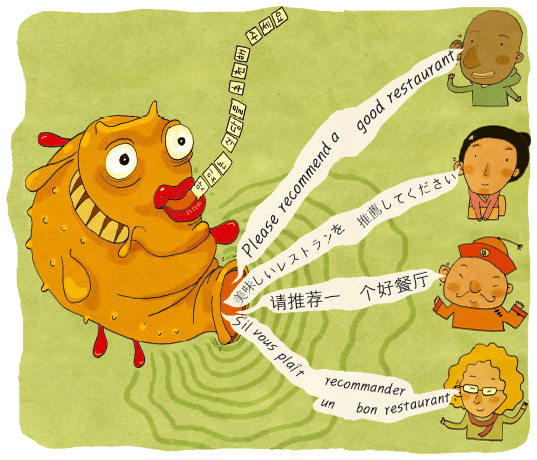
동명의 영화로도 만들어진 영국 SF작가 더글라스 아담스의 소설 ‘우주를 여행하는 히치하이커를 위한 안내서’에는 바벨피쉬라는 외계생물이 나온다. 이 기괴한 물고기는 언어 중추에서 나오는 신호를 먹고 소화시켜 다른 사람이 이해할 수 있는 신호로 바꿔 배설한다. 소설속에서 어쩌다 우주여행에 나서게 된 주인공은 바벨피쉬를 귀 속에 집어넣은 뒤 외계인과 자유롭게 대화할 수 있게 된다. 얼마나 편리한가. 외국어 공부에 시달리는 사람들이 보면 귀가 솔깃할 것이다. 그런데 현실에도 바벨피쉬가 있다. 바로 자동번역기술이다.


[야후의 자동번역으로 ‘과학동아는 국내 최고의 과학잡지다’ 를 영어로 번역해 봤다.]
현실에서 볼 수 있는 바벨피쉬는 미국의 포털 사이트 야후가 제공하는 자동번역 서비스의 이름이다. 기계번역이라고도 부르는 자동번역
은 컴퓨터를 이용해 한 언어를 다른 언어로 번역해 준다. 구글도 수십 개나 되는 언어를 서로 번역해 주는 서비스를 제공하고 있고, 우리나라에서도 한일, 일한 번역기를 중심으로 자동번역 서비스가 널리 쓰이고 있다. 요즘 인터넷에서 어떤 화젯거리에 대한 해외 네티즌 반응을 신속하게 알 수 있는 것은 외국어를 잘 하는 능력자뿐만 아니라 이런 자동번역기술의 덕택이기도 하다.
컴퓨터로 언어를 번역한다는 생각은 이미 1940년대에 나왔다. 미국의 수학자인 워렌 위버가 1947년 자동번역이라는 가능성을 제시했고, 몇몇 과학자들이 합류해 1948년 천공카드를 이용한 자동번역 실험을 처음 시도했다. 초기 이론은 단순했다.
사전을 찾아 단어를 목적 언어의 단어로 바꾸고, 문법 특성을 고려해 어순을 조절해주는 정도였다. 1954년에는 미국 조지타운대와 IBM이 공동으로 러시아어를 영어로 번역하는 기술을 개발했다. 당시에 쓰인 컴퓨터는 1952년에 출시된 ‘IBM701’, 프로그래밍은 CPU에 2진수 코드로 명령어를 입력하는 기계어로 했다. 문법 규칙이 6개, 어휘가 250개로 단출한 시스템이었다. 이 정도 문법 규칙과 어휘로는 일반적인 내용을 번역하기에 매우 부족했다. 연구팀은 유기화학에 관한 아주 짧은 문장 수십 개와 평범한 내용의 좀 더 긴 문장 몇 개를 러시아어에서 영어로 번역한 결과물을 일반에 공개했다.
이 실험 결과는 자동번역의 미래에 대한 낙관적인 견해를 널리 퍼뜨렸다. 그러나 실제 발전은 신통치 않았다. 지지부진하던 자동번역기술은 1980년대 들어서야 다시 활성화됐다. 그 동안 단순히 사전으로 단어를 대체하고 문법에 맞게 재구성하는 것만으로는 부족하며 언어를 이해해야 한다는 인식이 퍼졌다. 그래서 발달한 분야가 컴퓨터로 언어를 분석해 의미를 파악하는 ‘자연언어처리’ 기술이다.
배는 ship? pear? stomach?
