87년 KS한글코드가 제정될 당시 조합형 여론이 우세했다. 그런데 국제표준규격과의 통일을 내세운 통신론자들에 의해 2바이트 완성형으로 확정됐다. 그로부터 한글코드논쟁은 끊이지 않았는데…
4년마다 한번씩 온 세계를 떠들썩하게 만드는 월드컵 축구의 열기는 우리나라에도 예외는 아니어서 대회 기간동안 신문을 펼쳐도 텔레비전을 켜도 온통 그 보도 뿐이다. 아마 축구를 좋아하지 않더라도 지난해에 열린 로마 월드컵에 출전한 선수 이름 몇몇 정도는 아직도 기억하는 사람이 많을 것이다.
로마 월드컵 출전 선수 가운데 컴퓨터 관계자들 사이에서 유명한 선수로 독일의 푈러가 있다. 이 선수가 컴퓨터를 잘 만지는 사람도 아니고 마라도나 같은 불세출의 스타도 아닌데 이런 영광을 누리는 이유는 순전히 부모를 잘 만난 덕이라고 볼 수 있다. 이름에 들어 있는 '푈'자가 이 선수를 컴퓨터계의 스타로 만든 것이다.
아이러니컬하게도 이 글자는 KS규격을 따내지 못한 불량품이다. 글자에도 KS가 있느냐고 놀라는 독자가 있을 것이다. 볼펜 한자루에도 여러가지 KS규격이 적용되는데, 하물며 더 복잡한 컴퓨터분야에 KS규격이 없을 리가 없다. 이 가운데 하나가 컴퓨터에서 쓰이는 한글 코드에 대한 규격을 정해 놓은 것으로, 여기에 따르면 컴퓨터에서는 지정된 한글 2천3백50자만 사용하도록 되어 있다. 이 2천3백50자에 '푈'자는 포함되어 있지 않으니 이 글자는 써서는 안되는 불량품인 것이다.
신문사나 인쇄소의 전산사식기도 이 KS규격에 맞춘 것이므로 '푈'자에 대해서는 무방비 상태였는데 난데없이 이상한 이름을 가진 독일 사람이 나타나 비상이 걸렸고, '푈'자만 적당히 손으로 만들어 끼워 넣는 해프닝이 벌어졌다. 속사정을 아는 사람들은 말쑥한 글자들 사이에서 유독 그 글자만 모양이 이상한 이유를 알고 있으니, 신문을 볼 때마다 '푈러 푈러' 외우지 않을 수가 없었다.

문제점 더많은 확장시안
이제는 사라진 옛글자를 제외하면 표현 가능한 한글의 총 글자 수는 1만1천1백72자다. 이중에서 모든 글자가 다 쓰이는 것은 아니어서 불과 1천자 남짓의 글자들이 99% 이상의 출현빈도를 보인다. 그래서 KS에 규정된 2천3백50자 정도면 대부분의 사람들에게 전혀 문제가 없다는 정부쪽의 주장도 일리는 있다. 그러나 그 어느 누구도 언어는 끊임없이 생겨나고 소멸하고 변화하는 것이라는 점에 반대하지 못할 것이다. 지금까지는 단 한번도 쓰이지 않았던 글자가 당장 1년 후에 쓰이지 말라는 보장이 없으며, 그것은 표준 코드가 제정된지 불과 몇년만에 현실로 드러나고 있다.
현재의 KS 한글 코드(KSC5601 2바이트 완성형 코드)가 제정된 것은 지난 87년의 일이다. 당시의 상황은 컴퓨터 업체마다 서로 다른 방식으로 한글을 처리했기 때문에 자료를 공유하기 힘들었으며, 이에 따른 컴퓨터 사용자들의 불만이 많았다. 이러한 상황에서 KS 한글 코드가 한글 코드의 통일에 기여한 바는 적지 않다. 그러나 통일은 좋지만 과연 그 방향이 올바른 것인가에 대한 반론이 끊임없이 제기돼 왔으며, 길고 긴 코드 논쟁은 아직까지도 계속되고 있다.
결국 정부도 현행 KS 코드의 문제점을 인정하지 않을 수가 없었는지 지난 4월 표준 한글 코드의 확장 시안을 발표했다. 이 안은 각계의 의견 수렴 과정을 거쳐 93년부터 시행될 예정이라고 한다. 그러나 이 확장안도 기존의 체계를 그대로 유지하면서 글자를 추가하는 방식으로 구성돼 있기 때문에, 새로운 문제점을 더 많이 만들어 냈다. 가장 큰 문제점은 개인용 컴퓨터(PC)에 그대로 적용하기가 사실상 불가능한 구조라는 점이다. 그래서 PC에서는 변칙적인 방법으로 구현할 수밖에 없는데, 이렇게 되면 표준이라는 이름이 무색하게 대형 컴퓨터와 PC 사이에서 코드 변환없이 자료를 교환하는 것이 불가능하며, PC간에도 경우에 따라서는 자료의 교환이 불가능해진다. 게다가 기존에 보급된 한글 카드와 소프트웨어를 교체해야만 하기 때문에, 이러한 막대한 부담을 감수하면서까지 문제점 많은 체계를 유지할 필요가 있는지 심각한 의문을 남기고 있다. 심지어는 이 확장안을 시행하느니 지금 그대로 두는 것이 더 낫다는 의견도 적지않게 나오는 지경이다.
