A-Yo! 사람의 귀를 대신하는 음성 인식 AI는 이미 여러 분야에서 활용되고 있어. 지금부터 내 친구들의 활약상을 소개할게!


내 손발을 대신하는 AI스피커
음성 인식 AI 하면 가장 먼저 떠오르는 것이 AI스피커 아닐까? AI스피커는 질문에 답하거나 명령어를 이해하고 기능을 실행해. 카카오의 AI스피커 카카오미니를 예로 들어 볼게. 사용자가 “헤이 카카오”라고 말하면 음성 인식 AI가 반응하지. 그런 뒤 “오늘 날씨가 어때?”라고 물어보면 사용자가 있는 지역의 기온과 구름 양, 미세먼지 농도까지 답해 줘. 날씨 외에도 “잠잘 때 듣기 좋은 노래 들려줘”라고 말하면 적절한 노래를 선곡해서 들려주는 등 다양한 능력을 갖고 있지!

눈을 보고 말해요
드라마에서 경찰 수사관이 피해자의 진술을 컴퓨터로 받아적는 장면 본 적 있을 거야. 그런데 음성 인식 기술이 이 과정을 대신할 수 있어. 음성 인식 AI가 진술 내용을 음성으로 기록하면서 실시간으로 문서로 변환해 주거든. 그러는 동안 수사관은 피해자와 눈을 맞추면서 대화에 집중할 수 있어. 이 기술은 국내 AI 전문 기업 셀바스AI가 개발했지.
음성 인식 AI랑 영어 공부하자!
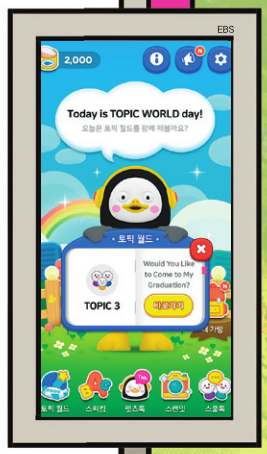
학교에서 이 화면 본 친구들 있지? 바로 음성 인식 AI로 만든 영어 학습 프로그램 ‘AI펭톡’이야. 한국전자통신연구원(ETRI)과 EBS가 공동 개발한 AI펭톡은 초등학생 2만여 명이 말한 약 5000시간 분량의 음성 데이터를 학습했어. 특히 어른과 어린이는 발음하는 방식이 달라서 주요 사용자인 어린이의 목소리를 데이터로 사용했지. 그래서 어린이의 음성 인식률이 90% 이상에 달해. AI펭톡은 전국 초등학교에서 사용하고 있어. AI 외국어 공부 시스템을 공교육에 도입한 건 세계 최초라고 해!
자막, 일일이 달 필요 없다
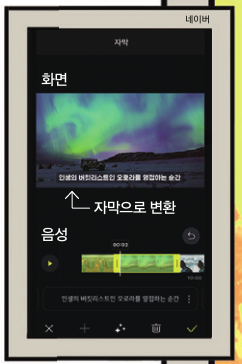
듣지 못하는 청각장애인에게는 TV나 동영상을 볼 때 자막이 아주 중요해. 그래서 일부 방송 채널은 자막 서비스를 제공하고 있지. 그런데 음성 인식 기술을 활용하면 사람이 일일이 자막을 달지 않아도 자동으로 자막이 생성돼. 네이버의 모바일 라이브 스트리밍 서비스 ‘프리즘 라이브 스튜디오’는 네이버에서 개발한 음성 인식 AI를 활용해서 동영상의 오디오를 분석하고 이를 텍스트로 변환하지.
사람은 청각 기관으로 AI는 삼각함수로!
음성 인식 AI가 다양한 일을 하는 건 알겠는데 귀도 없는 기계가 어떻게 사람이 하는 말을 인식하는지 이해가 안 된다고? 맞아, 나는 사람과 똑같은 방법으로 말을 인식할 수는 없어. 그래서 특별한 과정을 거쳐야 해!
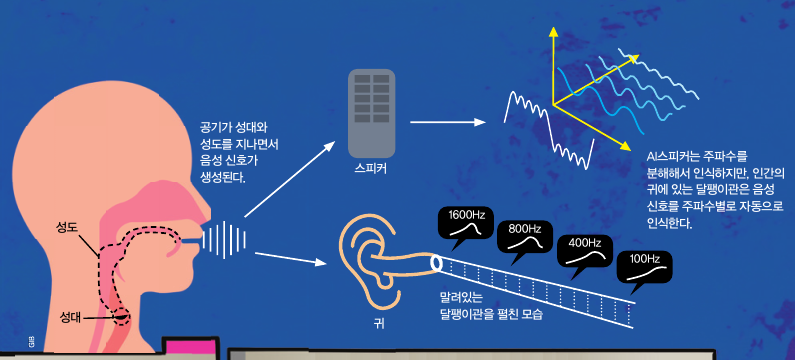
AI의 음성 인식 비결을 이해하기 위해 먼저 음성 신호가 무엇인지부터 알아보겠습니다. 사람이 말을 하면 허파에서 공기가 나와 성대를 떨리게 합니다. 1초에 100회 이상 성대가 떨려서 진동을 일으키고 그 진동이 성도를 지나면서 공명을 일으킵니다. 이렇게 만들어진 음파는 파동의 한 종류로, 주기성을 지니는 음성 신호입니다.
목소리를 낼 때 1초 동안 성대가 몇 회 진동하냐에 따라 목소리의 높낮이가 달라집니다. 성대가 더 많이 진동할수록 높은 목소리(고음)가 만들어집니다. 일반적으로 여성의 목소리가 남성의 목소리보다 더 높은 이유는 남성은 목소리를 낼 때 1초 동안 성대가 100~150회 진동하고 여성은 200~250회 진동하기 때문입니다. 이렇게 1초 동안 소리나 전기 신호가 진동한 횟수를 주파수 또는 진동수라고 합니다. 주파수를 나타내는 단위는 Hz(헤르츠)입니다. 이 단위를 이용해 남성과 여성의 목소리의 기본 주파수*를 각각 100~150Hz와 200~250Hz로 간단하게 표현할 수 있습니다.
그런데 이렇게 나온 음성 신호는 기본 주파수 하나가 아니라 기본 주파수의 배수로 이뤄진 다양한 주파수를 가진 신호의 합으로 이뤄져 있습니다. 이는 음성뿐 아니라 자연에 존재하는 모든 신호, 즉 ‘아날로그 신호’의 특징입니다. 우리의 귀는 이 음성 신호를 주파수 대역별로 인식해 말을 이해하지만, 음성 인식 AI가 음성 신호를 이해하려면 특별한 과정이 필요합니다.
예를 들어 친구가 ‘수학’이라는 단어를 말하면 ‘수학’이라는 음성 신호에 포함된 다양한 주파수의 신호들을 귓속 달팽이관에 있는 신경세포들이 자동으로 인식해 그 말을 바로 이해할 수 있습니다. 하지만 AI가 ‘수학’이라는 음성 신호를 인식하려면 어떤 주파수를 가진 신호들이 합쳐져 있는지를 일일이 분석해서 처리해야 합니다.
이때 음성 신호와 비슷한 모양을 가진 함수를 사용해 아날로그 신호를 다양한 주파수를 가진 여러 개의 신호로 분해할 수 있습니다. 청각 기관이 주파수를 인식하듯, 컴퓨터는 이 과정을 통해 음성 신호가 어떤 신호인지를 인식하는 것이죠. 이때 사용하는 수학 함수가 뭔지 감이 오나요? 주파수처럼 구불구불한 함수, 바로 ‘삼각함수’입니다! 삼각함수는 어떻게 컴퓨터가 음성을 인식하는 데 도움을 주는지 계속 살펴볼까요?

