퓨터언어학의 분야들, 즉 자연언어처리 전체, 그리고 기계번역과 음성처리까지도 인공지능의 하위분야로 파악된다. 그런데 인공지능 이외의 분야로서 컴퓨터언어학의 중요한 한 분야를 형성하는 것이 있다. 그것은 코퍼스(corpus)를 이용한 텍스트 분석이다.
코퍼스란 텍스트를 연어학적 분석을 위해 모아 놓은 것을 말하며, 말뭉치라고 번역하기도 한다. 텍스트는 책 신문 등 문자로 이루어진 것과 대화 연설의 녹음을 포함한 음성 텍스트를 모두 일컬을 수 있으나, 여기서는 지금까지 많이 연구돼 왔던 문자 텍스트의 코퍼스에 대해서만 알아본다.
최초의 컴퓨터 코퍼스는 1960년대에 미국의 브라운대학교에서 만든 것으로 약 1백만 단어로 구성돼 있다. 그 후 1980년대에는 2천만 단어 규모의 버밍햄 대학의 코퍼스가 구성됐으며, 현재는 1억 단어 규모의 코퍼스가 미국 및 영국에서 구성되는 중이다. 이러한 코퍼스를 이용해 단어의 빈도수 등 언어의 통계적 분석이 가능해지며, 단어의 쓰임에 대한 용례를 쉽게 탐색할 수 있음으로써 의미 분석 및 사전 편찬을 용이하게 해준다. 실제로 버밍햄대학의 코퍼스는 성공적인 COBUILD 사전을 만드는 밑천이 됐던 것이다.
컴퓨터를 이용한 통계적 분석으로써 전통적인 인문학의 연구도 새로운 전기를 마련했다. 실제로 저자를 모르는 중요 문서에 대한 어휘 통계적 분석으로 그 저자를 확인할 수 있었던 예도 있다. 이밖에도 현재 컴퓨터의 기술적 발전으로 가능하게 된 방대한 규모의 코퍼스를 이용해 언어 연구의 새로운 방향을 모색하려는 시도가 이루어지고 있다.
언어학과 컴퓨터과학의 협조하에 발전예상
지금까지 컴퓨터언어학의 여러 분야에 대해 간략히 살펴 봤다. 컴퓨터와 우리가 자유롭게 대화할 수 있는 이상적 상황을 만들기 위해 각 분야의 연구는 중요하다. 그러나 우리가 당장 워드프로세서를 쓰는 상황 하에서도 컴퓨터언어학의 연구 결과가 응용되고 있다. 대부분의 영어 워드프로세서, 그리고 일부 한국어의 워드프로세서에서 철자 검색 및 교정이 가능한데, 이는 (특히 우리말의 경우) 형태소 파싱이 선행돼야 한다. 영어의 경우 문법적 문체적으로 잘못 쓴 문장을 수정해 주는 문법교정 프로그램들도 등장했다(GRAMMATIK 등).
아직 초보적인 수준의 이러한 프로그램들이 글쓰는 이들의 필수품이 되기 위해 컴퓨터언어학의 여러 분야에 대한 더 많은 연구결과들이 필요할 것이다. 그리고 컴퓨터언어학은 언어학과 컴퓨터과학의 긴밀한 협조 아래서 앞으로 더욱 발전할 것이다.