구글 검색창에 ‘구글 번역’을 넣으면 번역 서비스 페이지로 갈 수 있다. 거기서 ‘배가 먹고 싶어’를 영어로 번역해 보자. ‘want to take the boat’라는 결과가 나온다. 해석하면 ‘배를 타고 싶어’로, 명백한 오역이다. ‘옛날에 백조 한 마리가 살았습니다’를 넣으면 ‘Once upon a time there lived 100,000,000,000,001’라는 황당한 결과가 나온다. 이처럼 사람이 보기에 어처구니없는 실수가 나오는 것은 문장의 의미를 파악하는 과정이 생각보다 복잡하기 때문이다.
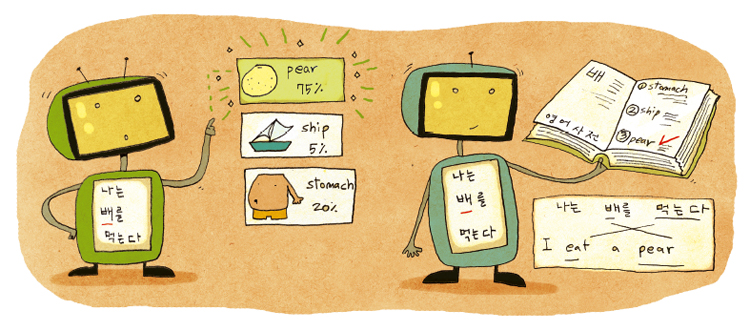
문장의 의미를 알아내는 첫 단계는 형태소 분석이다. 입력한 문장을 해체해 기본 단위로 나누고 다시 조합해 가며 단어를 찾는다. ‘아버지가’에서 ‘아버지’라는 명사와 ‘가’라는 조사를 찾아내는 것이다. 그리고 단어를 다른 언어로 번역해야 하는데, 동음이의어일 경우 이 작업이 쉽지 않다.
우리말 ‘배’에는 뜻이 여러 가지가 있다. 자주 쓰는 뜻만 해도 물 위에 떠서 다니는 운송수단, 동물의 특정 부위 명칭, 과일, 곱절 등이 떠오른다. 자동번역이 문장을 정확히 번역하려면 배의 여러 가지 뜻 중에서 올바른 뜻이 무엇인지 알아내야한다. 우리는 문맥을 통해 ‘배’가 ‘타다’라는 동사와 함께 쓰였을 때는 ‘ship’일 가능성이 높다는 사실을 알아낸다. 컴퓨터는 ‘타다’라는 단어의 뜻을 사람처럼 이해하지 못하므로 따로 정보를 줘야 한다.
그런다고 해도 한계가 있다. 우선 고유명사와 일반명사가 똑같을 경우다. ‘유리가 밥을 먹는다’라는 문장을 생각해 보자. 가장 흔한 ‘유리’의 뜻은 ‘투명하고 단단해 창문이나 병에 많이 쓰이는 물질’이다. 이 뜻만 가지고 보면 ‘밥을 먹는다’라는 부분과 짝 지을 수 없다. 유리를 ‘glass’로 ‘밥을 먹는다’를 ‘eat rice’로 번역하면 영 어색한 문장이 돼 버리는 것이다. 실제로 구글 번역에 넣어 보면 ‘The glass eats rice’라고 나온다. 하지만 한국인은 이 문장을 보고 ‘유리’가 물질이 아니라 사람 이름이라고 유추할 수 있다. ‘배가 크다’, ‘배가 갈색이다’와 같이 ship이나 pear 둘 다 될 수 있는 문장이라면 어떨까. 이런 문장이 단독으로 있으면 사람도 뜻을 가늠하기 어렵다. 앞뒤 문장이나 전체 글의 맥락을 알아야만 의미를 정확히 알 수 있는데, 컴퓨터는 아직 사람에 비해 이런 맥락을 파악하는 능력이 현저히 떨어진다.
컴퓨터는 문장이 실제 세계와 갖는 관계도 알 수 없다. ‘나는 짜장면’이라는 문장은 그대로 해석하자면 ‘나는 짜장면이다’가 되지만, 실생활에서는 거의 그렇게 쓰지 않는다. 중국음식점에서 주문할 때 ‘나는 짜장면을 먹겠다’라는 뜻으로 쓰는 게 보통이다. ‘뒤에 차 온다’ 같은 문장도 마찬가지다. 단순히 뒤에서 차가 오고 있다고 말하는 게 아니라, 뒤에서 차가 오니 조심하거나 피하라는 게 진짜 뜻이다.
우리말은 형태소 분석이 어려운 편에 속한다. 존댓말 같은 어미 변화가 많고, 조사도 종류가 많으며, 띄어쓰기도 일관적이지 않다. 또한 주어나 목적어를 생략하거나 순서를 바꾸는 바람에 문맥으로 파악해야 하는 경우가 많다.