왜 완성형인가?
그렇다면 왜 하필이면 글자수를 한정하는 완성형이라는 방식이 한글 코드의 표준으로 채택되었는지 그 이유를 살펴 보아야 할 것이다. KS 한글 코드가 제정될 무렵인 87년 상황은, 비록 여러가지 코드가 난립하는 양상은 보였지만 서서히 상용 조합형이라는 코드로 자연스러운 통일이 이루어지고 있던 중이었으며, 조합형을 포함한 몇개의 시안을 두고 업계의 의견을 물어본 결과 역시 조합형을 채택하자는 쪽이 더 많았다. 이처럼 국내 상황은 조합형을 표준으로 하자는 쪽으로 흐르고 있었음에도 불구하고 완성형이 채택된 이유는 국제 규격 때문이었다.
공업 기술 분야의 각종 국제 표준 규격을 제정하는 기구인 ISO(국제표준기구)에서 제정한 여러 규격 가운데, 컴퓨터의 문자 코드에 관한 ISO 2022라는 것이 있다. 현재 우리 나라의 KS 코드는 이 규정에 따라 제정됐으며, 이 규정을 따랐을 때 우리 나라에서 쓸 수 있는 총 문자 수는 8천자 남짓이다. 이 8천자의 한정된 영역에 한글 한자 기호 등을 함께 넣다 보니 한글에는 2천3백50자의 공간만 할당된 것이다.
정부 쪽에서는 국제 표준의 준수라는 이유 외에도 현행 KS 한글 코드가 완성형이라는 방식을 채택한 이유를 몇가지 더 들고 있지만, 결국은 지엽적인 면에 불과하며, 가장 큰 이유는 역시 국제 규격 때문이다.
그렇다면 국제 규격을 지킴으로 해서 우리가 얻는 이득은 무엇일까. 여기에 대해 그동안 정부쪽의 관련 부처 관계자가 공청회 강연이나 신문 기고 등을 통해서 밝힌 바에 따르면 다음과 같이 요약할 수 있다. 첫째 우리가 제작한 소프트웨어를 외국에 쉽게 수출할 수 있다. 둘째 외국의 발전된 소프트웨어 기술을 쉽게 받아들일 수 있다. 셋째 국제규격을 지키지 않았을 때 발생할 소지가 있는 국제 통상 마찰을 피한다.
전 세계의 컴퓨터에서 쓰이는 모든 코드 체계를 하나의 틀에 담을 수만 있다면 하나의 소프트웨어를 개발해서 수정없이 여러 나라에서 사용하는 것이 가능해진다. 지금은 각 나라마다 컴퓨터 내부에서 제각기 다른 방식으로 문자를 표현하기 때문에 어느 한 언어에 맞게 수정하는 작업이 대단히 어렵게 되어 있다.
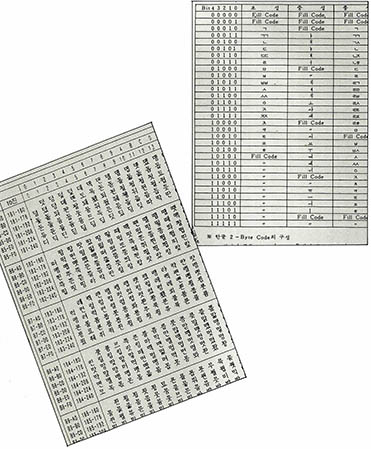
국제표준도 유동적이다
결국 컴퓨터의 문자 코드에 국제 표준을 제정하려는 뜻은 정보의 교환이라는 측면도 있지만, 더 크게는 각 나라의 문자 체계에 따른 소프트웨어의 변환 작업에 들어가는 부담을 줄이자는 배경이 깔려 있다. 여기에는 두가지 측면이 있는데, 긍정적인 면은 스스로 개발할 능력은 없고, 그렇다고 안 쓸 수도 없는 소프트웨어에서 자국어를 쉽게 사용할 수 있다는 점이다. 간단히 말해서 한글 문제의 걱정 없이 외국의 소프트웨어를 사용할 수 있게 되는 것이다.
