유니코드는 문자 하나에 부여되는 데이터값을 모두 2바이트, 즉 16비트로 통일해 세계 각국의 문자를 모두 표현하는 국제 표준이다. 여기에서 우리의 한글은 단일 문자로는 가장 넓은 영역을 차지하고 있다.
1980년대 들어 전세계적으로 컴퓨터의 보급이 확산되고, 특히 비영어권인 아시아 국가에서 컴퓨터 이용도가 높아짐에 따라 문자 코드의 국제적 표준화에 대한 관심이 점차 높아지기 시작했다.
대문자와 소문자, 숫자, 기호를 합해 1백개 미만의 기호를 사용하는 영문자 문화권에서는 1백28자만을 나타낼 수 있는 아스키 코드로도 별 불편이 없지만, 사용해야 할 글자가 수천에서 수만에 이르는 우리나라나 중국 일본 등 동양권 국가에서는 이러한 1바이트 코드체계로는 문자를 수용하지 못한다.
이에 따라 단일한 부호 체계로 전세계에서 사용되는 문자와 기호를 모두 표현할 수 있는 시스템의 필요성이 제기되면서 여럿의 국제 단체에서 연구를 진행해왔다. 유니코드는 바로 이같은 배경에서 IBM 마이크로소프트 애플 같은 미국 굴지의 소프트웨어회사들이 힘을 합쳐 세계의 모든 문자를 하나의 부호 체계로 나타낼 수 있게끔 한 업계 표준이다.
2바이트 코드로 세계의 어느 문자든지 나타낼 수 있게 해 주는 유니코드를 운영체제가 지원하면 그 운영체제 아래에서 돌아가는 모든 소프트웨어들도 손쉽게 여러 나라의 문자를 지원할 수 있다. 새로운 소프트웨어를 만들 때마다 각 나라용 판을 따로 만들어야 하는 번거로움과, 거기에 들어가는 비용을 줄일 수 있다는 이점 때문에 세계 굴지의 소프트웨어 회사들이 유니코드 컨소시엄에 가입해 이 코드를 정착시키기 위해 노력하고 있다.
나랏 말씀이 영어와 달라
요즘 사용되는 다양한 컴퓨터 시스템에서의 언어 지원은 다음 네 가지 형태로 구분될 수 있다. 첫째는 영문 전용 시스템이고, 둘째는 영어가 아닌 다른 하나의 언어(예: 그리스어)만을 지원하는 시스템이다. 하지만 대부분은 두번째보다는 두개 이상, 그러나 제한된 수의 언어를 지원하는 시스템을 선택하고 있다. 이같은 세번째의 언어 지원 형태는 대개 그 나랏말과 추가로 영문을 지원하는데, 우리 나라에서 사용되는 KSC 5601도 여기에 속한다고 할 수 있다. 네번째로는 어느 언어라도 지원할 수 있는 시스템으로, 유니코드가 바로 이러한 언어 지원 형태의 예다.
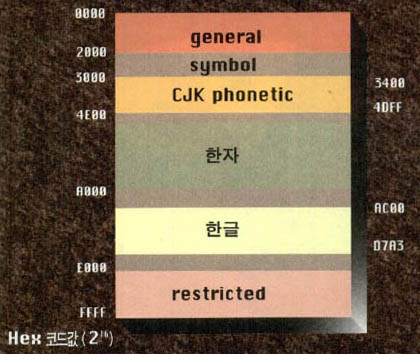
컴퓨터에 입력된 데이터는 애초 숫자와 영문 대문자 수준에서 처리됐는데, 7비트 아스키(ASCII)의 등장으로 영문 소문자의 처리가 가능해지긴 했지만 영어와 불어, 혹은 독어를 동시에 나타낼 수 없다는 문제를 안고 있었다. 그래서 등장한 것이 8비트를 사용하는 ISO 8859라는 것이다. 그러나 이 역시 한글이나 한자를 나타내는데는 역부족이었다. 결국 동양문자를 나타내기 위해서는 더블바이트의 사용이 불가피해진 것이다.
그러나 더블바이트 코드의 사용은 새로운 문제를 불러 일으켰다. 즉 더블바이트는 KS나 일본의 JIS 코드가 한글이나 한자를 나타내는데는 두 바이트, 영문자를 나타내는데는 한 바이트를 사용하기 때문에 데이터의 랜덤 엑세스(random access)가 불가능하다는 것이었다.