문법대로 vs 통계대로
구글 번역의 우스꽝스런 사례가 아니더라도, 한영 번역은 아직은 정확도가 낮은 편이다. SK텔레콤에서 자동번역기술을 개발하는 황영숙 박사는 “영어는 우리말과 거리가 먼 언어라 자동번역이 가장 어려운 편에 속한다”고 설명했다. 영한번역보다도 형태소 분석이 어려운 한영 번역이 더 정확도가 떨어진다.
자동번역은 두 언어가 얼마나 비슷한지에 따라 정확도가 달라진다. 유럽에서 쓰는 비슷한 언어끼리는 자동번역이 꽤 유용하다. 우리말과 가장 가까운 언어는 일본어다. 오래 전부터 한일, 일한 자동번역기술을 개발해 온 씨에스엘아이(CSLi)의 번역 소프트웨어 ‘이지트랜스’는 정확도가 90%를 넘는다. 네이버와 다음에서 제공하는 번역 서비스가 바로 이지트랜스다.
그렇다면 이지트랜스나 구글 번역 같은 자동번역 소프트웨어는 어떤 방식으로 작동할까. 요즘 많이 쓰는 자동번역기술에는 크게 규칙기반과 통계기반 방법이 있다. 이지트랜스는 전자고, 구글 번역은 후자다.
규칙기반 방법은 사람이 직접 번역할 때 쓰는 것과 같은 언어학적 규칙에 따라 번역한다. 사람처럼 사전과 문법책을 보고 번역하는 셈이다. 먼저 형태소 석을 한 뒤 단어를 찾아 뜻과 품사를 결정하고 다시 배열한다. ‘너 밥 먹었니?’와 ‘밥 먹었니, 너?’처럼 단어의 순서가 바뀌어도 같은 뜻으로 이해하고 번역하기 위해서다. 단어를 번역할 때는 일반 사전이 아니라 특별히 만든 번역 사전을 쓴다. 단어의 뜻뿐만 아니라 자주 함께 쓰이는 단어를 모아서 관계 정보를 구축해 놓은 사전이다. 가구, 건축, 색상, 노래 등 단어가 어떤 분야와 관련돼 있다는 정보인 ‘의미 속성’이 들어 있다. ‘배’가 ‘타다’, ‘만들다’, ‘띄우다’ 같은 단어와 함께 쓰였을 때는 ‘ship’으로 해석해야 한다고 알려 주는 식이다. 씨에스엘아이의 김동필 이사는 “한 단어에 뜻이 많을수록 번역이 어렵기 때문에 번역 사전이 중요하다”고 말했다. 번역한 단어는 목표 언어의 문법에 따라 재배열해야 한다. 우리말과 일어처럼 언어학적으로 비슷한 언어 쌍은 상대적으로 쉽지만, 영어처럼 어순이 다르면 정확도가 떨어진다.
규칙기반 방법은 통계기반 방법에 비해 속도가 빠르다는 게 장점이다. 규칙을 잘 갖춰 놓으면 괜찮은 성능을 낼 수 있어 자동번역기술에 널리 쓰이고 있다. 그러나 규칙을 구축하는 데 비용이 많이 들고, 언어별로 분석기를 따로따로 만들어야 한다는 게 단점이다.

[씨에스엘아이의 통역비서 앱 화면. 언어를 지정한 뒤 마이크에 대고 말을 하면 자동으로 번역한 뒤 해당 언어로 음성이 나온다]
통계기반 방법은 형태소 분석으로 단어를 구분한 뒤 문법은 통계로 해결한다. 똑같은 뜻인데 다른 두 언어로 쓰인 수많은 언어 쌍을 바탕으로 통계를 내는 것이다. 최근 가장 많이 연구하는 방법이다. 통계 정보에 따라 앞뒤 단어의 연결 관계나 어순을 여러 가지 경우별로 확률을 계산하면 가능성이 가장 큰 번역문을 만들 수 있다. 번역이 정확하려면 통계를 낼 수 있는 언어 쌍이 많아야 한다. 황 박사는 “구글 번역은 영어-중국어 번역에 1억 쌍 정도의 문장을 활용한다”고 말했다.
통계기반 방법은 속도가 느리지만, 언어별로 사전을 만들 필요가 없다. 예만 풍부하면 다양한 언어를 서로 번역할 수 있다. 유엔(UN) 외교문서 같은 자료는 같은 내용이 다양한 언어로 쓰여 있어 좋은 예문이 된다. 예문이 부족한 두 언어를 번역할 때는 중역을 하기도 한다. 예를 들어 한국어와 벵골어에 대한 자료가 부족하면 일단 한국어를 영어로 번역한 뒤 다시 벵골어로 번역하는 식이다.
