2탄에서 다룬 데이터들이 인공지능에 주어진다면? 사람과 소통할 수 있는 인식 기능을 가질 수 있습니다. 어떻게 인공지능이 인식하는지 살펴봅시다.

인공지능 기술은 이미 우리 생활 속 깊숙이 들어와 있습니다. 스마트폰에 노래 제목을 말하면 그 노래를 들려주고 궁금한 사물을 찍으면 이름을 알려주죠. 이때 인공지능이 가장 먼저 할 일은 입력된 데이터를 ‘인식’ 하는 겁니다.
인공지능 인식 장치는 사람의 감각 기관?
우리는 눈으로 다양한 사물을 알아보고 귀로 소리를 듣습니다. 인공지능 역시 카메라를 이용한 이미지 인식 기술로 사물을 인식하고 마이크 등을 이용한 음성 인식 기술로 소리를 인식합니다. 예를 들어 이미지 인식에서는 인공지능이 수많은 이미지 데이터를 학습해 공통된 특징을 찾아냅니다. 그리고 특징을 이용해 새로 입력된 그림이 어떤 그림인지 알아냅니다. 아래의 예시로 인공지능이 어떻게 사물을 인식하는지 알아볼까요?

위 사진에서 캔과 페트병을 분류하려면 먼저 캔과 페트병의 모양과 색깔, 라벨 등에 대한 데이터를 알아둬야 합니다. 캔은 대부분 원기둥 모양이라 윗면과 밑면이 원 모양으로 같고 넓이도 같습니다. 그리고 색깔이 비교적 다양하죠. 반면 페트병은 위쪽으로 갈수록 입구가 좁아지며 밑면과 윗면의 넓이가 다르고, 투명합니다. 이처럼 인공지능 역시 다양한 물체의 이미지를 보고, 나름의 기준을 세워 캔과 페트병을 구별할 기준을 찾습니다.
그리고 새로운 이미지가 들어오면 찾아둔 기준으로 캔인지 페트병인지 구별하죠. 한 예로 오른쪽 그림의 물체는 윗면과 밑면의 크기가 같고, 밑면이 원 모양이며 색깔이 다양해 캔이라고 판단합니다.

