대기 오염도를 예측하기 위해 사용했던 측정값과 수학 모형 모두 항상 정확하지는 않습니다. 우리나라의 약 500곳에서 측정한 오염 물질은 통계 처리를 거치지만 완벽하게 오차를 없앴다고 볼 수 없습니다. 또 나비에-스토크스 방정식을 바탕으로 만든 예보 모형도 어디까지나 근사해를 얻는 방식이니 오차가 있을 수밖에 없죠. 하지만 가만히 두고 볼 수학자들이 아닙니다! 수학에는 예보 모형의 정확도를 높일 수 있는 ‘자료 동화’가 있거든요.
자료 동화란 모든 관측자료를 활용해 예보 모형에 들어갈 초기자료를 실제 대기에 가깝게 만드는 과정을 말합니다. 아무리 좋은 모형도 바로 몇 시간 뒤는 잘 예측하지만, 시간이 지나면 지날수록 오차가 커집니다. 자료 동화는 이런 예보 오차를 줄이기 위한 안전장치인 셈입니다.
자료 동화의 핵심은 ‘베이즈 정리’로, 과거에 어떤 사건이 일어난 확률과 현재 상황을 알면 앞으로 일어날 사건의 확률을 구할 수 있다는 수학 이론입니다. 어떻게 베이즈 정리로 자료의 정확도를 높이냐고요? 예보 모형은 나비에-스토크스 방정식으로 이뤄져 있고, 이 방정식은 각종 측정자료를 바탕으로 한 변수들로 구성됩니다. 간단히 예를 들면, 예보모형을 이용해 얻은 값(C)이 정확할 확률이 70%, 실제 측정한 값(O)이 정확할 확률이 30%라고 한다면 다음 식으로 계산해 새로운 데이터 Cnew를 얻습니다.
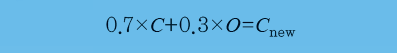
이 값을 다시 나비에-스토크스 방정식의 변수에 대입해 예보 모형의 정확도를 높이는 거지요. 마찬가지로 방정식에 필요한 상수, 계수 값도 조정해 실제와 조금 더 가까운 예측을 할 수 있습니다.
이 과정을 끊임없이 반복하면 오차를 바로잡을 수 있는 겁니다.
자료 동화가 측정값의 오차를 줄여주는 것인만큼 대기오염의 원인을 밝히고 대책을 세우는
데도 쓰입니다. 2019년 송창근 UNIST 도시환경공학부 교수와 박록진 서울대학교 지구환경과학
부 교수 공동연구팀은 우리나라의 초미세먼지 농도를 줄이는 방법에 대한 논문을 발표했습니다.
2016년 5~6월 국립환경과학원과 미국항공우주국(NASA)이 진행한 초미세먼지 측정 결과에 자
료 동화를 활용해서 초미세먼지의 주범을 알아낸 것이죠.
그 결과 우리나라에서 배출하는 암모니아를 가장 먼저 줄이는 것이 효과적인 방법임을 밝혔습니
다. 여기서 말하는 암모니아는 가축을 키우거나 거름이나 비료를 사용하는 농업에서 인위적으로
발생합니다. 그 다음으로는 중국 산둥 지방의 산업시설에서 발생하는 이산화황과 우리나라에서
배출되는 자동차의 배기가스 또는 연료를 태울 때나오는 질소산화물을 줄여야 한다고 나왔죠.