다만 통계기반 방법은 데이터베이스가 정확하지 않으면 잘못된 결과를 낼 수가 있다. 구글 번역에 ‘아이폰은 안드로이드폰보다 좋다’를 넣고 영어로 번역해 보자. ‘Android better than iPhone’이 나온다. 정 반대의 뜻이다. 구글은 번역 결과를 조작하지 않았다고 주장하고 있으니, 데이터베이스가 문제라는 뜻이다. 만약 모바일OS인 안드로이드의 팬들이 일부러 잘못된 예문을 마구 올린다면 이런 결과가 나올 수도 있다.
맥락인식으로 더 정확하게
자동번역기술이 아직 완전하지 않아 어처구니없는 오역이 많은 건 사실이다. 그런데 자동번역의 장점을 ‘오역이 오역이라는 것을 분명히 알 수 있다’는 데서 찾는 사람도 있다. 보통 자동번역으로 생기는 오역은 읽는 사람이 바로 알아볼 수 있다. 하지만 사람 번역가는 오역을 하더라도 최종 문장은 말이 되게끔 쓰기 때문에 원문과 대조하지 않고서는 오역인지 모르고 지나가기 쉽다. 또한 자동번역은 번역자의 개성을 타지 않아 일관적인 결과물을 낸다.
그러면 자동번역은 어디에 활용할 수 있을까. 자동번역이 한계를 뚜렷하게 드러내는 분야는 문학이다.
별을 노래하는 마음으로
모든 죽어가는 것을 사랑해야지
그리고 나한테 주어진 길을
걸어가야겠다
오늘밤에도 별이 바람에 스치운다
- 윤동주의 ‘서시’ 중



[고 노무현 전 대통령이 해외 출장 중 통역사를 통해 대화를 나누고 있는 모습. 자동통번역 기술이 완벽해지면 언어를 몰라도 외국인과 자유롭게 이야기할 수 있을 것이다.]
문학 작품은 은유가 많아 자동번역으로는 정확히 번역하기도 특유의 분위기를 살리기도 어렵다. 특히 ‘스치운다’처럼 변형된 표현을 전혀 이해하지 못하고 ‘seuchiunda’로 그냥 읽어버린 것을 볼 수 있다.
반대로 특허 문서 번역에서는 이미 자동번역이 널리 쓰이고 있다. 특허 문서에 쓰이는 전문용어는 일반 단어에 비해 중의성이 낮다. 애매한 단어나 생략이 적고 비교적 정형적인 문장이 많이 쓰여 번역 성능을 높이기 쉽다. 우리나라 특허청도 2005년 한국전자통신연구원(ETRI)이 개발한 한영 자동번역시스템을 채용해 쓰고 있다.
여행이나 사업을 목적으로 쓸 수 있는 자동통역시스템도 나오고 있다. 자동통역은 자동번역에 음성인식과 음성합성 기술을 더해야 한다. 씨에스엘아이는 지난해 이지트랜스로 한국어를 일본어, 영어, 중국어로 통역할 수 있는 스마트폰용 앱 ‘통역비서’를 내놨다. 김동필 이사는 “음성인식의 한계를 극복하기 위해 회화체 문장분석기를 추가했다”고 설명했다. 예를 들어 사용자가 ‘여덟 시까지 찾아뵙겠습니다’라고 말했다고 하자. 우리말 발음 때문에 음성인식으로는 ‘여덟’이 ‘여덜’로 인식된다. 그래서 ‘시’와 ‘찾아뵙겠습니다’라는 단어로 맥락을 파악해 시간, 즉 숫자임을 알아내 ‘여덟’로 인식하는 것이다. 우리말과 일본어 통역은 95% 정도의 정확도가 나온다.
방송 자막 자동번역도 앞으로 유망한 분야다. 외국에서 우리나라 방송을 볼 때 자동으로 현지 언어로 번역된 자막이 나온다면 문화교류를 더욱 확산시킬 수 있다. 방송에서 많이 쓰는 구어체, 사투리, 신조어, 불완전한 문장 때문에 생기는 오역을 극복해야 한다는 문제는 남아 있다.
맥락을 인식해 번역에 이용하는 기술도 개발 중이다. 웹페이지에 글과 함께 실린 사진의 태그, 위치정보와 같은 메타 정보를 이용하면 번역에 도움이 된다. 달랑 ‘배’라고 한 글자만 있으면 무슨 뜻인지 알 수 없지만, 과일인 배 사진이 함께 있다면 알 수 있는 것과 같다. 사람처럼 맥락을 파악할 수 있는 기술이 발달한다면 자동통번역은 글로벌 시대의 유용한 도구가 될 것이다. 그때쯤 되면 굳이 외국어를 공부해야 할까 고민하게 될지도 모른다.