그러나 부정적인 측면으로는 우리나라와 같이 소프트웨어 기술력이 뒤떨어진 나라에서는 선진 외국의 소프트웨어가 한결 손쉽게 침투할 수 있는 여건이 조성된다는 점이다. 소프트웨어 기술력이 떨어지는 상태에서 국제 표준을 따른다고 해서 기술력이 저절로 발전하는 것도 아니고, 가뜩이나 다른 과학 기술 분야와 마찬가지로 기술 자립도가 떨어지는 소프트웨어 분야에서 시장을 잠식당할 위험이 높다.
그리고 한가지 더 중요하게 짚고 넘어가야 할 문제는 현재의 국제 표준이라는 것도 방향이 일정하지 않고 유동적이라는 점이다. 현행 완성형 코드 제정의 근거가 된 ISO 2022 규정도 이제는 한물간 것으로 치부되고 있으며, 미국 유수의 소프트웨어 개발 회사를 주축으로 한 유니코드(Unicode)라는 연합체가 새로운 구심으로 떠 오르고 있다. 이 연합체에서는 유니코드라는 코드 체계로 전 세계의 컴퓨터를 통일하려는 움직임을 보이고 있으며, 유니코드와 호환성을 갖는 코드 체계를 ISO 규격으로 채택시킬 가능성이 높아졌다.
만약 이와 같은 새로운 코드가 국제 표준으로 채택된다면 국내 KS 코드도 그에 맞도록 바뀔 전망인데, 우리나라에서 사용할 한글 코드가 외국의 동향에 따라 이리 바뀌고 저리 바뀌는 현상은 결코 바람직스럽지 못하다.
현재의 표준 KS 코드에 문제점이 있다는 것은 정부쪽도 인정하는 사실이다. 어차피 기존에 보급된 하드웨어와 소프트웨어를 교체해야만 한다면 그에 들어가는 부담은 어떠한 한글 코드가 표준이 되든 마찬가지며, 백지 상태에서 다시 출발해야 한다. 이 새로운 출발은 국제 표준이나 컴퓨터가 아닌, 한글이라는 관점에서 시작되어야 한다. 한글은 단순한 기호가 아닌 우리의 문화이기 때문이다. 한글 문화를 발전시켜 후손에게 물려주는 것은 우리의 의무다.
한글 코드변환프로그램「카멜레온」 어떤 데이터도 자유롭게 쓸 수 있다
컴퓨터를 사용하면서 한글문제로 고민하는 사람이 의외로 많다. 그중 컴퓨터마다 한글코드가 서로 달라 데이터의 호환성이 없기 때문에 골탕을 먹는 경우가 더러 있다. A사의 컴퓨터에서 작성한 한글데이터가 B사의 컴퓨터에는 표현되지 않는 것이다.
이때 한글코드변환프로그램인 '카멜레온'을 이용하면 이 문제는 간단하게 해결된다. KS완성형코드를 비롯 삼보KSSM조합형 삼보TG 조합형 삼성조합형 금성조합형 청계천7비트완성형 대우7비트완성형 옴니7비트완성형 등 11가지 코드가 자유롭게 변환되는 것이다. 코드를 변환하는데 걸리는 시간은 파일 하나를 복사(copy)하는 시간과 비슷하다.
이 프로그램을 개발한 김재원씨(35·한보컴퓨터 개발부장)는 "완성형 컴퓨터를 쓰는 동생이 조합형 컴퓨터에서 그 데이터를 이용할 수 없어 쩔쩔매는 것을 보고 프로그램을 개발하게 됐다"고 개발동기를 말한다. 이 프로그램은 국내에서 많이 쓰이는 디베이스 로터스 등의 데이터 코드변환에도 바로 이용될 수 있다. 워드프로세서의 경우 제품마다 파일 구조가 달라 일단 텍스트모드(text mode)로 변환시킨 다음 카멜레온 프로그램은 돌려야 한다.
7비트 청계천한글 같은 한자가 없는 코드에서는 한자부분이 한글로 변환된다.
89년 3월 첫선을 보인 카멜레온 프로그램은 네차례 버전업을 걸쳐 현재는 카멜레온Ⅲ 1.2버전이 발표돼 있다.
대표적인 공개소프트웨어인 이 프로그램을 구하려면 케텔이나 PC서브 등 통신망에 들어가면 쉽게 얻을 수 있다. 또 도깨비 Ⅲ 디스켓에 들어 있으므로 이 프로그램을 구입하면 카멜레온까지 덤으로 구할 수 있다.
"한글코드문제가 해결되지 않는 한 카멜레온을 이용하는 사람은 늘어날 것입니다. 카멜레온을 이용하는 사람은 늘어날 것입니다. 카멜레온은 어떤 코드로 작성된 데이터라도 다른 컴퓨터에서 불편없이 쓸 수 있도록 도와주는 프로그램이기 때문입니다. 그러나 한글 코드가 하나로 통일돼 더이상 카멜레온이 필요없는 날이 오기를 바랍니다."