음성 인식 AI를 향한 도전의 역사
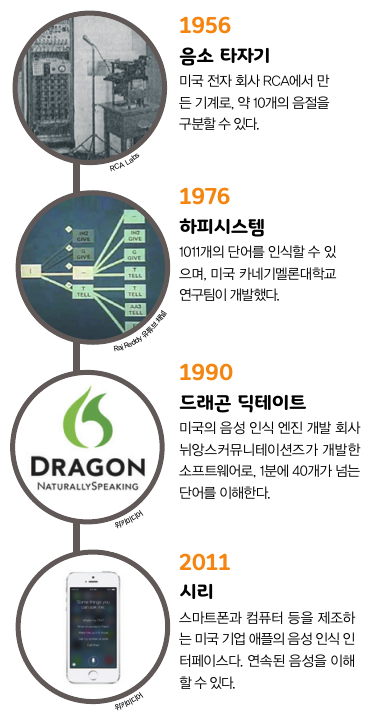
음성은 사람의 의사소통 수단 중 가장 편리한 수단입니다. 문자를 몰라도 말은 할 수 있죠. 그래서 오래전부터 음성으로 기계를 조작하는 음성 인식 기술을 개발하려는 시도가 이어졌습니다. 2000년대 초반만 해도 음성 인식 기술의 성능이 별로 좋지 않아서 몇 개의 단어나 문장을 인식하는 데 그쳤습니다. 그런데 딥러닝을 비롯한 AI 기술의 발달로 음성 데이터를 빠르게 학습할 수 있게 되면서 음성 인식 기술의 성능이 비약적으로 향상됐습니다. 음성 인식 기술은 현재 다양한 AI와 결합해 사용되고 있죠.
음성 인식 기술의 변천사를 알아볼까요?
* 보충설명
목소리의 기본 주파수
: 허파에서 나온 공기가 1초에 성대를 진동시키는 횟수