소리나 문자 인식 역시 인공지능이 데이터를 스스로 학습해 판단할 수 있는 기준을 세우고, 이를 바탕으로 인식합니다. 이때 인공지능이 정확히 인식하게 만들려면 적절한 훈련 데이터를 충분한 양으로 입력해 학습시켜야 합니다. 데이터의 양이 적거나 잘못된 데이터를 학습시키면 잘못된 판단을 내릴 수 있습니다.
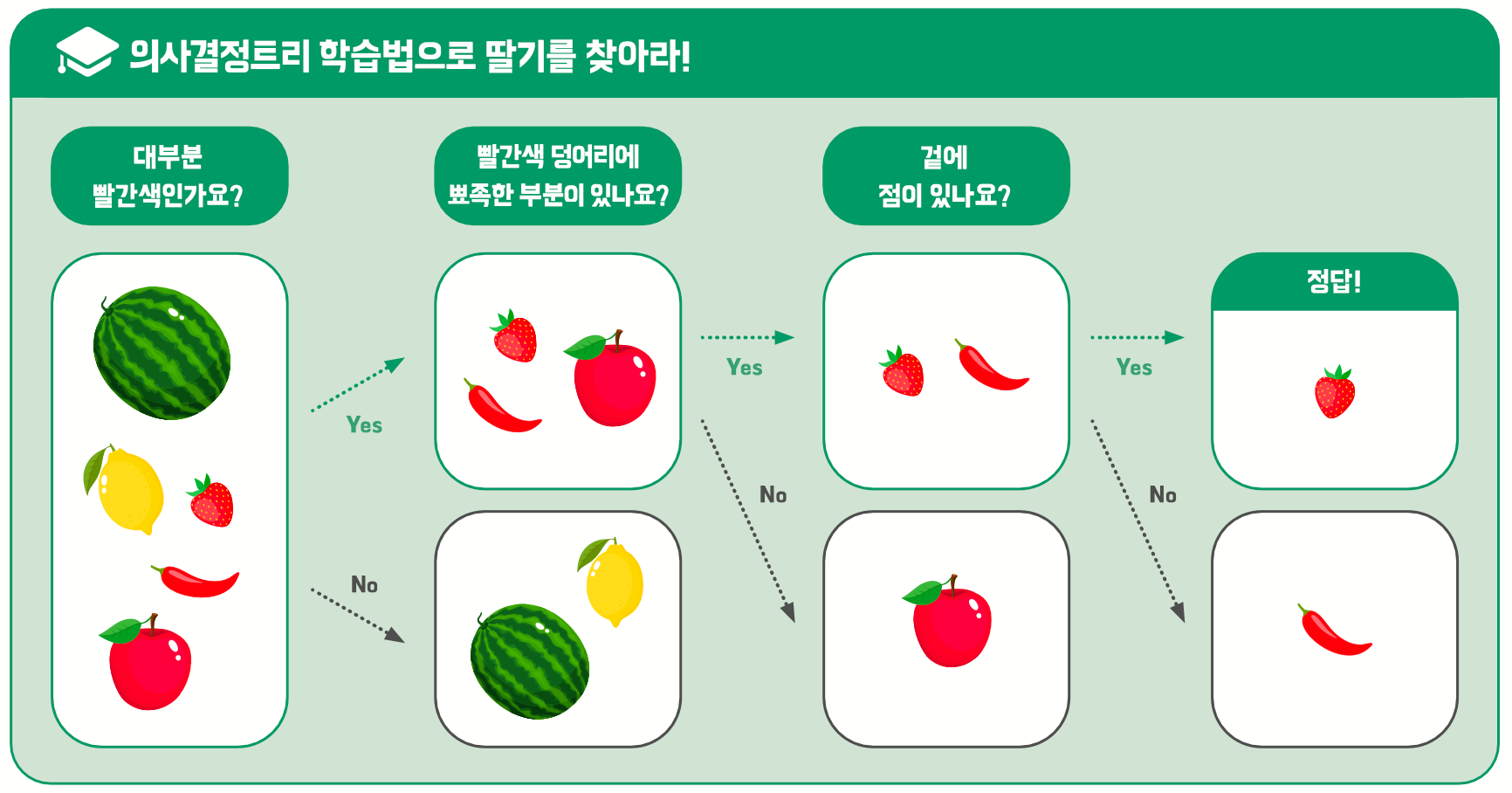
복잡한 문제에는 ‘의사결정트리 학습법’
캔과 페트병과 달리 간단히 나눌 수 없는 복잡한 물체의 이미지가 주어진다면, 인공지능이 풀어낼 수 있을까요? 이때는 기준을 체계적으로 표현할 방법을 찾아 사용합니다. 가장 간단한 방법 중 하나로 ‘의사결정트리 학습법’이 있습니다. 주어진 데이터를 기준에 따라 분류하는 방법으로, 이 과정에서 그려지는 그림이 마치 나무(tree)의 모습과 비슷해 의사결정트리라고 부릅니다.
이 방법을 사용하면 수많은 데이터가 있어도 주어진 기준으로 분류해 인식할 수 있습니다. 하지만 기준이 많으면 많을수록 시간이 오래 걸립니다. 그래서 더 빠르고 정확하게 판단할 수 있는 기준을 계속해서 학습하는 방향으로 인공지능을 만들고 있습니다.
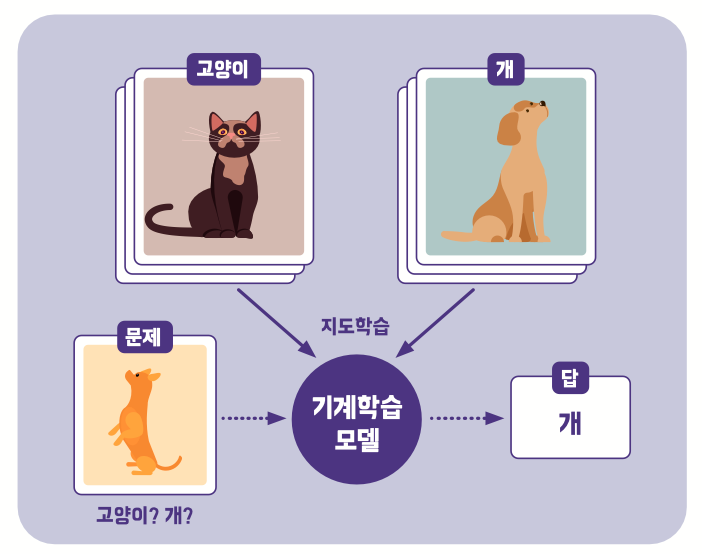
인식을 위한 두 가지 학습 방법
인공지능이 기준을 찾는 방법에는 지도 학습과 비지도 학습 등 두 가지 방법이 있습니다. 지도 학습은 아래 그림처럼 고양이, 개 등 정답이 쓰여있는 데이터를 주고 분류할 수 있는 기준을 스스로 학습하도록 하는 방법입니다. 이를 통해 만들어진 ‘기계학습 모델’에 새로운 데이터가 들어가면, 스스로 학습한 기준을 이용해 분류하고 인식합니다.
두 번째로 비지도 학습은 정답이 없는 데이터를 스스로 파악해 규칙성을 찾도록 하는 방법입니다. 예를 들어 좌표평면 위에 빨간 점과 파란 점이 마구 찍혀있다고 가정합시다. 이때 점의 색과 위치를 인공지능에 학습시키면, 스스로 점을 나눌 기준을 찾습니다. 그럼 같은 색을 갖는 점끼리 묶거나 점이 어느 사분면에 있는지에 따라 분류할 수 있죠. 이처럼 비슷한 특성을 갖는 데이터를 묶는 과정을 ‘군집화’라고 하며 이 역시 인공지능 데이터 인식 과정에 적용됩니다.
실제로 현재 인공지능은 카메라, 마이크, 압력 센서, 온도 센서 등을 통해 우리의 시각과 청각, 촉각, 후각, 미각과 유사한 데이터를 학습합니다. 이를 바탕으로 인공지능은 사람의 감정을 파악하는 얼굴 인식 기술이나 스마트 농장에서 작물을 수확하는 기계, 암 등의 질환을 진단하는 등 다양한 용도로 사용되고 있습니다.