예를 들어 ASCII를 사용하는 경우 어떤 데이터 항목의 다섯번째 글자를 찾기 위해서는 데이터 시작하는 곳에서부터 다섯번째 바이트에 위치한 곳에서 원하는 글자를 찾을 수 있지만, KS나 JIS 코드의 경우에는 앞에서부터 한 글자씩 읽지 않는 한 다섯번째 글자의 위치를 장담할 수 없다. 앞의 네 글자가 한글과 영문 혹은 숫자가 섞여 있다면 최소 네 바이트부터 최고 여덟 바이트를 차지할 수 있기 때문이다. 유니코드는 영문 알파벳 한글자나 한자 한글자를 모두 2바이트로 처리해 이러한 문제들을 해결하고 있다.
더 많은 영역 확보 위해 치열한 로비
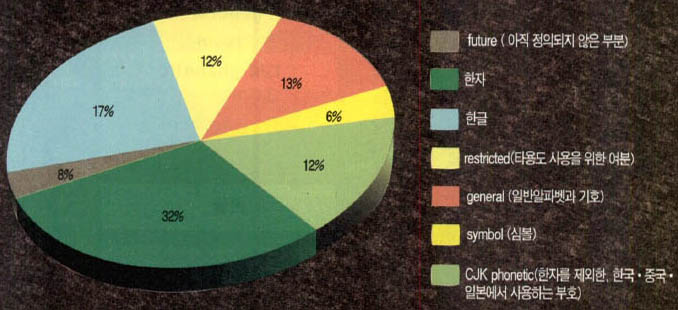
유니코드 진영은 1991년에 비슷한 작업을 진행 중이던 국제표준화기구(ISO)의 문자 코드 전문위원회를 장악하는데 성공해 1992년 발표된 국제문자표준인 ISO 10646을 유니코드와 동일한 것으로 만들었다. 그런데 10646의 첫번째 판에는 1만1천1백72자의 현대 한글 중 4천5백16자가 빠진데다, 순서도 뒤죽박죽이 되어서 들어가 있다. 92년 여름 서울에서 있었던 ISO 문자코드전문위원회에서 우리나라 대표단은 한글 1만1천1백72자를 모두 국제 표준에 포함시키기 위해 노력했으나 그때까지 국내 표준도 2천3백50자만을 지원하고 있었고 전체 코드 영역의 4분의 1을 우리에게 내주기 싫어하는 중국 일본 등의 반대로 어중간한 절충안을 받아들였다.
그러다가 ISO가 작년부터 10646의 개정 작업에 들어가면서 우리나라의 문자코드 전문위원회는 다시 한번 한 영역에 모든 한글을 가나다 순으로 배열하자는 안을 부활시킬 생각을 했다. 이와 함께 마침 윈도95와 윈도NT에서의 한글 지원 문제로 고심하고 있던 마이크로소프트사의 도움을 얻어 ISO의 문자코드 전문위원회에 큰 영향력을 행사하는 유니코드 진영을 상대로 로비를 시작했다.
우리나라 소프트웨어 산업의 명실상부한 대표주자격인 한글과 컴퓨터사도 독보적인 한글처리 기술이라는 기득권을 포기해가면서까지 우리나라 사용자들이 어떤 소프트웨어를 사용하든지 제대로 된 한글을 사용할 수 있게 하기 위해 유니코드 컨소시엄에 가입해 적극적인 활동을 벌였다. 이러한 노력이 열매를 맺어 1995년 3월 미국의 실리콘밸리에서 열린 유니코드 기술 위원회에서는 우리 안을 받아들이기로 했고, 1996년 초에 출간될 유니코드 2.0에 이 내용이 반영될 예정이다.
이어서 1995년 4월 제네바에서 있었던 ISO의 문자코드 전문위원회 실무자 회의에서도 중국 등의 거센 반대가 있었으나 유니코드 진영의 도움으로 우리 안이 통과됐다. 같은 해 8월에 있었던 서면투표를 통해 이 안이 최종 확정됐으며 국제표준부호계에서의 한글지원 방식이 통일됐다.
윈도NT같이 이미 유니코드를 지원하는 운영체제 말고도(지금 나와 있는 윈도NT는 유니코드 1.0을 지원한다) 앞으로 나올 운영체제들이 유니코드를 기본 코드로 지원할 것이 유력시된다. 결국 2-3년 후에 우리가 사용하는 컴퓨터에서 입력되는 한글은 유니코드 형태로 처리되고 저장될 가능성이 상당히 큰 것이다.

유니코드는 완성형이 아니다
현재 유니코드와 ISO 10646 개정안에 포함돼 있는 한글 코드가 ‘완성형’ 이라고 보는 일부에서는 이 코드에 문제가 있는 것처럼 생각하고 있는 것 같다. 기존 한글 코드 논쟁에서 ‘완성형’과 ‘조합형’은 상당히 달랐던 두 코드 체계를 구분해서 부를 수 있게 해주는 역할을 훌륭히 수행해냈다.
그러나 보기에 따라서는 ‘2바이트 조합형코드’는 1만1천1백72자의 조합 가능한 모든 현대 한글을 자소 분리가 쉬운 형태로 배열해 놓은 ‘완성형 코드’라고도 할 수 있다. 진정한 의미에서 조합형 코드라 불릴 수 있는 것은 ISO 10646에 이미 포함돼 있는 초성 중성 종성 자모 조합에 의한 한글 코드다. ‘정음형’ 혹은 ‘첫가끝’ 이라고도 부르는 이 코드는 초 중 종성에 해당하는 각 자모를 2바이트로 나타내서 이 자모들의 조합을 통해 음절을 표현한다. 따라서 옛 한글 등 현대 한글 맞춤법에 맞지 않는 모든 글자를 표현할 수 있다.
반면 우리가 매일 사용하는 현대 한글의 음절 하나를 나타내기 위해서는 받침이 없는 경우 4 바이트, 받침이 있는 경우 6 바이트를 사용하기 때문에 저장 효율이 떨어진다. 또한 한 음절에 해당하는 데이터의 양이 가변적이므로 데이터 처리가 까다롭다는 단점을 가지고 있다.
이러한 이유로 인해 대부분의 컴퓨터 전문가와 사용자들은 2바이트 조합형코드를 선호했고, 이 코드를 국제 표준 하에서 가장 정확하게 표현할 수 있는 1만1천1백72자 한글 코드를 1992년 ISO에 제안하게 된 것이다.
이 제안에는 현대 한글을 제외한 모든 한글(옛 한글이나 맞춤법에 어긋나는 한글 자모의 모든 조합)을 표현하는 방법으로 2백40개의 자모 코드가 들어 있다. 이 코드는 이미 1992년 서울 회의에서 채택된 바 있다.
유니코드와 ISO 10646에는 1만1천1백72자 음절 코드와, 2백40 자모의 조합을 이용하는 것 두 가지의 한글 표현 방식이 지원되는 것이다. 당분간은 개발업체의 사정에 따라 두 방식 중 하나만 지원하는 경우가 많을 것 같다.
유니코드의 1만1천1백72자 한글 코드 체계는 조합 가능한 모든 한글에 코드 영역을 할당해줘 간단한 계산에 의해 한 음절을 구성하는 자소들을 분리해낼 수 있다는 점에서 기존의 2바이트 조합형 한글 코드와 같다. 또 기존의 2바이트 조합형 한글 코드 3분의 1 정도의 코드 영역을 사용한다는 점에서 효율성이 높은 코드 체계다.
참고로 다음은 음절의 코드 값과 음절을 구성하는 자모의 관계를 나타낸 공식이다. 이 공식을 응용하면 음절의 코드 값에서 쉽게 자모를 분리해 낼 수 있다. (s 는 음절, x 는 초성, y 는 중성, z 는 종성, c1 은 총 중성 수 (21), 그리고 c2 는 총 종성 수(28)를 나타낸다).
s=x×c1×c2+y×c2+z
유니코드 역사
85-87년 : 제록스와 애플 내부에서 연구시작. 87년 말 제록스와 애플이 만나 유니코드 초안 작성.
88년 : 제록스와 애플, 단일화된 한자세트 국제표준기구(ISO) 시연.
89-90년 : 유니코드 준비그룹 발족. 애플 메타포 RLG 선제록스(이상 창립멤버) 마이크로소프트 IBM 앨더스(Aldus) 넥스트(이상 90년 참가)
91년 : 상반기 유니코드 법인 설립(Unicode Inc.). 한자통합을 위해 한국 중국 일본 연합연구그룹 소집. ISO10646과 유니코드 통합원칙 결의. 유니코드 1.0판 출판.
92년 : ISO 10646 통과.
유니코드 컨소시엄의 구성
정회원(1996년 1월 현재)
AT&TGIS, 애플 DEC에코로지컬 링귀스틱스(Ecological Linguistics) 휴렛팩커드 IBM 저스트시스템스(Justsystems) 로터스 마이크로소프트 넥스트 노벨 리서치라이브러리그룹(Research Libraries Group) 실리콘그래픽스 사이베이스 탈리젠트(Taligent) 유니시스 한글과 컴퓨터(총 17개사)
준회원
어도브 컴팩다이나랩(Dynalab) 오라클 스웨덴왕립도서관 제록스 로이터스(Reuters) 등 총 31개사
· 정회원은 이사의 자격을 획득할 수 있으며, 유니코드기술위원회에 참가해 표결권을 행사함.
· 기술적인 문제를 포함해 유니코드에 관한 전반적인 방향 결정은 유니코드기술위원회에서 담당함.